Наскоро написахме няколко блога, обхващащи как различните доставчици на облак се справят с преодоляването на база данни. Сравнихме производителността при отказ при отказ в Amazon Aurora, Amazon RDS и ClusterControl, тествахме поведението при отказ в Amazon RDS, а също и в Google Cloud Platform. Въпреки че тези услуги предоставят страхотни опции, когато става въпрос за отказ, те може да не са подходящи за всяко приложение.
В тази публикация в блога ще отделим малко време за анализиране на плюсовете и минусите на използването на DBaaS решенията в сравнение с проектиране на среда ръчно или чрез използване на платформа за управление на база данни, като ClusterControl.
Внедряване на бази данни с висока достъпност с управлявани решения
Основната причина да използвате съществуващите решения е лекотата на използване. Можете да внедрите високодостъпно решение с автоматизиран отказ само с няколко щраквания. Няма нужда от комбиниране на различни инструменти заедно, управление на базите данни на ръка, внедряване на инструменти, писане на скриптове, проектиране на мониторинг или всякакви други операции за управление на база данни. Всичко вече е на мястото си. Това може сериозно да намали кривата на обучение и изисква по-малко опит за създаване на високодостъпна среда за базите данни; което позволява на всеки да внедри такива настройки.
В повечето случаи с тези решения процесът на отказ се изпълнява в рамките на разумно време. Може да е много бързо, както при Amazon Aurora, или малко по-бавно, както при SQL възлите на Google Cloud Platform. В повечето случаи този тип резултати са приемливи.
Долен ред. Ако можете да приемете 30 - 60 секунди престой, трябва да сте добре, като използвате някоя от платформите DBaaS.
Недостатъкът на използването на управлявано решение за HA
Въпреки че DBaaS решенията са лесни за използване, те имат и някои сериозни недостатъци. Като за начало, винаги има компонент за заключване на доставчика, който да вземете предвид. След като разположите клъстер в Amazon Web Services, е доста трудно да мигрирате от този доставчик. Няма лесни методи за изтегляне на пълния набор от данни чрез физическо архивиране. При повечето доставчици са налични само ръчно изпълнени логически архиви. Разбира се, винаги има опции за постигане на това, но обикновено това е сложен, отнемащ време процес, който все пак може да изисква известно време на престой.
Използването на доставчик като Amazon RDS също идва с ограничения. Някои действия не могат да бъдат извършени лесно, което би било много лесно за изпълнение в среди, разгърнати по напълно контролиран от потребителя начин (например AWS EC2). Някои от тези ограничения вече са разгледани в други блогове, но да обобщим е, че никоя DBaaS услуга не ви дава същото ниво на гъвкавост като обикновената MySQL GTID-базирана репликация. Можете да повишите всеки роб, можете да подчините отново всеки възел от всеки друг... практически всяко действие е възможно. С инструменти като RDS се сблъсквате с ограничения, предизвикани от дизайна, които не можете да заобиколите.
Проблемът е и в способността да се разбират подробности за производителността. Когато проектирате своя собствена високодостъпна настройка, вие ставате осведомени за потенциалните проблеми с производителността, които могат да се появят. От друга страна, RDS и подобни среди са почти „черни кутии“. Да, научихме, че Amazon RDS използва DRBD, за да създаде копие в сянка на главния, знаем, че Aurora използва споделено, репликирано хранилище, за да приложи много бързи откази. Това е само общо знание. Не можем да кажем какви са последиците за производителността на тези решения, освен това, което може да забележим случайно. Какви са често срещаните проблеми, свързани с тях? Колко стабилни са тези решения? Само разработчиците зад решението знаят със сигурност.
Каква е алтернативата на DBaaS решенията?
Може да се чудите, има ли алтернатива на DBaaS? В крайна сметка е толкова удобно да стартирате управляваната услуга, където можете да получите достъп до повечето от типичните действия чрез потребителския интерфейс. Можете да създавате и възстановявате резервни копия, отказът се обработва автоматично вместо вас. Средата е лесна за използване, което може да бъде привлекателно за компании, които нямат отдаден и опитен персонал за работа с бази данни.
ClusterControl предоставя чудесна алтернатива на базираните в облак DBaaS услуги. Той ви предоставя графичен потребителски интерфейс, който може да се използва за внедряване, управление и наблюдение на бази данни с отворен код.
С няколко щраквания можете лесно да внедрите високодостъпен клъстер от база данни с автоматично превключване (по-бързо от повечето предложения на DBaaS), управление на архивиране, разширено наблюдение и други функции като интеграция с външни инструменти (напр. Slack или PagerDuty) или управление на надстройки. Всичко това, като се избягва напълно блокирането на доставчика.
