В предишните си блогове направихме обосновка защо имате нужда от отказ от база данни и обяснихме как работи механизмът за превключване при отказ. Споделям това, в случай че имате въпроси защо трябва да настроите механизъм за преодоляване на срив за вашата MySQL база данни. Ако го направите, моля, прочетете предишните ни публикации в блога.
Как да настроите автоматично превключване при отказ
Предимството при използването на MySQL или MariaDB за автоматично управление на вашия отказ е, че има налични инструменти, които можете да използвате и внедрите във вашата среда. От такива с отворен код до решения от корпоративен клас. Повечето инструменти не само са с възможност за отказване, има и други функции като превключване, наблюдение и разширени функции, които могат да предложат повече възможности за управление на вашия клъстер от база данни MySQL. По-долу ще разгледаме най-често срещаните, които можете да използвате.
Използване на MHA (Master High Availability)
Взехме тази тема с MHA с нейните най-често срещани проблеми и как да ги коригираме. Ние също така сравнихме MHA с MRM или MaxScale.
Настройването с MHA за висока наличност може да не е лесно, но е ефикасно за използване и гъвкаво, тъй като има регулируеми параметри, които можете да дефинирате, за да персонализирате своето превключване при отказ. MHA е тестван и използван. Но с напредването на технологиите MHA изостава, тъй като не поддържа GTID за MariaDB и не налага никакви актуализации през последните 2 или 3 години.
Като стартирате скрипта masterha_manager,
masterha_manager --conf=/etc/app1.cnfКъдето извадката /etc/app1.cnf трябва да изглежда по следния начин,
[server default]
user=cmon
password=pass
ssh_user=root
# working directory on the manager
manager_workdir=/var/log/masterha/app1
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=node1
candidate_master=1
[server2]
hostname=node2
candidate_master=1
[server3]
hostname=node3
no_master=1Параметри като no_master и kandidat_master ще бъдат от решаващо значение, тъй като задавате в белия списък желаните възли да бъдат ваш целеви главен и възли, които не искате да бъдете главен.
След като настроите, сте готови да имате отказ за вашата MySQL база данни в случай, че възникне неизправност на основния или главния. Скриптът masterha_manager управлява отказоустойчивостта (автоматично или ръчно), взема решения за това кога и къде да се превключва и управлява възстановяването на подчинен по време на промоцията на главния кандидат за прилагане на диференциални релейни регистри. Ако основната база данни умре, MHA Manager ще се координира с агента на MHA Node, тъй като прилага диференциални релейни регистрационни файлове към подчинените, които нямат най-новите binlog събития от главния.
Проверете какво прави агентът на MHA Node и участващите в него скриптове. По принцип това е скриптът, който MHA Manager ще извика, когато възникне отказ. Той ще изчака своя мандат от MHA Manager, докато търси най-новия подчинен, който съдържа binlog събитията и копира липсващите събития от подчинения с помощта на scp и ги прилага към себе си. Както бе споменато, той прилага релейни регистрационни файлове, изчиства релейни регистрационни файлове или записва двоични регистрационни файлове.
Ако искате да научите повече за регулируемите параметри и как да персонализирате управлението си при отказ, разгледайте wiki страницата Параметри за MHA.
Използване на Orchestrator
Orchestrator е MySQL и MariaDB инструмент за управление с висока наличност и репликация. Той е пуснат от Shlomi Noach при условията на лиценза Apache, версия 2.0. Това е софтуер с отворен код и се справя с автоматично преминаване при отказ, но има много неща, които можете да персонализирате или да направите, за да управлявате вашата база данни MySQL/MariaDB, освен възстановяването или автоматичното превключване при отказ.
Инсталирането на Orchestrator може да бъде лесно или просто. След като изтеглите специфичните пакети, необходими за вашата целева среда, вие сте готови да регистрирате своя клъстер и възли, които да бъдат наблюдавани от Orchestrator. Той предоставя потребителски интерфейс, за който това е много лесно за управление, но има много регулируеми параметри или набор от команди, които можете да използвате, за да постигнете управлението си при отказ.
