Ако вашата ИТ инфраструктура работи на AWS, вероятно сте чували за Amazon Relational Database Service (RDS), лесен начин за настройка, работа и мащабиране на релационна база данни в облака. Той осигурява рентабилен капацитет с възможност за промяна на размера, като същевременно автоматизира отнемащи време административни задачи, като осигуряване на хардуер, настройка на база данни, корекция и архивиране. Има редица предложения за машини за бази данни за RDS като MySQL, MariaDB, PostgreSQL, Microsoft SQL Server и Oracle Server.
ClusterControl 1.7.3 действа подобно на RDS, тъй като поддържа разгръщане на клъстери от база данни, управление, наблюдение и мащабиране на платформата AWS. Той също така поддържа редица други облачни платформи като Google Cloud Platform и Microsoft Azure. ClusterControl разбира топологията на базата данни и е в състояние да извършва автоматично възстановяване, управление на топологията и много други разширени функции, за да поеме контрола над вашата база данни.
В тази публикация в блога ще сравним времето за автоматично преминаване при отказ за Amazon Aurora, Amazon RDS за MySQL и настройка на MySQL репликация, разгърната и управлявана от ClusterControl. Типът отказ, който ще направим, е повишение на подчинен в случай, че главният се повреди. Това е мястото, където най-актуалният подчинен поема главната роля в клъстера, за да възобнови услугата за база данни.
Нашият тест за отказ
За да измерим времето за преодоляване на отказ, ще изпълним прост тест за актуализиране на свързване на MySQL, с цикъл за преброяване на състоянието на SQL израза, който се свързва с една крайна точка на базата данни. Скриптът изглежда така:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
Горещият Bash скрипт просто се свързва с MySQL хост и извършва актуализация на един ред с изчакване от 1 секунда както на клиентските команди на Bash, така и на mysql. Параметрите, свързани с изчакването, са необходими, за да можем да измерим правилно времето на престой в секунди, тъй като mysql клиентът по подразбиране винаги се свързва отново, докато достигне MySQL wait_timeout. Предварително попълнихме тестов набор от данни със следната команда:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepareСкриптът съобщава дали заявката по-горе е била успешна (OK) или неуспешна (Fail). Примерните резултати са показани по-надолу.
Отказ при отказ с Amazon RDS за MySQL
В нашия тест използваме най-ниското предложение за RDS със следните спецификации:
- Версия на MySQL:5.7.22
- vCPU:4
- RAM:16 GB
- Тип съхранение:Осигурени IOPS (SSD)
- IOPS:1000
- Съхранение:100 Gib
- Много-AZ репликация:Да
След като Amazon RDS осигури вашия DB екземпляр, можете да използвате всяко стандартно MySQL клиентско приложение или помощна програма, за да се свържете с инстанцията. В низа за свързване посочвате DNS адреса от крайната точка на DB екземпляр като параметър на хост и посочвате номера на порта от крайната точка на DB екземпляр като параметър на порта.
Според страницата с документация на Amazon RDS, в случай на планирано или непланирано прекъсване на вашия DB екземпляр, Amazon RDS автоматично превключва към резервна реплика в друга зона за достъпност, ако сте активирали Multi-AZ. Времето, необходимо за завършване на отказоустойчивостта, зависи от дейността на базата данни и други условия в момента, в който първичният DB екземпляр е станал недостъпен. Времената за отказ обикновено са 60-120 секунди.