ClusterControl не се интересува къде се намират вашите бази данни, стига да може да се свърже с тях чрез SSH. Можете да имате настройки в облак, локално или в смесена среда на множество доставчици на облак. Докато има свързаност, ClusterControl ще може да управлява средата. Използването на решенията, които искате (а не тези, които не сте запознати или запознати) ви позволява да поемете пълен контрол върху околната среда във всеки един момент.
Каквато и настройка да сте внедрили с ClusterControl, можете лесно да я управлявате по по-традиционен, ръчен или скриптиран начин. ClusterControl дори ви предоставя интерфейс на командния ред, който ще ви позволи да включите задачи, изпълнявани от ClusterControl, във вашите шел скриптове. Имате целия контрол, който искате – нищо не е черна кутия, всяка част от средата ще бъде изградена с помощта на решения с отворен код, комбинирани заедно и разгърнати от ClusterControl.
Нека да разгледаме колко лесно можете да внедрите MySQL репликационен клъстер с помощта на ClusterControl. Да предположим, че имате подготвена среда с инсталиран ClusterControl на един екземпляр и всички други възли, достъпни чрез SSH от хост на ClusterControl.
Ще започнем с избора на съветника „Разгръщане“.
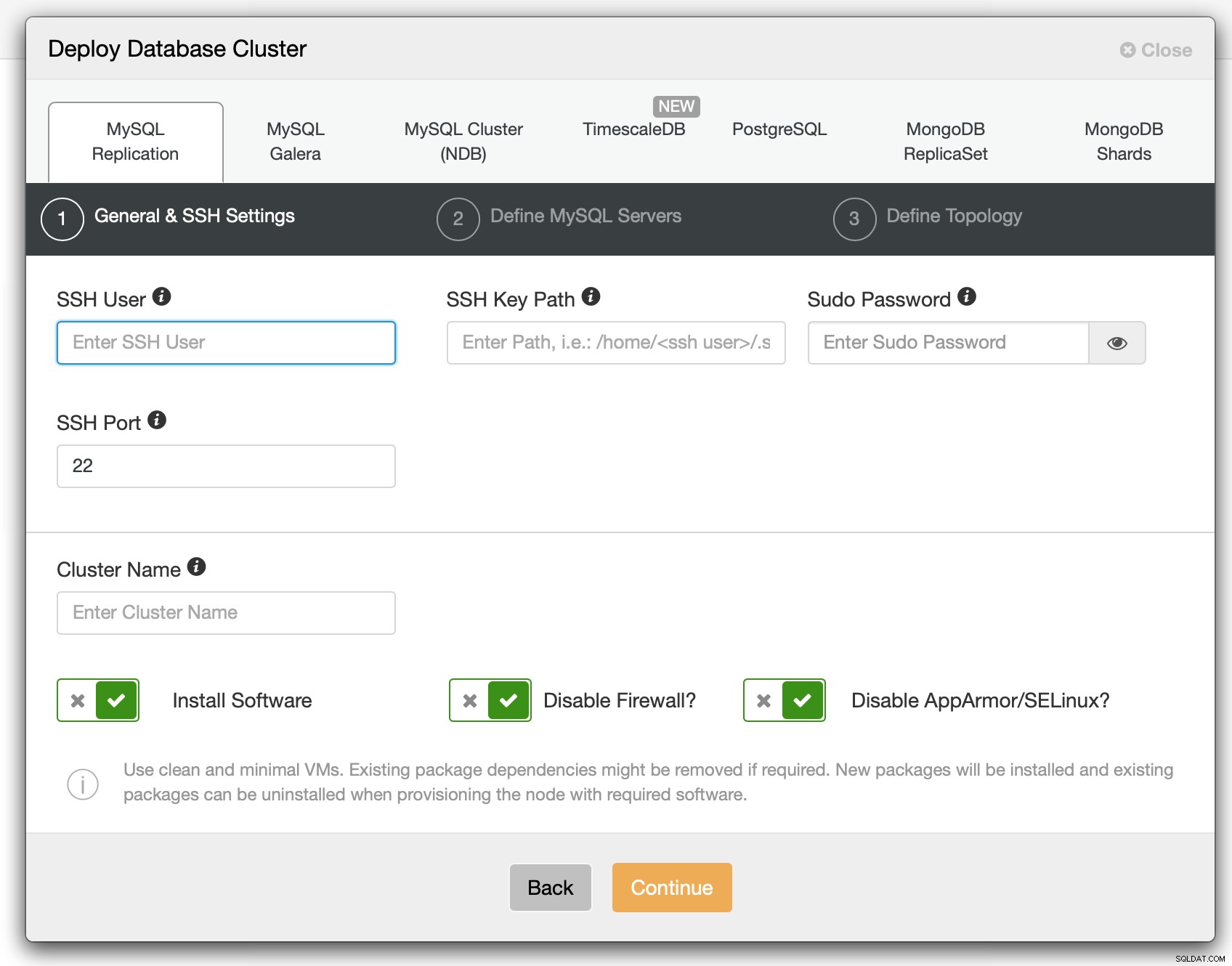
На първата стъпка трябва да дефинираме как ClusterControl трябва да се свързва с възлите на които базите данни трябва да бъдат разгърнати. Поддържат се както root достъп, така и sudo (със или без парола).