Нека смятаме, че най-накрая сте настроили и регистрирането на клъстера чрез добавяне на нашия основен или главен възел може да стане с командата по-долу,
$ orchestrator -c discover -i pupnode21:3306
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: pupnode21
2021-01-07 12:32:31 DEBUG Cache hostname resolve pupnode21 as pupnode21
2021-01-07 12:32:31 DEBUG Connected to orchestrator backend: orchestrator:example@sqldat.com(127.0.0.1:3306)/orchestrator?timeout=1s
2021-01-07 12:32:31 DEBUG Orchestrator pool SetMaxOpenConns: 128
2021-01-07 12:32:31 DEBUG Initializing orchestrator
2021-01-07 12:32:31 INFO Connecting to backend 127.0.0.1:3306: maxConnections: 128, maxIdleConns: 32
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.222
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.222 as 192.168.40.222
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.223
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.223 as 192.168.40.223
pupnode21:3306Сега имаме добавен клъстер.
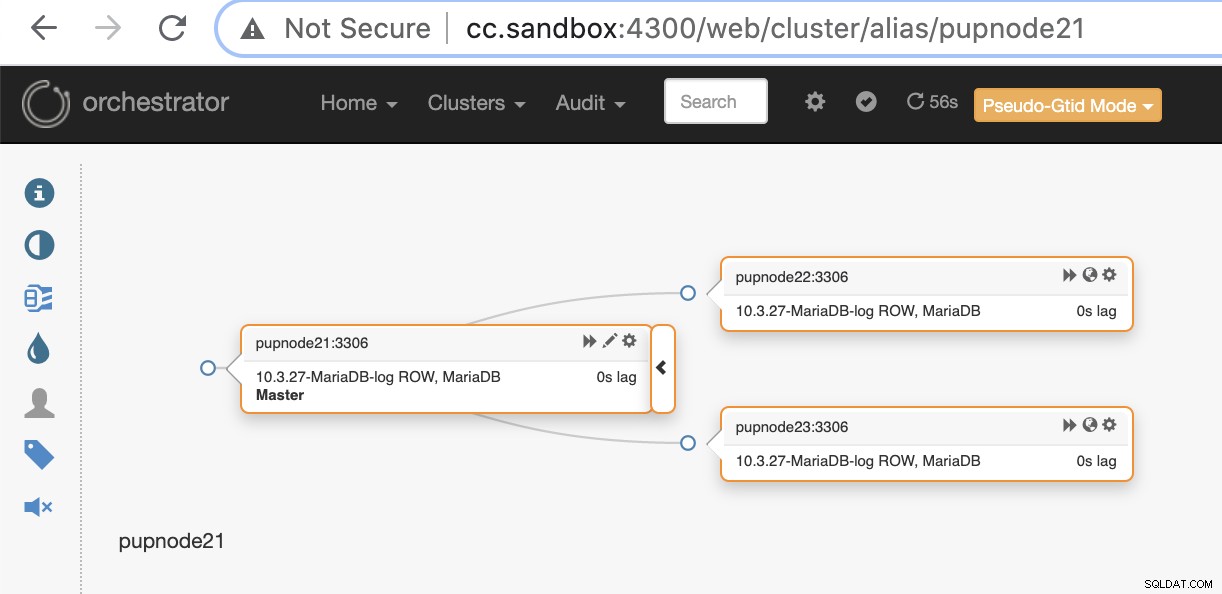
Ако основен възел се повреди (хардуерна повреда или срив), Orchestrator ще откриване и намиране на най-напредналия възел, който да бъде повишен като основен или главен възел.
