В тази публикация в блога ще разгледаме някои ключови показатели и състояние, когато наблюдаваме Percona сървър за MySQL, за да ни помогне да настроим фино конфигурацията на MySQL сървъра за дългосрочен план. Само за предупреждение, Percona Server има някои показатели за наблюдение, които са налични само в тази версия. Когато се сравнява с версия 8.0.20, следните 51 статуса са налични само на Percona Server за MySQL, които не са налични в горния MySQL Community Server на Oracle:
- Binlog_snapshot_file
- Binlog_snapshot_position
- Binlog_snapshot_gtid_executed
- Com_create_compression_dictionary
- Com_drop_compression_dictionary
- Com_lock_tables_for_backup
- Com_show_client_statistics
- Com_show_index_statistics
- Com_show_table_statistics
- Com_show_thread_statistics
- Com_show_user_statistics
- Innodb_background_log_sync
- Innodb_buffer_pool_pages_LRU_flushed
- Innodb_buffer_pool_pages_made_not_young
- Innodb_buffer_pool_pages_made_young
- Innodb_buffer_pool_pages_old
- Innodb_checkpoint_age
- Innodb_ibuf_free_list
- Innodb_ibuf_segment_size
- Innodb_lsn_current
- Innodb_lsn_flushed
- Innodb_lsn_last_checkpoint
- Innodb_master_thread_active_loops
- Innodb_master_thread_idle_loops
- Innodb_max_trx_id
- Innodb_oldest_view_low_limit_trx_id
- Innodb_pages0_read
- Innodb_purge_trx_id
- Innodb_purge_undo_no
- Innodb_secondary_index_triggered_cluster_reads
- Innodb_secondary_index_triggered_cluster_reads_avoided
- Innodb_buffered_aio_submitted
- Innodb_scan_pages_contiguous
- Innodb_scan_pages_disjointed
- Innodb_scan_pages_total_seek_distance
- Innodb_scan_data_size
- Innodb_scan_deleted_recs_size
- Innodb_scrub_log
- Innodb_scrub_background_page_reorganizations
- Innodb_scrub_background_page_splits
- Innodb_scrub_background_page_split_failures_underflow
- Innodb_scrub_background_page_split_failures_out_of_filespace
- Innodb_scrub_background_page_split_failures_missing_index
- Innodb_scrub_background_page_split_failures_unknown
- Innodb_encryption_n_merge_blocks_encrypted
- Innodb_encryption_n_merge_blocks_decrypted
- Innodb_encryption_n_rowlog_blocks_encrypted
- Innodb_encryption_n_rowlog_blocks_decrypted
- Innodb_encryption_redo_key_version
- Threadpool_idle_threads
- Threadpool_threads
Разгледайте страницата Extended InnoDB Status за повече информация относно всеки от показателите за наблюдение по-горе. Имайте предвид, че някои допълнителни състояния като пул на нишки са налични само в MySQL Enterprise на Oracle. Разгледайте документацията на Percona Server за MySQL 8.0, за да видите всички подобрения специално за тази версия спрямо MySQL Community Server 8.0 на Oracle.
За да извлечете глобалното състояние на MySQL, просто използвайте един от следните изрази:
mysql> SHOW GLOBAL STATUS;
mysql> SHOW GLOBAL STATUS LIKE '%connect%'; -- list all status that contain string "connect"
mysql> SELECT * FROM performance_schema.global_status;
mysql> SELECT * FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE '%connect%'; -- list all status that contain string "connect"Състояние и общ преглед на базата данни
Ще започнем със състоянието на ъптайм, броят на секундите, през които сървърът е работил.
Всички състояния на com_* са променливите на брояча на изрази, които показват колко пъти е било изпълнено всяко изявление. Има една променлива на състоянието за всеки тип изявление. Например, com_delete и com_update броят операторите DELETE и UPDATE, съответно. com_delete_multi и com_update_multi са подобни, но се прилагат за изрази DELETE и UPDATE, които използват синтаксис на множество таблици.
