Galera Cluster 4.0 беше пуснат за първи път като част от MariaDB 10.4 и има много значителни подобрения в тази версия. Най-впечатляващата функция в тази версия е поточно репликацията, която е предназначена да се справи със следните проблеми.
- Проблеми с дълги транзакции
- Проблеми с големи транзакции
- Проблеми с горещи точки в таблиците
В предишен блог се задълбочихме в новата функция за поточно репликация в блог от две части (част 1 и част 2). Част от тази нова функция в Galera 4.0 са нови системни таблици, които са много полезни за запитване и проверка на възлите на Galera Cluster, както и регистрационните файлове, които са били обработени в Streaming Replication.
Също така в предишни блогове, ние също ви показахме лесния начин за внедряване на MySQL Galera Cluster на AWS, както и как да внедрите MySQL Galera Cluster 4.0 в Amazon AWS EC2.
Percona все още не е пуснала GA за своя Percona XtraDB Cluster (PXC) 8.0, тъй като някои функции все още са в процес на разработка, като функцията wsrep на MySQL WSREP_SYNC_WAIT_UPTO_GTID, която изглежда все още не е налице (поне на PXC 8.0.15-5-27dev.4.2 версия). И все пак, когато PXC 8.0 ще бъде пуснат, той ще бъде пълен със страхотни функции като...
- Подобрен устойчив клъстер
- Удобен за облака клъстер
- подобрена опаковка
- Поддръжка на криптиране
- Atomic DDL
Докато чакаме пускането на PXC 8.0 GA, в този блог ще разгледаме как можете да създадете възел за горещ режим на готовност на Amazon AWS за Galera Cluster 4.0 с помощта на MariaDB.
Какво е горещ режим на готовност?
Горещ режим на готовност е често срещан термин в компютрите, особено при силно разпределени системи. Това е метод за резервиране, при който една система работи едновременно с идентична първична система. Когато възникне повреда на първичния възел, горещата готовност незабавно поема подмяната на първичната система. Данните се отразяват и в двете системи в реално време.
За системи с бази данни, сървърът с гореща готовност обикновено е вторият възел след основния главен, който работи на мощни ресурси (същото като главния). Този вторичен възел трябва да е толкова стабилен, колкото и основният главен, за да функционира правилно.
Той също така служи като възел за възстановяване на данни, ако главният възел или целият клъстер се повреди. Възелът за гореща готовност ще замени неизправния възел или клъстер, докато непрекъснато обслужва търсенето от клиентите.
В Galera Cluster всички сървъри, част от клъстера, могат да служат като резервен възел. Въпреки това, ако регионът или целият клъстер падне, как ще можете да се справите с това? Създаването на възел в режим на готовност извън конкретния регион или мрежа на вашия клъстер е една от възможностите тук.
В следващия раздел ще ви покажем как да създадете възел в режим на готовност на AWS EC2 с помощта на MariaDB.
Внедряване на горещ режим на готовност на Amazon AWS
По-рано ви показахме как можете да създадете клъстер Galera в AWS. Може да искате да прочетете Разгръщане на MySQL Galera Cluster 4.0 в Amazon AWS EC2 в случай, че сте нов в Galera 4.0.
Разгръщането на вашия възел за горещ режим на готовност може да бъде на друг набор от Galera Cluster, който използва синхронна репликация (вижте този блог Нулева миграция на мрежа по време на престой с MySQL Galera Cluster с помощта на Relay Node) или чрез внедряване на асинхронен MySQL/MariaDB възел . В този блог ще настроим и разгърнем възела за гореща готовност, репликиращ се асинхронно от един от възлите на Galera.