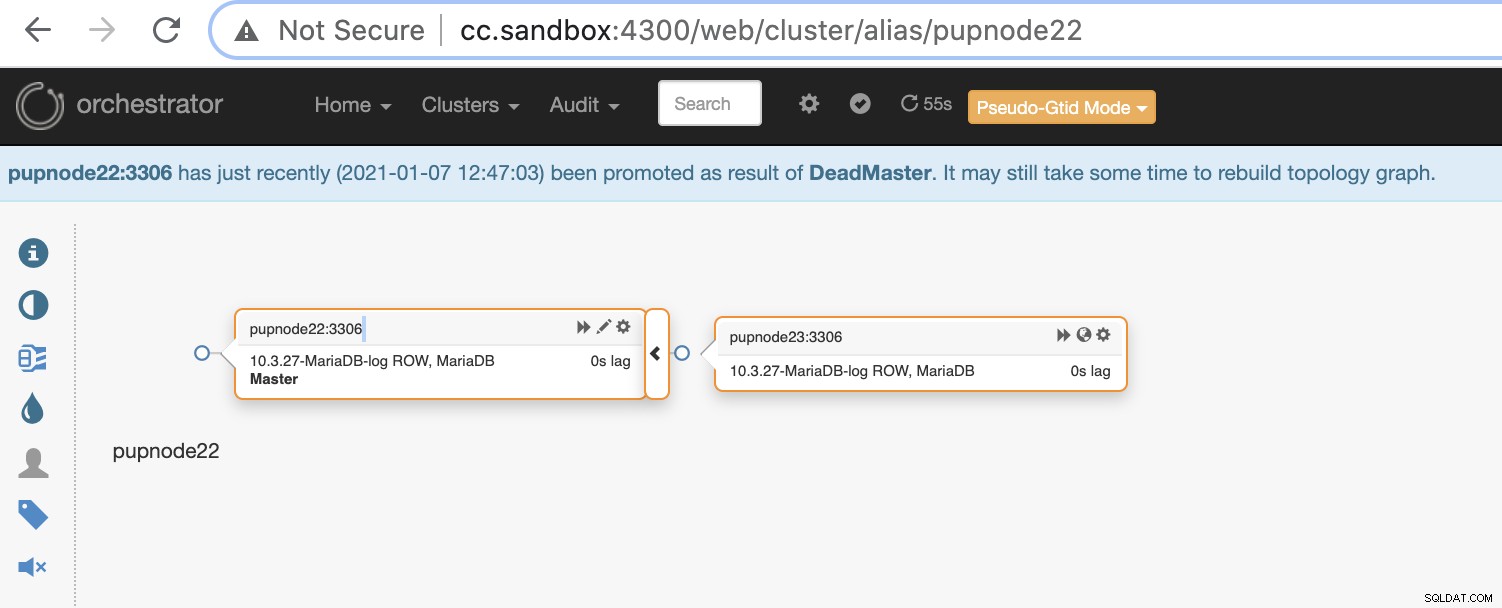
Сега имаме два възела, останали в клъстера, докато основният не работи .
$ orchestrator-client -c topology -i pupnode21:3306
pupnode21:3306 [unknown,invalid,10.3.27-MariaDB-log,rw,ROW,>>,downtimed]
$ orchestrator-client -c topology -i pupnode22:3306
pupnode22:3306 [0s,ok,10.3.27-MariaDB-log,rw,ROW,>>]
+ pupnode23:3306 [0s,ok,10.3.27-MariaDB-log,ro,ROW,>>,GTID]Използване на MaxScale
MariaDB MaxScale се поддържа като балансьор на натоварване на базата данни. През годините MaxScale се разраства и усъвършенства, разширява се с няколко богати функции и това включва автоматично превключване при отказ. След като MariaDB MaxScale 2.2 беше пуснат, той въвежда няколко нови функции, включително управление на отказ от клъстер за репликация. Можете да прочетете предишния ни блог относно механизма за преодоляване при отказ на MaxScale.
Използването на MaxScale е под BSL, въпреки че софтуерът е свободно достъпен, но изисква поне да закупите услуга с MariaDB. Може да не е подходящо, но в случай, че сте придобили MariaDB корпоративни услуги, това може да бъде голямо предимство, ако се нуждаете от управление на отказ и други негови функции.
Инсталирането на MaxScale е лесно, но настройването на необходимата конфигурация и дефинирането на нейните параметри не е и изисква да разбирате софтуера. Можете да се обърнете към тяхното ръководство за конфигурация.
За бързо и бързо внедряване можете да използвате ClusterControl, за да инсталирате MaxScale вместо вас във вашата съществуваща среда MySQL/MariaDB.