За да изброите всички изпълнявани процеси от MySQL, просто изпълнете един от следните оператори:
mysql> SHOW PROCESSLIST;
mysql> SHOW FULL PROCESSLIST;
mysql> SELECT * FROM information_schema.processlist;
mysql> SELECT * FROM information_schema.processlist WHERE command <> 'sleep'; -- list all active processes except 'sleep' command.Връзки и нишки
Текущи връзки
Съотношението на отворените в момента връзки (съединителна резба). Ако съотношението е високо, това показва, че има много едновременни връзки към MySQL сървъра и може да доведе до грешка „Твърде много връзки“. За да получите процента на връзката:
Current connections(%) = (threads_connected / max_connections) x 100Добрата стойност трябва да бъде 80% и по-ниска. Опитайте да увеличите променливата max_connections или проверете връзките, като използвате ПОКАЗВАНЕ НА ПЪЛЕН ПРОЦЕССПИС. Когато се случат грешки "Твърде много връзки", сървърът на базата данни на MySQL ще стане недостъпен за потребителя, който не е супер, докато някои връзки не бъдат освободени. Имайте предвид, че увеличаването на променливата max_connections също може потенциално да увеличи отпечатъка на паметта на MySQL.
Максимални връзки, виждани някога
Съотношението на максималните връзки към MySQL сървъра, което някога е било виждано. Едно просто изчисление би било:
Max connections ever seen(%) = (max_used_connections / max_connections) x 100Добрата стойност трябва да е под 80%. Ако съотношението е високо, това показва, че MySQL веднъж е достигнал голям брой връзки, което би довело до грешка „твърде много връзки“. Проверете съотношението на текущите връзки, за да видите дали наистина остава ниско постоянно. В противен случай увеличете променливата max_connections. Проверете състоянието на max_used_connections_time, за да посочите кога състоянието на max_used_connections е достигнало текущата си стойност.
Честота на посещения в кеша на нишки
Състоянието на threads_created е броят на нишките, създадени за обработка на връзки. Ако threads_created е голям, може да искате да увеличите стойността thread_cache_size. Процентът на попадане/пропускане в кеша може да се изчисли като:
Threads cache hit rate (%) = (threads_created / connections) x 100Това е фракция, която дава индикация за степента на попадане в кеша на нишките. Колкото по-близо е по-малко от 50%, толкова по-добре. Ако вашият сървър вижда стотици връзки в секунда, обикновено трябва да зададете thread_cache_size достатъчно висок, така че повечето нови връзки да използват кеширани нишки.
Ефективност на заявката
Пълно сканиране на таблица
Съотношението на пълните сканирания на таблицата, операция, която изисква четене на цялото съдържание на таблица, а не само избрани части с помощта на индекс. Тази стойност е висока, ако правите много заявки, които изискват сортиране на резултатите или сканиране на таблици. Като цяло това предполага, че таблиците не са правилно индексирани или че вашите заявки не са написани, за да се възползвате от индексите, които имате. За да изчислите процента на пълните сканирания на таблицата:
Full table scans (%) = (handler_read_rnd_next + handler_read_rnd) /
(handler_read_rnd_next + handler_read_rnd + handler_read_first + handler_read_next + handler_read_key + handler_read_prev)
x 100Добрата стойност трябва да е под 25%. Разгледайте изходния дневник на бавните заявки на MySQL, за да откриете неоптималните заявки.
Изберете Пълно присъединяване
Състоянието на select_full_join е броят на присъединяванията, които извършват сканиране на таблици, тъй като не използват индекси. Ако тази стойност не е 0, трябва внимателно да проверите индексите на вашите таблици.
Изберете Проверка на обхвата
Състоянието на select_range_check е броят на присъединяванията без ключове, които проверяват използването на ключ след всеки ред. Ако това не е 0, трябва внимателно да проверите индексите на вашите таблици.
Пропуски за сортиране
Съотношението на преминаванията на сливане, което алгоритъмът за сортиране трябва да направи. Ако тази стойност е висока, трябва да помислите за увеличаване на стойността на sort_buffer_size и read_rnd_buffer_size. Простото изчисление на съотношението е:
Sort passes = sort_merge_passes / (sort_scan + sort_range)Стойност на съотношението, по-ниска от 3, трябва да е добра стойност. Ако искате да увеличите sort_buffer_size или read_rnd_buffer_size, опитайте се да увеличавате на малки стъпки, докато достигнете приемливото съотношение.