Настройката на клъстера Galera
В тази примерна настройка разположихме клъстер с 3 възли, използвайки версия на MariaDB 10.4.8. Този клъстер се внедрява в региона на Изтока на САЩ (Охайо) и топологията е показана по-долу:
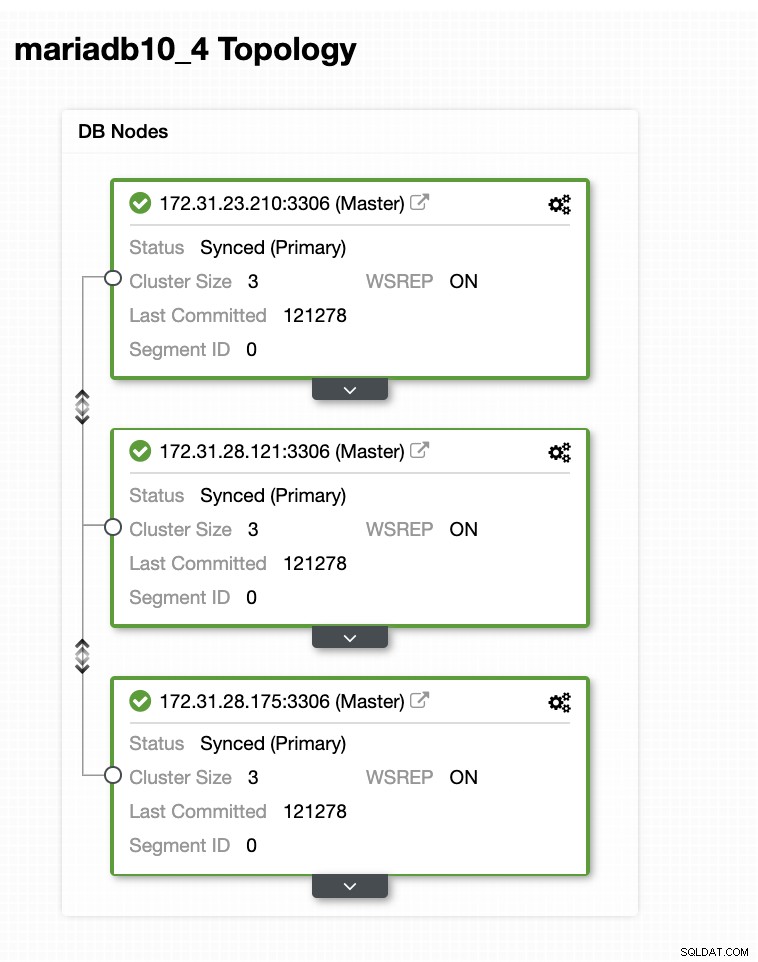
Ще използваме 172.31.26.175 сървър като главен за нашия асинхронен подчинен който ще служи като възел в режим на готовност.
Настройване на вашия EC2 екземпляр за Hot Standby Node
В конзолата на AWS отидете на EC2, намиращ се в секцията Compute, и щракнете върху Стартиране на екземпляр, за да създадете EC2 екземпляр, както е по-долу.
Ще създадем този екземпляр в региона на САЩ Запад (Орегон). За вашия тип ОС можете да изберете какъв сървър харесвате (предпочитам Ubuntu 18.04) и да изберете типа инстанция въз основа на предпочитания от вас тип цел. За този пример ще използвам t2.micro, тъй като не изисква никаква сложна настройка и е само за това примерно внедряване.
Както споменахме по-рано, най-добре е вашият възел за горещ режим на готовност да се намира в различен регион, а не да е разположен в един и същи регион. Така че, в случай че регионалният център за данни се повреди или претърпи прекъсване на мрежата, вашият горещ режим на готовност може да бъде вашата цел за превключване при отказ, когато нещата се объркат.
Преди да продължим, в AWS различните региони ще имат собствен виртуален частен облак (VPC) и собствена мрежа. За да комуникираме с клъстерните възли на Galera, първо трябва да дефинираме VPC Peering, така че възлите да могат да комуникират в рамките на инфраструктурата на Amazon и да не е необходимо да излизат извън мрежата, което само добавя допълнителни проблеми и опасения за сигурността.