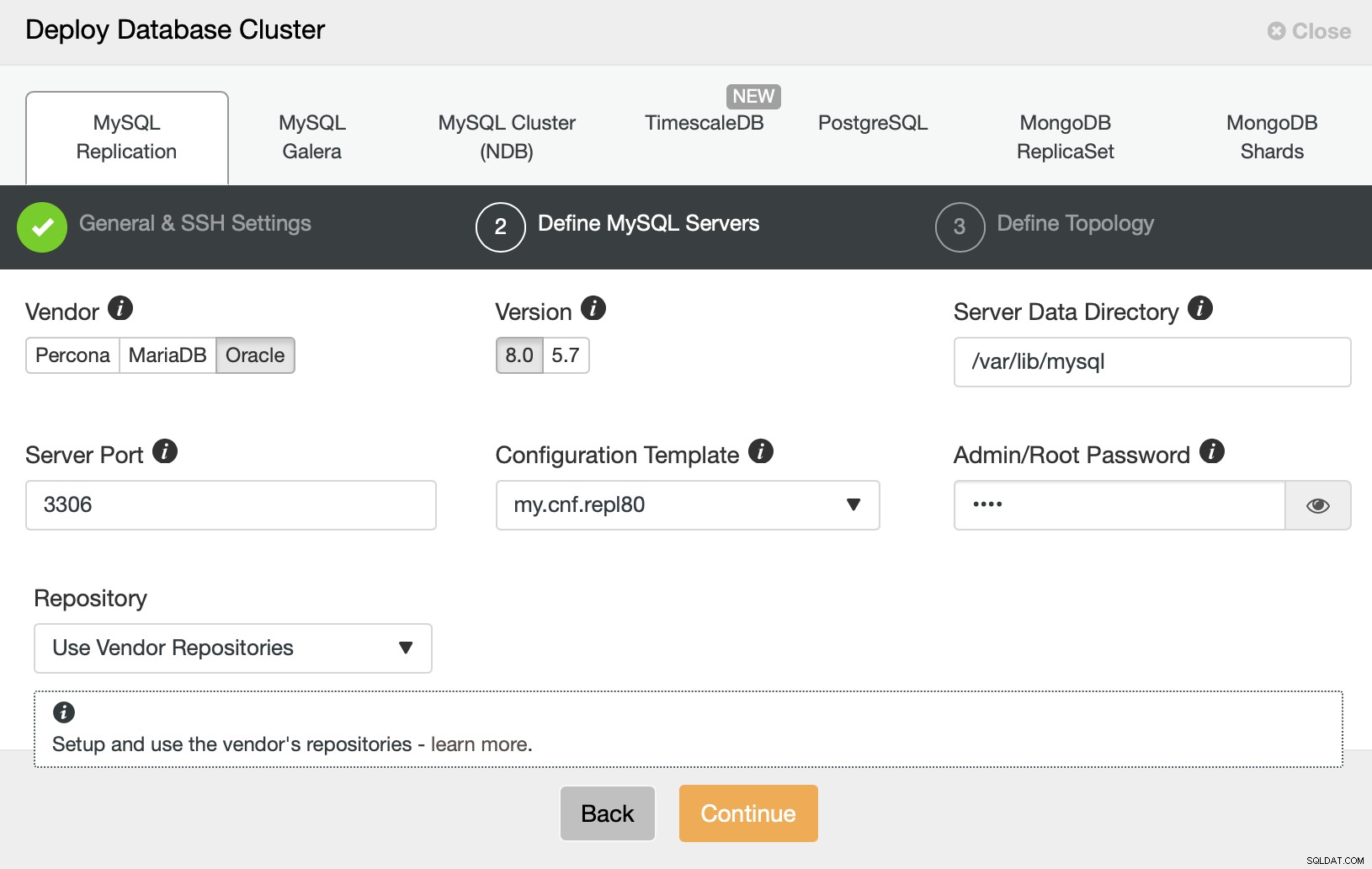
След това искаме да изберем доставчик, версия и да предадем паролата за администраторския потребител в нашата MySQL база данни.