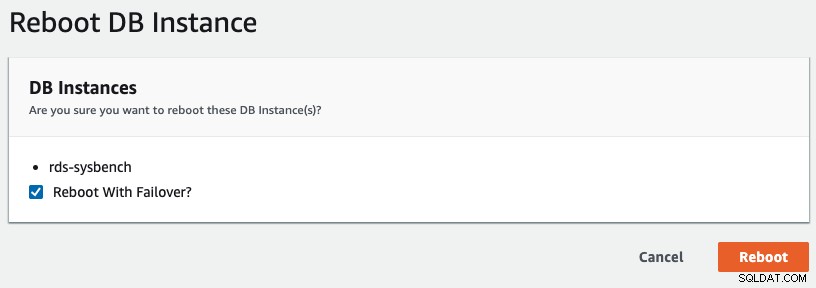
За да инициираме отказ от няколко AZ в RDS, извършихме операция за рестартиране с отметка „Рестартиране с отказ“, както е показано на следната екранна снимка:
Следното се наблюдава от нашето приложение:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...Времето за престой на MySQL, както се вижда от страната на приложението, е стартирано от 03:41:09 до 03:41:36, което е около 27 секунди общо. От RDS събитията можем да видим, че отказът от няколко AZ се е случил само 15 секунди след действителното престой:
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.След като новият екземпляр на базата данни се рестартира около 03:41:33, услугата MySQL беше достъпна около 3 секунди по-късно.
Отказ при отказ с Amazon Aurora за MySQL
Amazon Aurora може да се счита за по-добра версия на RDS, с много забележителни функции като по-бързо репликация със споделено съхранение, без загуба на данни по време на отказ и до 64TB лимит за съхранение. Amazon Aurora за MySQL се базира на MySQL Edition с отворен код, но не е с отворен код сам по себе си; това е собствена база данни със затворен код. Работи по подобен начин с MySQL репликация (един и само един главен, с множество подчинени) и преминаването на отказ се обработва автоматично от Amazon Aurora.
Според често задаваните въпроси на Amazon Aurora, ако имате реплика на Amazon Aurora, в същата или различна зона за наличност, при отказ, Aurora преобръща записа на каноничното име (CNAME) за вашия DB екземпляр, за да посочи здравата реплика, която е в ред е повишен, за да стане новият първичен. От начало до край, преминаването при отказ обикновено завършва в рамките на 30 секунди.
Ако нямате реплика на Amazon Aurora (т.е. единичен екземпляр), Aurora първо ще се опита да създаде нов DB екземпляр в същата зона за наличност като оригиналния екземпляр. Ако не може да направи това, Aurora ще се опита да създаде нов DB екземпляр в различна зона за наличност. От началото до края преминаването при отказ обикновено завършва за по-малко от 15 минути.
Вашето приложение трябва да опита отново връзки към базата данни в случай на загуба на връзка.
След като Amazon Aurora предостави вашия DB екземпляр, вие ще получите две крайни точки, една за писателя и една за четеца. Крайната точка на четеца осигурява поддръжка за балансиране на натоварването за връзки само за четене към DB клъстера. Следните крайни точки са взети от нашата тестова настройка:
- писател - aurora-sysbench.cluster-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
- четец - aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
В нашия тест използвахме следните спецификации на Aurora:
- Тип на екземпляра:db.r5.large
- Версия на MySQL:5.7.12
- vCPU:2
- RAM:16 GB
- Много-AZ репликация:Да
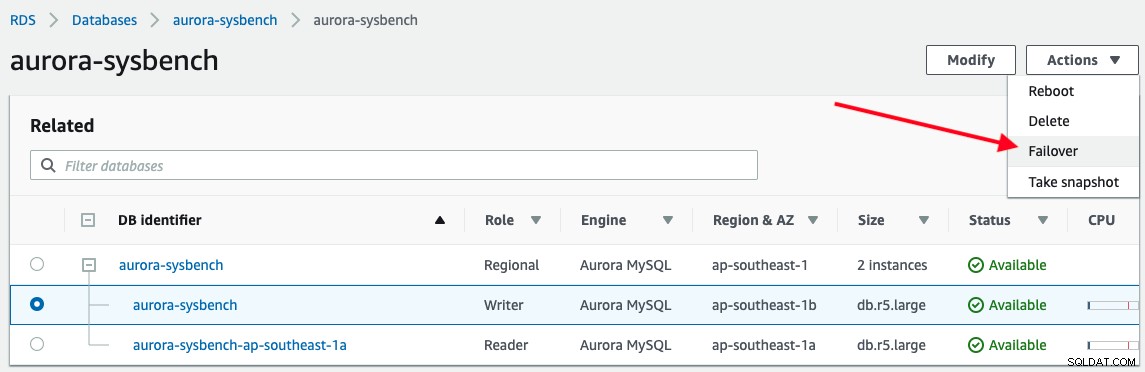
За да задействате отказ, просто изберете екземпляра на записващо устройство -> Действия -> Failover, както е показано на следната екранна снимка:
Следният изход се отчита от нашето приложение, докато се свързва с крайната точка за запис на Aurora :
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...Престой на базата данни е започнал в 12:35:49 до 12:35:56 с обща продължителност 7 секунди. Това е доста впечатляващо.