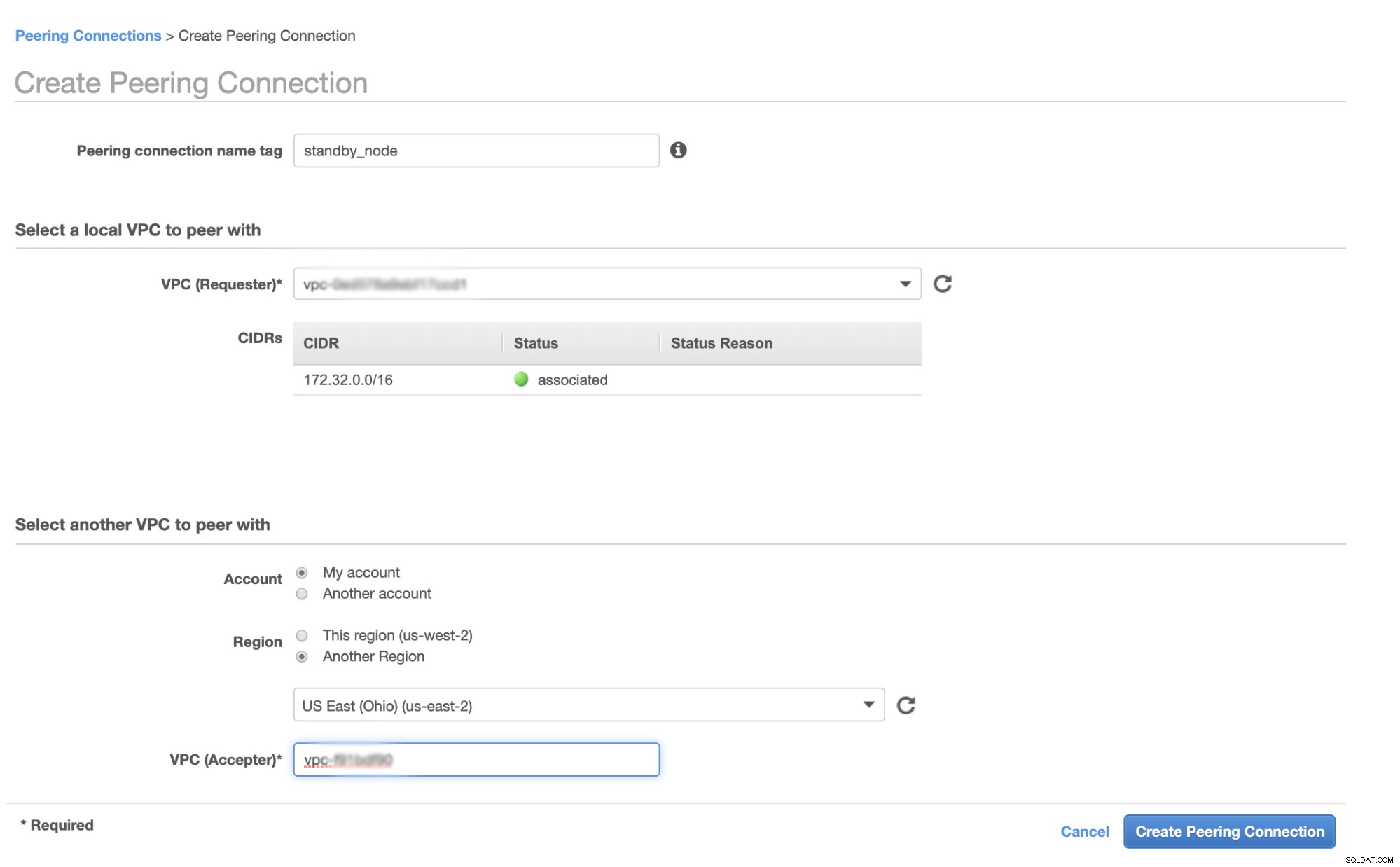
Първо отидете на вашия VPC, откъдето ще се намира вашият възел за горещ режим на готовност, след това отидете на Peering Connections. След това трябва да посочите VPC на вашия възел в режим на готовност и VPC на клъстера Galera. В примера по-долу имам us-west-2, който се свързва помежду си с us-east-2.