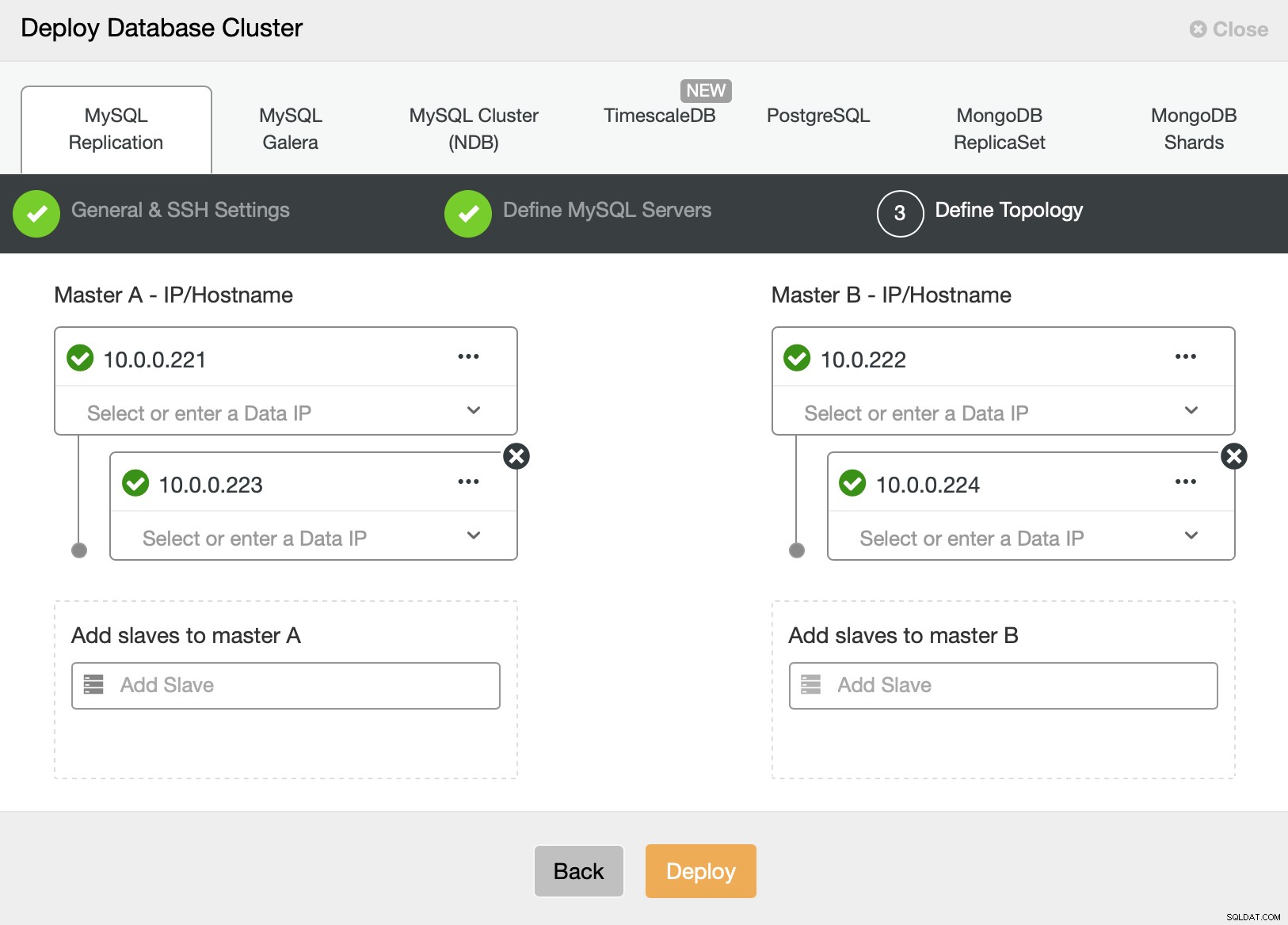
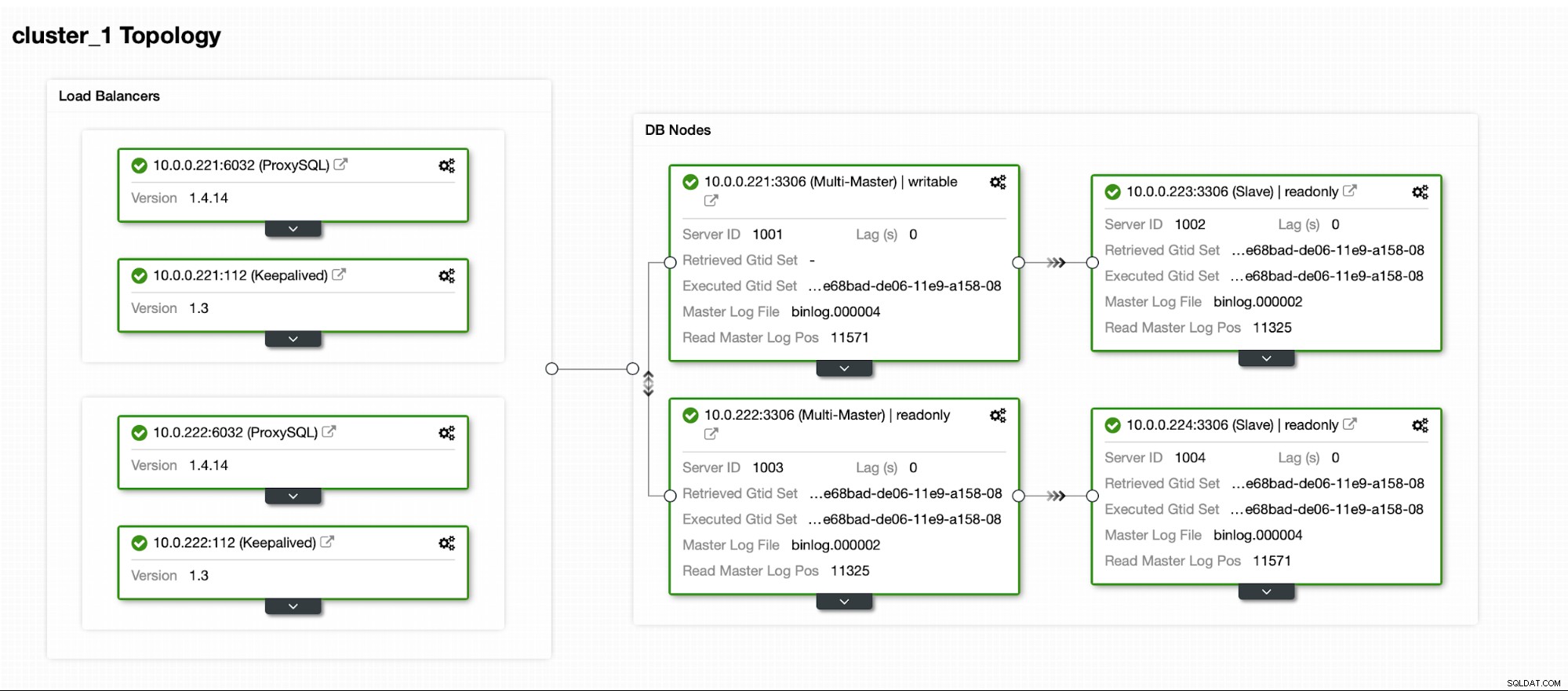
Накрая искаме да дефинираме топологията за нашия нов клъстер. Както можете да видите, това вече е доста сложна настройка, за разлика от нещо, което можете да разгърнете с помощта на AWS RDS или GCP SQL възел.