Веднъж инсталирана, настройката на вашата Moodle база данни може да се извърши чрез насочване на вашия хост към MaxScale IP или име на хост и порт за четене-запис. Например,
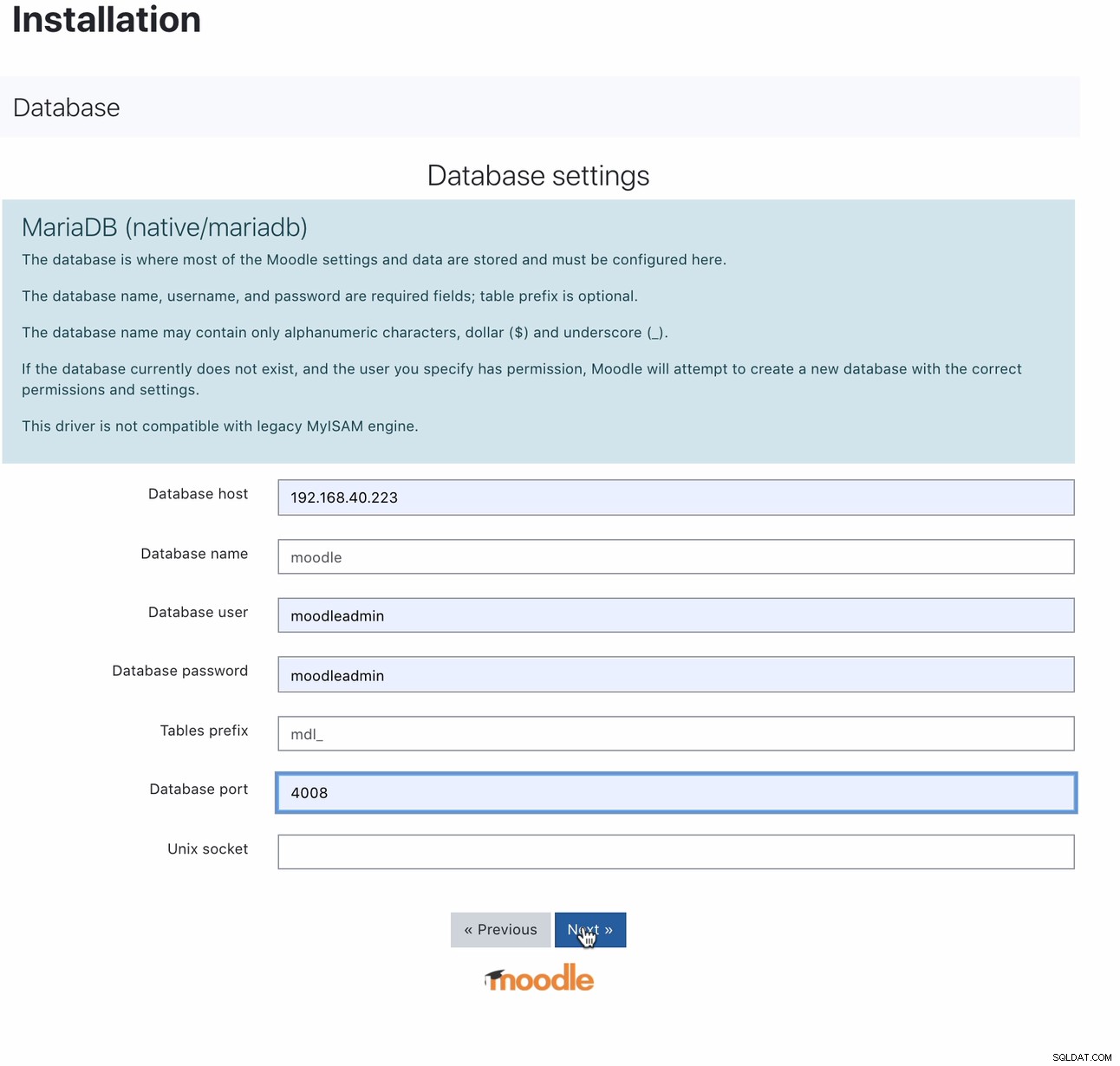
За кой порт 4008 е вашият четене и запис за вашия слушател на услугата. Например, ето следната конфигурация на услугата и слушателя за моя MaxScale.