Ефективност на InnoDB
Честота на попадане в буферния пул на InnoDB
Съотношението на това колко често вашите страници се извличат от памет вместо от диск. Ако стойността е ниска по време на ранното стартиране на MySQL, моля, изчакайте известно време, за да се загрее буферният пул. За да получите скоростта на попадане в буферния пул, използвайте израза SHOW ENGINE INNODB STATUS:
mysql> SHOW ENGINE INNODB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
...Най-добрата стойност е 1000 / 10000 хит. За по-ниска стойност, например, честотата на попадане от 986 / 1000 показва, че от 1000 четения на страница е успял да прочете страници в RAM 986 пъти. Останалите 14 пъти MySQL трябваше да прочете страниците от диск. Просто казано, 1000 / 1000 е най-добрата стойност, която се опитваме да постигнем тук, което означава, че често достъпните данни се вписват напълно в RAM.
Увеличаването на променливата innodb_buffer_pool_size ще помогне много за разполагане на повече място за работа на MySQL. Уверете се обаче, че имате достатъчно RAM ресурси предварително. Премахването на излишни индекси също може да помогне. Ако имате няколко екземпляра на буферен пул, уверете се, че процентът на попадане за всеки екземпляр достига 1000 / 1000.
Мръсни страници на InnoDB
Съотношението на това колко често InnoDB трябва да се промива. По време на тежкото натоварване при запис е нормално този процент да се увеличава.
Просто изчисление би било:
InnoDB dirty pages(%) = (innodb_buffer_pool_pages_dirty / innodb_buffer_pool_pages_total) x 100Добрата стойност трябва да бъде 75% и по-ниска. Ако процентът мръсни страници остане висок за дълго време, може да искате да увеличите буферния пул или да получите по-бързи дискове, за да избегнете затруднения в производителността.
InnoDB чака за контролна точка
Съотношението на това колко често InnoDB трябва да чете или да създаде страница, където няма налични чисти страници. Обикновено записите в буферния пул на InnoDB се случват на заден план. Ако обаче е необходимо да прочетете или създадете страница и няма налични чисти страници, също така е необходимо да изчакате първо страниците да бъдат изчистени. Броячът innodb_buffer_pool_wait_free отчита колко пъти се е случило това. За да изчислим съотношението на InnoDB изчакване за контролна точка, можем да използваме следното изчисление:
InnoDB waits for checkpoint = innodb_buffer_pool_wait_free / innodb_buffer_pool_write_requestsАко innodb_buffer_pool_wait_free е по-голям от 0, това е силен индикатор, че буферният пул на InnoDB е твърде малък и операциите трябваше да изчакат на контролна точка. Увеличаването на innodb_buffer_pool_size обикновено ще намали innodb_buffer_pool_wait_free, както и това съотношение. Стойността на доброто съотношение трябва да остане под 1.
InnoDB чака Redolog
Съотношението на спора за регистрационния файл за повторно изпълнение. Проверете innodb_log_waits и ако продължава да се увеличава, тогава увеличете innodb_log_buffer_size. Това може също да означава, че дисковете са твърде бавни и не могат да издържат дисковия IO, може би поради пиковото натоварване при запис. Използвайте следното изчисление, за да изчислите коефициента на изчакване на дневника за повторно изпълнение:
InnoDB waits for redolog = innodb_log_waits / innodb_log_writesДобрата стойност на съотношението трябва да е под 1. В противен случай увеличете innodb_log_buffer_size.
Таблици
Използване на кеша на таблици
Съотношението на използване на кеша на таблицата за всички нишки. Едно просто изчисление би било:
Table cache usage(%) = (opened_tables / table_open_cache) x 100Добрата стойност трябва да е по-малка от 80%. Увеличете променливата table_open_cache, докато процентът достигне добра стойност.