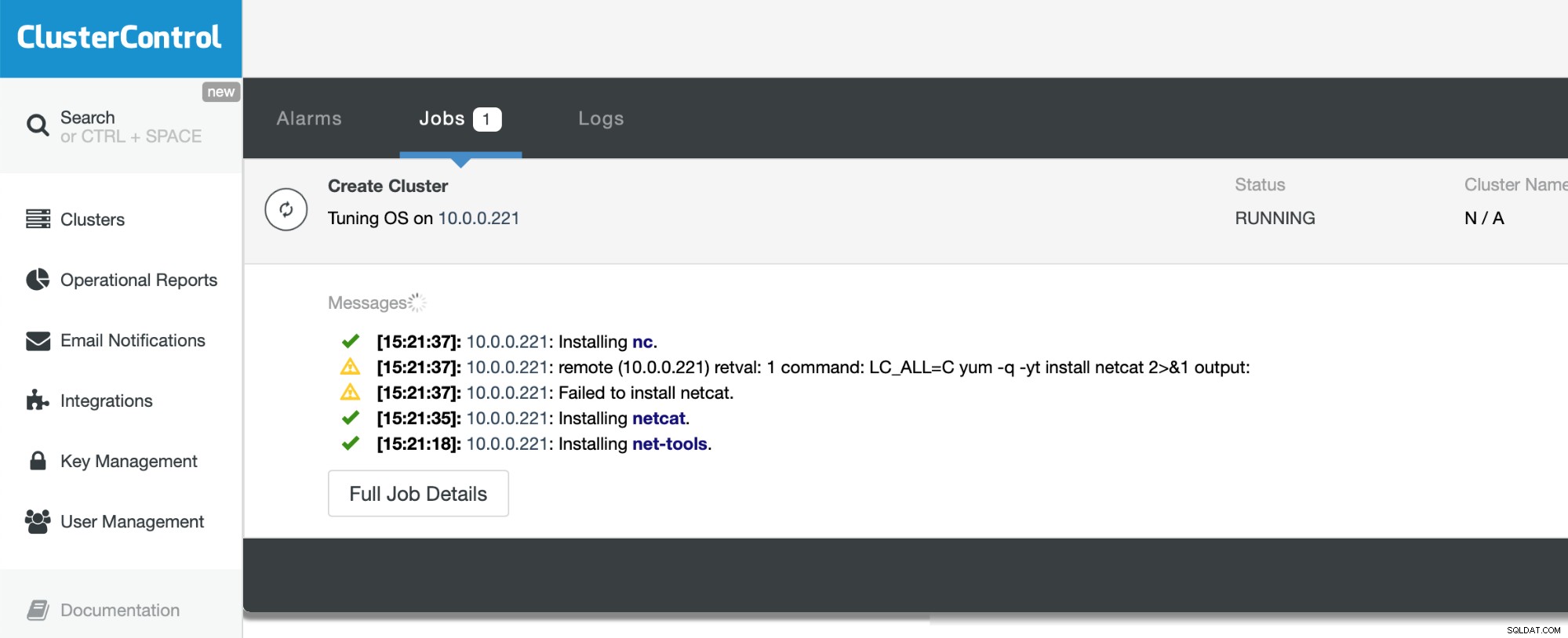
Всичко, което трябва да направим сега, е да изчакаме процеса да завърши. ClusterControl ще направи всичко възможно, за да разбере средата, в която внедрява, и да инсталира необходимия набор от пакети, включително самата база данни.