$ cat maxscale.cnf.d/rw-listener.cnf
[rw-listener]
type=listener
protocol=mariadbclient
service=rw-service
address=0.0.0.0
port=4008
authenticator=MySQLAuth
$ cat maxscale.cnf.d/rw-service.cnf
[rw-service]
type=service
servers=DB_123,DB_122,DB_124
router=readwritesplit
user=maxscale_adm
password=42BBD2A4DC1BF9BE05C41A71DEEBDB70
max_slave_connections=100%
max_sescmd_history=15000000
causal_reads=true
causal_reads_timeout=10
transaction_replay=true
transaction_replay_max_size=32Mi
delayed_retry=true
master_reconnection=true
max_connections=0
connection_timeout=0
use_sql_variables_in=master
master_accept_reads=true
disable_sescmd_history=falseДокато в конфигурацията на монитора си, не трябва да забравяте да активирате автоматичното преминаване при отказ или също да активирате автоматично повторно присъединяване, ако искате предишният главен файл да не успее да се присъедини автоматично, когато се върнете онлайн. Става така,
$ egrep -r 'auto|^\[' maxscale.cnf.d/replication_monitor.cnf
[replication_monitor]
auto_failover=true
auto_rejoin=1Обърнете внимание, че променливите, които посочих, не са предназначени за производствена употреба, а само за тази публикация в блога и тестови цели. Хубавото на MaxScale е, че след като първичният или главният изпадне, MaxScale е достатъчно умен, за да популяризира идеалния или най-добрия кандидат, който да поеме ролята на главен. Следователно няма нужда да променяте вашия IP и порт, тъй като сме използвали хоста/IP на нашия възел MaxScale и неговия порт като наша крайна точка, след като главната страна изпадне. Например,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Възел DB_123, който сочи към 192.168.40.221, е текущият главен. Прекратяването на възела DB_123 ще задейства MaxScale за извършване на отказ и ще изглежда така,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Down │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Въпреки че нашата база данни Moodle все още работи, тъй като нашият MaxScale сочи към най-новия главен код, който беше повишен.
$ mysql -hmaxscale.local.domain -umoodleuser -pmoodlepassword -P4008
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 9
Server version: 10.3.27-MariaDB-log MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> select @@hostname;
+------------+
| @@hostname |
+------------+
| 192.168.40.222 |
+------------+
1 row in set (0.001 sec)Използване на ClusterControl
ClusterControl може да бъде изтеглен безплатно и предлага лицензи за Community, Advance и Enterprise. Автоматичният отказ е достъпен само за Advance и Enterprise. Автоматичното преминаване при отказ е обхванато от нашата функция за автоматично възстановяване, която се опитва да възстанови неуспешен клъстер или неуспешен възел. Ако искате повече подробности за това как да направите това, вижте предишната ни публикация Как ClusterControl извършва автоматично възстановяване на базата данни и отказ. Той предлага регулируеми параметри, които са много удобни и лесни за използване. Моля, прочетете и предишната ни публикация за Как да автоматизирате отказ на база данни с ClusterControl.
Управлението на вашия автоматичен отказ за вашата база данни на Moodle трябва поне да изисква виртуален IP (VIP) като крайна точка за вашия клиент на приложението Moodle, който взаимодейства с вашата база данни. За да направите това, можете да разположите Keepalived с HAProxy (или ProxySQL – зависи от избора ви за балансиране на натоварването) върху него. В този случай крайната точка на вашата база данни на Moodle ще сочи към виртуалния IP адрес, който основно се присвоява от Keepalived, след като сте го разгърнали, както ви показахме по-рано при настройката на MaxScale. Можете също да проверите този блог как да го направите.
Както беше споменато по-горе, са налични регулируеми параметри, които можете просто да зададете чрез вашия /etc/cmon.d/cmon_
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- Replication_post_failover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
ClusterControl е много гъвкав при управлението на отказ, така че можете да изпълнявате някои задачи преди отказ или след отказ.
Заключение
Има и други страхотни възможности за настройване и автоматично управление на отказоустойчивостта за вашата MySQL база данни за Moodle. Зависи от вашия бюджет и за какво вероятно ще трябва да харчите пари. Използването на такива с отворен код изисква опит и изисква множество тестове, за да се запознаете, тъй като няма поддръжка, която можете да използвате, когато имате нужда от помощ, различна от общността. С корпоративните решения той идва с цена, но ви предлага поддръжка и лекота, тъй като отнемащата време работа може да бъде намалена. Обърнете внимание, че ако се използва погрешно преминаване при отказ, това може да струва щети на вашата база данни, ако не се обработва и управлява правилно. Съсредоточете се върху това, което е по-важно и как сте способни на решенията, които използвате за управление на отказ на вашата база данни Moodle.