След като създадете, ще видите запис под вашите Peering Connections. Трябва обаче да приемете заявката от VPC клъстера на Galera, който е на us-east-2 в този пример. Вижте по-долу,
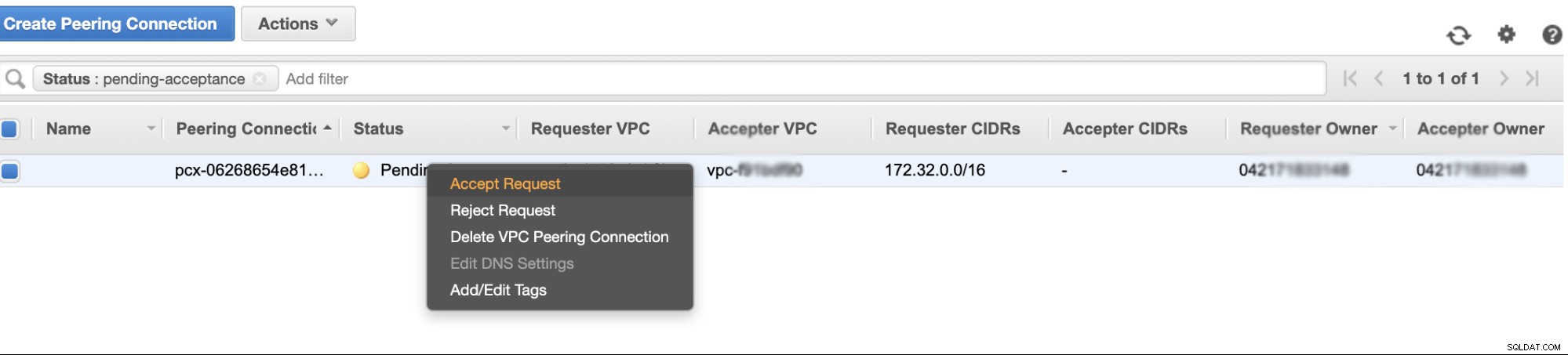
След като бъде приет, не забравяйте да добавите CIDR към таблицата за маршрутизиране. Вижте този външен блог VPC Peering за това как да го направите след VPC Peering.
Сега нека се върнем назад и да продължим да създаваме възела EC2. Уверете се, че вашата група за сигурност има правилните правила или необходими портове, които трябва да бъдат отворени. Проверете ръководството за настройки на защитната стена за повече информация относно това. За тази настройка просто настроих Целият трафик да се приема, тъй като това е само тест. Вижте по-долу,
Уверете се, че когато създавате своя екземпляр, сте задали правилния VPC и са дефинирали вашата правилна подмрежа. Можете да проверите този блог, в случай че имате нужда от помощ за това.
Настройка на MariaDB Async Slave
Първа стъпка
Първо трябва да настроим хранилището, да добавим ключовете за репозитория и да актуализираме списъка с пакети в кеша на хранилището,
$ vi /etc/apt/sources.list.d/mariadb.list
$ apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xF1656F24C74CD1D8
$ apt updateВтора стъпка
Инсталирайте пакетите MariaDB и необходимите за него двоични файлове
$ apt-get install mariadb-backup mariadb-client mariadb-client-10.4 libmariadb3 libdbd-mysql-perl mariadb-client-core-10.4 mariadb-common mariadb-server-10.4 mariadb-server-core-10.4 mysql-commonТрета стъпка
Сега, нека направим резервно копие, използвайки xbstream, за да прехвърлим файловете в мрежата от един от възлите в нашия клъстер Galera.
## Изтрийте директорията с данни на новоинсталирания MySQL във вашия възел за гореща готовност.
$ systemctl stop mariadb
$ rm -rf /var/lib/mysql/*## След това на възела за горещ режим на готовност стартирайте това на терминала,
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | mbstream -x -C /var/lib/mysql## След това на целевия master, т.е. един от възлите във вашия Galera Cluster (който е възелът 172.31.28.175 в този пример), изпълнете това на терминала,
$ mariabackup --backup --target-dir=/tmp --stream=xbstream | socat - TCP4:172.32.31.2:9999където 172.32.31.2 е IP адресът на хоста в готовност.