След като клъстерът започне да работи, можете да продължите с внедряването прокси слоя (който ще осигури на вашето приложение една точка на влизане в слоя на базата данни). Това е горе-долу това, което се случва зад кулисите с DBaaS, където също имате крайни точки за свързване към клъстера на базата данни. Доста обичайно е да се използва една крайна точка за запис и множество крайни точки за достигане на определени реплики.
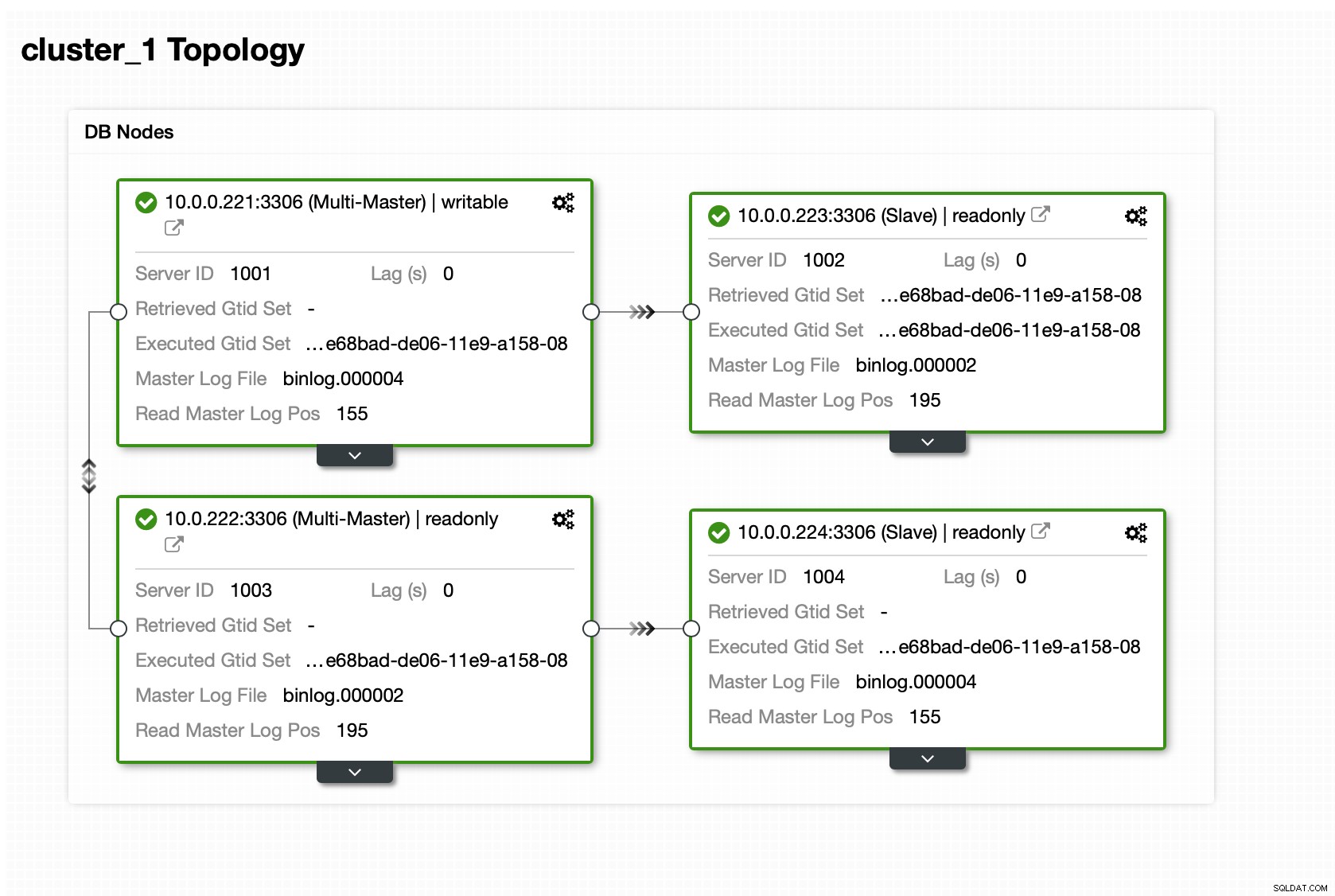
Тук ще използваме ProxySQL, който ще свърши мръсната работа вместо нас - той ще разбере топологията, изпраща записи само до главната и заявки за балансиране на натоварването само за четене във всички реплики, които имаме.