Съотношение на попадане в кеша на таблицата
Съотношението на използване на кеша на таблицата. Едно просто изчисление би било:
Table cache hit ratio(%) = (open_tables / opened_tables) x 100Добрият коефициент на попадане трябва да бъде 90% и повече. В противен случай увеличете променливата table_open_cache, докато съотношението на посещения достигне добра стойност.
Наблюдение на показателите с ClusterControl
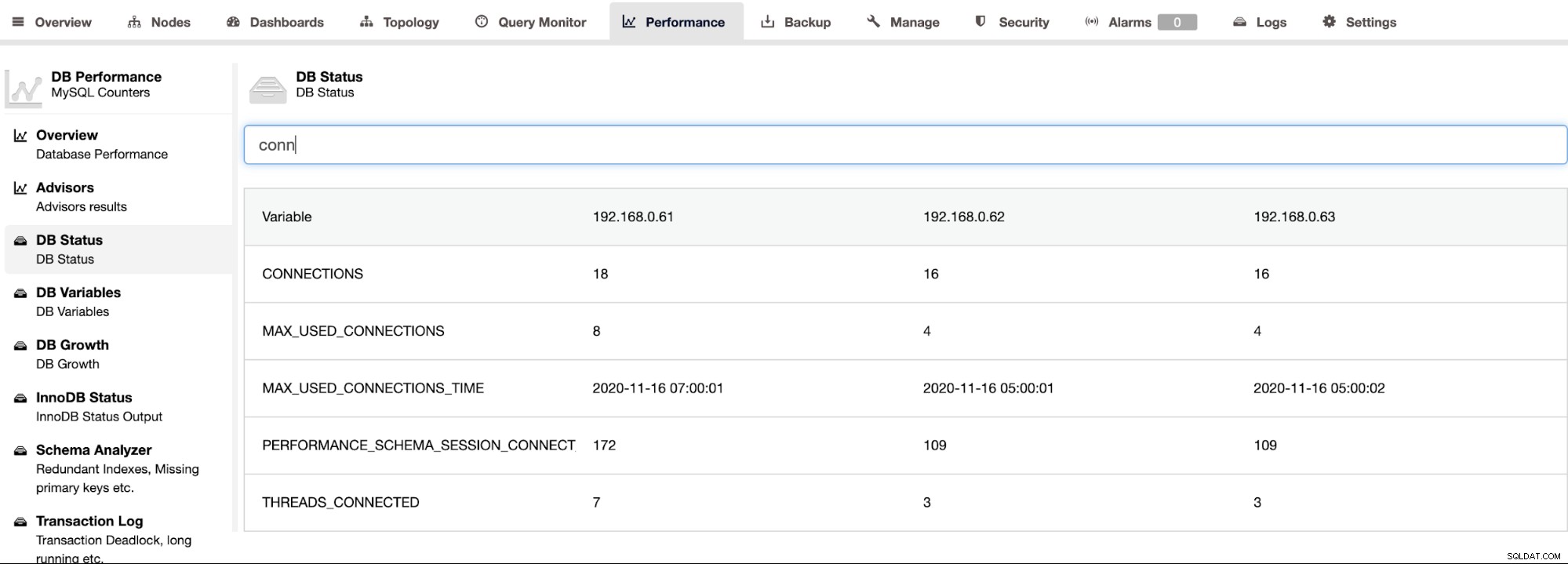
ClusterControl поддържа Percona Server за MySQL и предоставя обобщен изглед на всички възли в клъстер под страницата