Разглеждайки събитието в базата данни от конзолата за управление на Aurora, се случиха само тези две събития:
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedНе отнема много време на Аврора да повиши роба да стане господар и да понижи господаря, за да стане роб. Имайте предвид, че всички реплики на Aurora споделят един и същ основен обем с първичния екземпляр и това означава, че репликацията може да се извърши за милисекунди, тъй като актуализациите, направени от първичния екземпляр, са незабавно достъпни за всички реплики на Aurora. Следователно има минимално забавяне на репликацията (Amazon твърди, че е 100 милисекунди и по-малко). Това значително ще намали времето за проверка на състоянието и значително ще подобри времето за възстановяване.
Отказ при отказ с ClusterControl
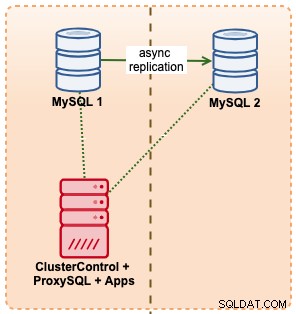
В този пример ние имитираме подобна настройка с Amazon RDS, използвайки m5.xlarge екземпляри, с ProxySQL между тях, за да автоматизираме преминаването на отказ от приложение, използвайки достъп до една крайна точка, точно като RDS. Следната диаграма илюстрира нашата архитектура:
Тъй като имаме директен достъп до екземплярите на базата данни, бихме задействали автоматично преминаване при отказ, като просто убием процеса на MySQL на активния главен обект:
$ kill -9 $(pidof mysqld)Горната команда задейства автоматично възстановяване в ClusterControl:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.Докато от гледна точка на нашето тестово приложение, прекъсването се случи в следния момент при свързване към хост порт 6033 на ProxySQL:
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...Чрез разглеждане както на събитията за възстановяване, така и на изхода от нашето приложение, възелът на базата данни на MySQL не работи 4 секунди преди да започне задачата за възстановяване на клъстер, от 11:08:28 до 11:08:39, с общо престой на MySQL от 11 секунди . Едно от най-впечатляващите неща за ClusterControl е, че можете да проследявате напредъка на възстановяването на това какво действие се предприема и извършва от ClusterControl по време на отказ. Той осигурява ниво на прозрачност, което няма да можете да получите с каквито и да било предложения за бази данни от доставчици на облак.
За репликация на MySQL/MariaDB/PostgreSQL, ClusterControl ви позволява да имате по-фини данни за вашите бази данни с поддръжката на следните разширени конфигурации и параметри:
- Управление на топологията на репликация главен-главен
- Управление на топологията на репликация на верига
- Преглед на топология
- Подчинените в белия/черния списък да бъдат повишени като главен
- Проверка на грешни транзакции
- Събития преди/след, успех/неуспешно превключване/превключване с външен скрипт
- Автоматично повторно изграждане на подчинен при грешка
- Намаляване на подчинения от съществуващото резервно копие
Резюме на времето при отказ
По отношение на времето за преодоляване на отказ, Amazon RDS Aurora за MySQL е безспорният победител със 7 секунди , последвано от ClusterControl 11 секунди и Amazon RDS за MySQL с 27 секунди .
Имайте предвид, че това е просто прост тест с един клиент и една транзакция в секунда за измерване на най-бързото време за възстановяване. Големите транзакции или продължителният процес на възстановяване могат да увеличат времето за преодоляване на отказ, например продължително изпълняваните транзакции може да отнеме много време за връщане назад при изключване на MySQL.