За да разположим ProxySQL, ще отидем на Управление -> Балансьори на натоварване.
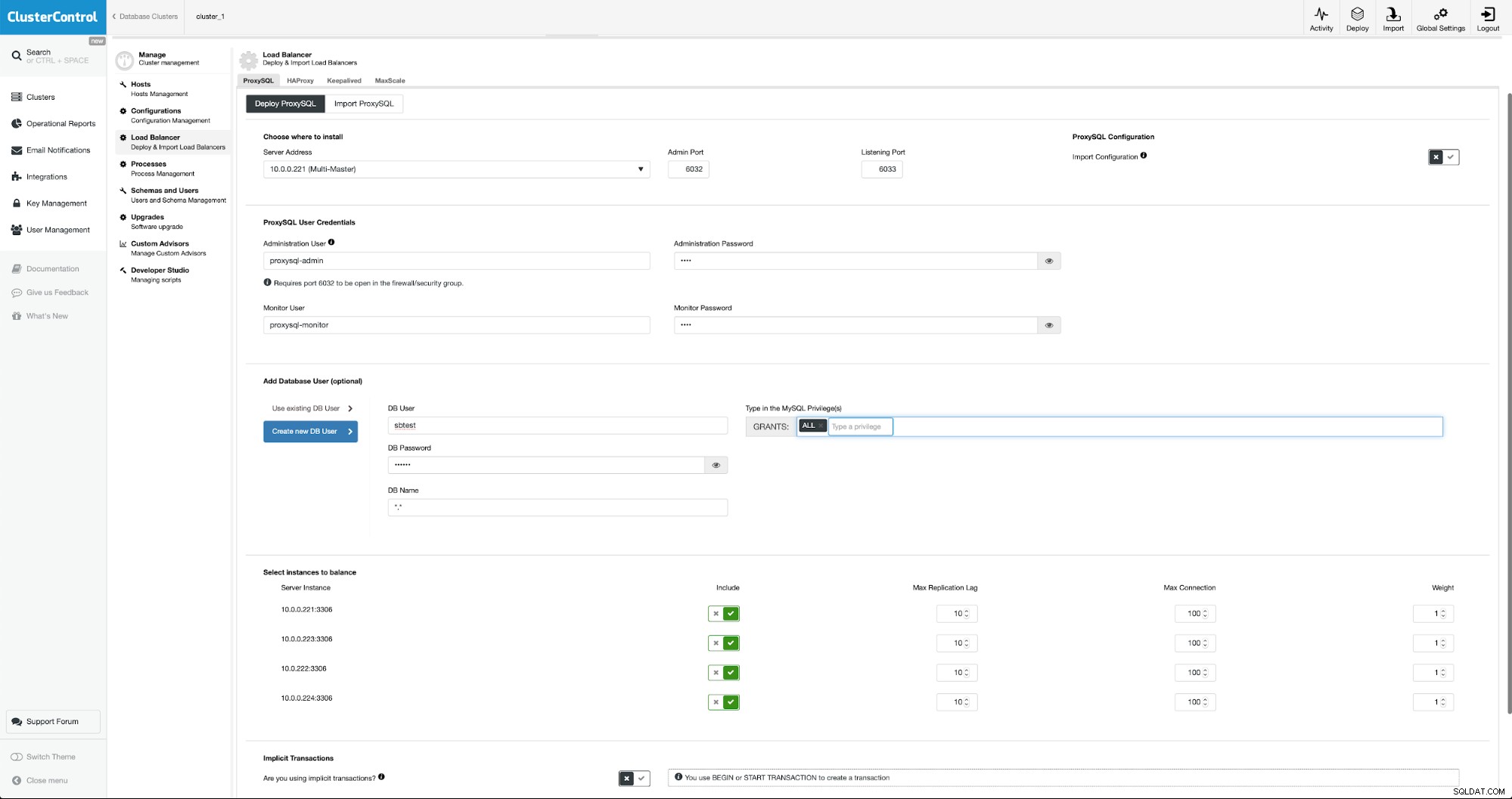
Трябва да попълним всички задължителни полета:хостове за внедряване, идентификационни данни за административния и наблюдаващ потребител, можем да импортираме съществуващ потребител от MySQL в ProxySQL или да създадем нов. Всички подробности за ProxySQL могат лесно да бъдат намерени в множество блогове в нашия блог раздел.