ClusterControl -> Performance -> DB Status. Това осигурява централизиран подход за търсене на цялото състояние на всички хостове с възможност за филтриране на състоянието, както е показано на следната екранна снимка:
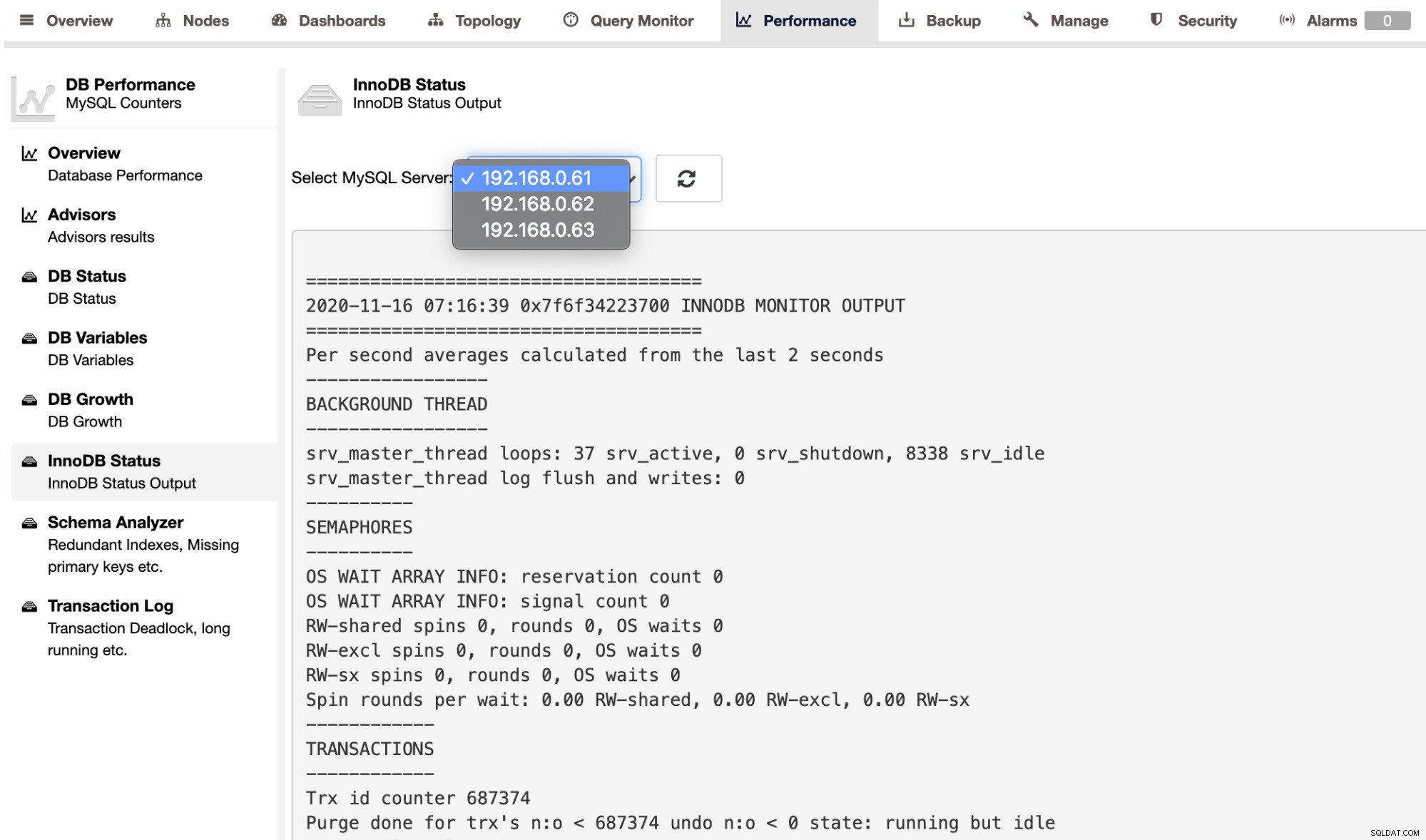
За да извлечете изхода SHOW ENGINE INNODB STATUS за отделен сървър, можете използвайте страницата Performance -> InnoDB Status, както е показано по-долу:
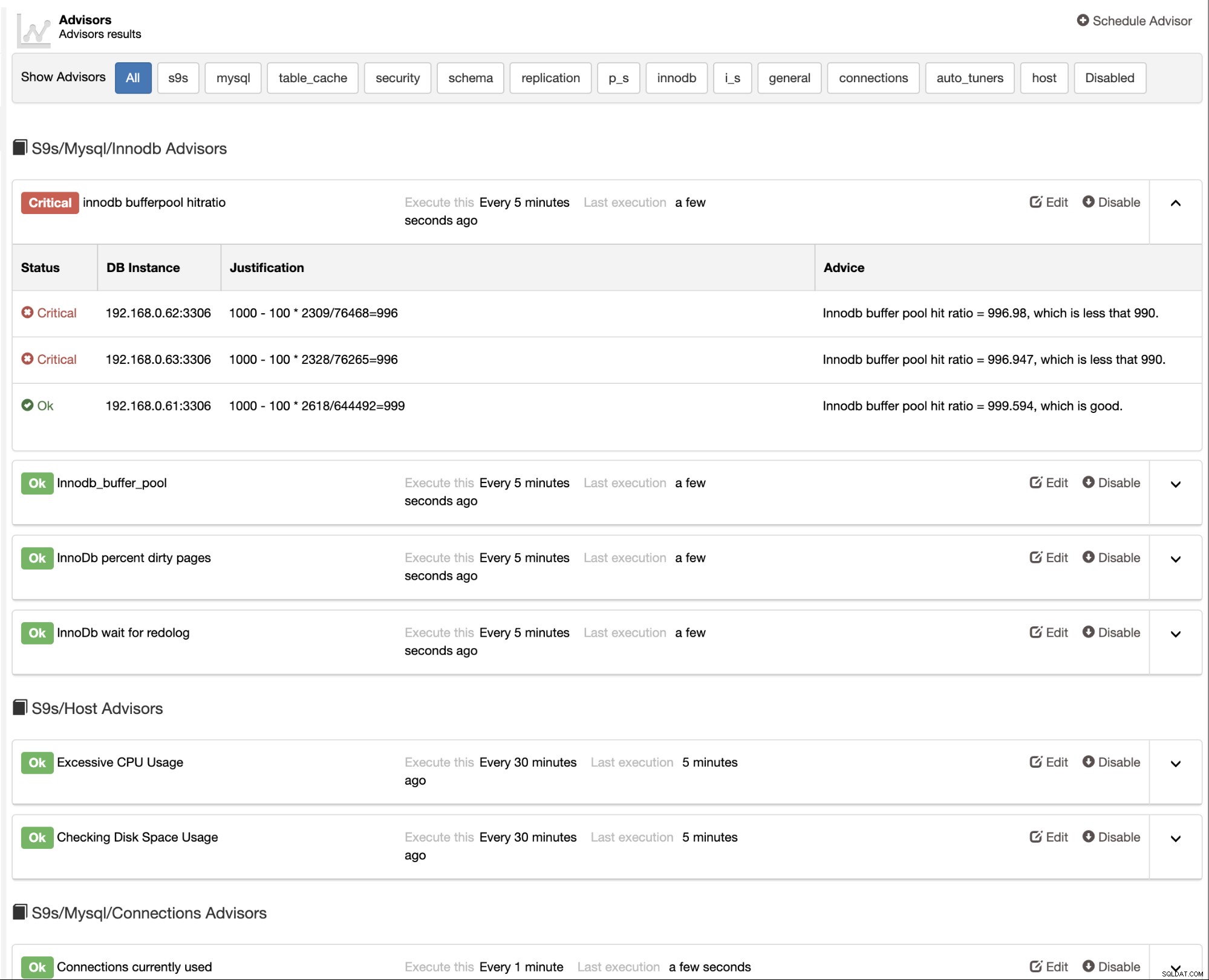
ClusterControl също така предоставя вградени съветници, които можете да използвате за проследяване на вашата