Искаме да бъдат внедрени поне два възела на ProxySQL, за да се гарантира висока наличност. След това, след като бъдат внедрени, ще разположим Keepalived върху ProxySQL. Това ще гарантира, че виртуалният IP ще бъде конфигуриран и ще сочи към един от екземплярите на ProxySQL, стига да има поне един здрав възел.
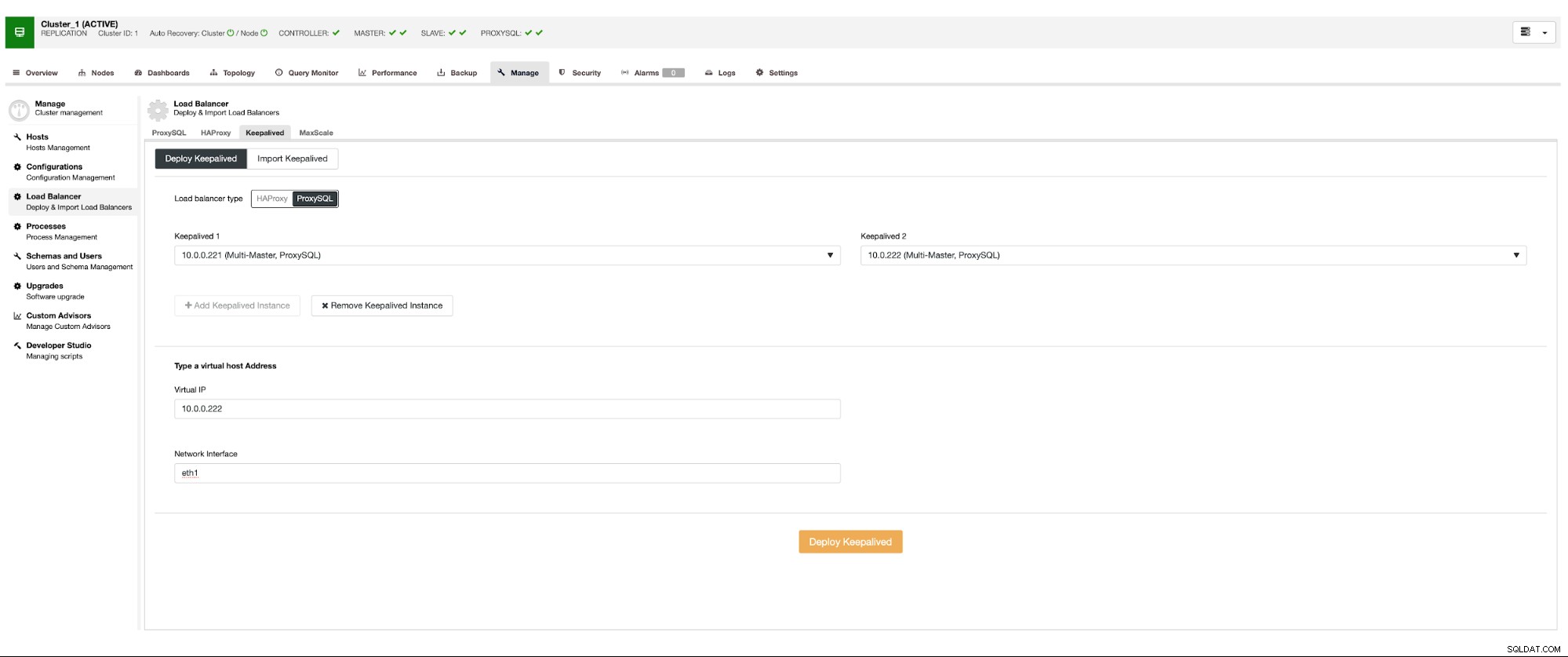
Ето единственият потенциален проблем, ако използвате облачни среди, където маршрутизирането работи по начин, по който не можете лесно да изведете мрежов интерфейс. В такъв случай ще трябва да промените конфигурацията на Keepalived, да въведете скрипт 'notify_master' и да използвате скрипт, който ще направи необходимите IP промени - в случай на EC2 ще трябва да отдели Elastic IP от един хост и да го прикачи към друг хост.
Има много инструкции как да направите това с помощта на широко тестван софтуер с отворен код в настройки, внедрени от ClusterControl. Можете лесно да намерите допълнителна информация, съвети и практически инструкции, които са подходящи за вашата конкретна среда.
Заключение
Надяваме се, че сте намерили тази публикация в блога проницателна. Ако искате да тествате ClusterControl, той идва с 30-дневна корпоративна пробна версия, при която имате налични всички функции. Можете да го изтеглите безплатно и да тествате дали се вписва във вашата среда.