база данни производителност. Тази функция е достъпна под ClusterControl -> Performance -> Advisors:
Съветниците са основно мини-програми, изпълнявани от ClusterControl в планирано време като cron работни места. Можете да планирате съветник, като щракнете върху бутона „Насрочване на съветник“ и изберете всеки съществуващ съветник от дървото на обектите на Developer Studio:
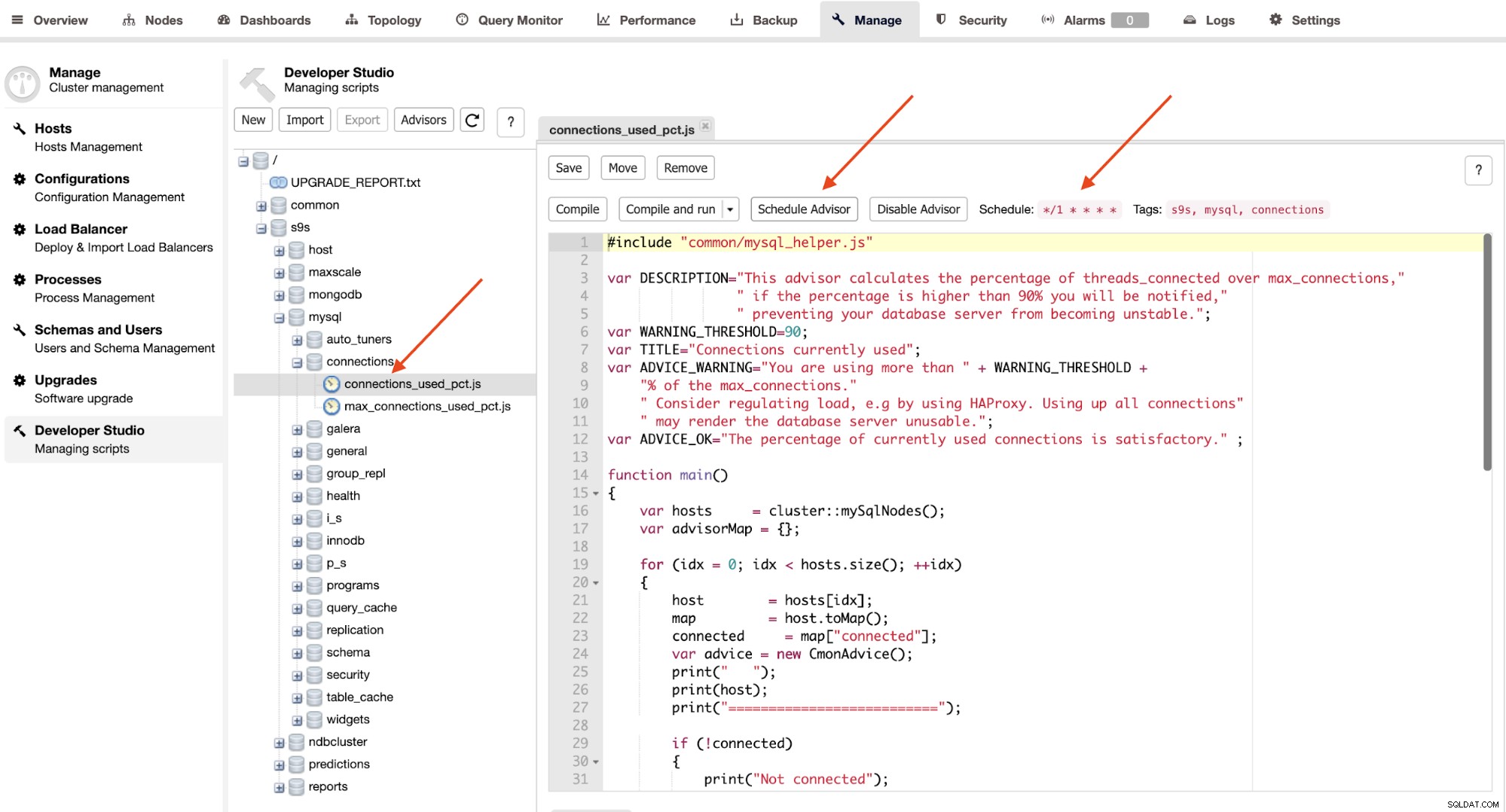
Щракнете върху бутона „Съветник по график“, за да зададете графика, аргумент за пас, както и етикетите на съветника. Можете също да компилирате съветника, за да видите изхода незабавно, като щракнете върху бутона „Компилиране и стартиране“, където трябва да видите следния изход под „Съобщения“ под него:

Можете да създадете свой собствен съветник, като се обърнете към това ръководство за програмисти, написано на Специфичен език за домейн ClusterControl (много подобен на Javascript) или персонализирайте съществуващ съветник, за да отговаря на вашите политики за наблюдение. Накратко, задължението за наблюдение на ClusterControl може да бъде разширено с неограничени възможности чрез ClusterControl Advisors.