Четвърта стъпка
Подгответе своя MySQL конфигурационен файл. Тъй като това е в Ubuntu, редактирам файла в /etc/mysql/my.cnf и със следния пример my.cnf, взет от нашия шаблон ClusterControl,
[MYSQLD]
user=mysql
basedir=/usr/
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
pid_file=/var/lib/mysql/mysql.pid
port=3306
log_error=/var/log/mysql/mysqld.log
log_warnings=2
# log_output = FILE
#Slow logging
slow_query_log_file=/var/log/mysql/mysql-slow.log
long_query_time=2
slow_query_log=OFF
log_queries_not_using_indexes=OFF
### INNODB OPTIONS
innodb_buffer_pool_size=245M
innodb_flush_log_at_trx_commit=2
innodb_file_per_table=1
innodb_data_file_path = ibdata1:100M:autoextend
## You may want to tune the below depending on number of cores and disk sub
innodb_read_io_threads=4
innodb_write_io_threads=4
innodb_doublewrite=1
innodb_log_file_size=64M
innodb_log_buffer_size=16M
innodb_buffer_pool_instances=1
innodb_log_files_in_group=2
innodb_thread_concurrency=0
# innodb_file_format = barracuda
innodb_flush_method = O_DIRECT
innodb_rollback_on_timeout=ON
# innodb_locks_unsafe_for_binlog = 1
innodb_autoinc_lock_mode=2
## avoid statistics update when doing e.g show tables
innodb_stats_on_metadata=0
default_storage_engine=innodb
# CHARACTER SET
# collation_server = utf8_unicode_ci
# init_connect = 'SET NAMES utf8'
# character_set_server = utf8
# REPLICATION SPECIFIC
server_id=1002
binlog_format=ROW
log_bin=binlog
log_slave_updates=1
relay_log=relay-bin
expire_logs_days=7
read_only=ON
report_host=172.31.29.72
gtid_ignore_duplicates=ON
gtid_strict_mode=ON
# OTHER THINGS, BUFFERS ETC
key_buffer_size = 24M
tmp_table_size = 64M
max_heap_table_size = 64M
max_allowed_packet = 512M
# sort_buffer_size = 256K
# read_buffer_size = 256K
# read_rnd_buffer_size = 512K
# myisam_sort_buffer_size = 8M
skip_name_resolve
memlock=0
sysdate_is_now=1
max_connections=500
thread_cache_size=512
query_cache_type = 0
query_cache_size = 0
table_open_cache=1024
lower_case_table_names=0
# 5.6 backwards compatibility (FIXME)
# explicit_defaults_for_timestamp = 1
performance_schema = OFF
performance-schema-max-mutex-classes = 0
performance-schema-max-mutex-instances = 0
[MYSQL]
socket=/var/lib/mysql/mysql.sock
# default_character_set = utf8
[client]
socket=/var/lib/mysql/mysql.sock
# default_character_set = utf8
[mysqldump]
socket=/var/lib/mysql/mysql.sock
max_allowed_packet = 512M
# default_character_set = utf8
[xtrabackup]
[MYSQLD_SAFE]
# log_error = /var/log/mysqld.log
basedir=/usr/
# datadir = /var/lib/mysqlРазбира се, можете да промените това според вашите настройки и изисквания.
Стъпка пета
Подгответе резервното копие от стъпка #3, т.е. крайното архивиране, което сега е във възела на гореща готовност, като изпълните командата по-долу,
$ mariabackup --prepare --target-dir=/var/lib/mysqlСтъпка шеста
Задайте собствеността върху datadir в възела за горещ режим на готовност,
$ chown -R mysql.mysql /var/lib/mysqlСтъпка седма
Сега стартирайте екземпляра на MariaDB
$ systemctl start mariadbСтъпка осма
Накрая трябва да настроим асинхронната репликация,
## Създайте потребителя за репликация на главния възел, т.е. възела в клъстера Galera
MariaDB [(none)]> CREATE USER 'cmon_replication'@'172.32.31.2' IDENTIFIED BY 'PahqTuS1uRIWYKIN';
Query OK, 0 rows affected (0.866 sec)
MariaDB [(none)]> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'cmon_replication'@'172.32.31.2';
Query OK, 0 rows affected (0.127 sec)## Вземете подчинената позиция на GTID от xtrabackup_binlog_info, както следва,
$ cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000002 71131632 1000-1000-120454## След това настройте подчинената репликация, както следва,
MariaDB [(none)]> SET GLOBAL gtid_slave_pos='1000-1000-120454';
Query OK, 0 rows affected (0.053 sec)
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='172.31.28.175', MASTER_USER='cmon_replication', master_password='PahqTuS1uRIWYKIN', MASTER_USE_GTID = slave_pos;## Сега проверете състоянието на подчинения,
MariaDB [(none)]> show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.31.28.175
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 60
Master_Log_File:
Read_Master_Log_Pos: 4
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 4
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-120454
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)Добавяне на вашия горещ резервен възел към ClusterControl
Ако използвате ClusterControl, е лесно да наблюдавате здравето на сървъра на базата данни. За да добавите това като подчинен, изберете клъстера от възли Galera, който имате, след което отидете на бутона за избор, както е показано по-долу, за да добавите подчинен репликация:
Щракнете върху Add Replication Slave и изберете добавяне на съществуващ подчинен, както по-долу,
Нашата топология изглежда обещаваща.
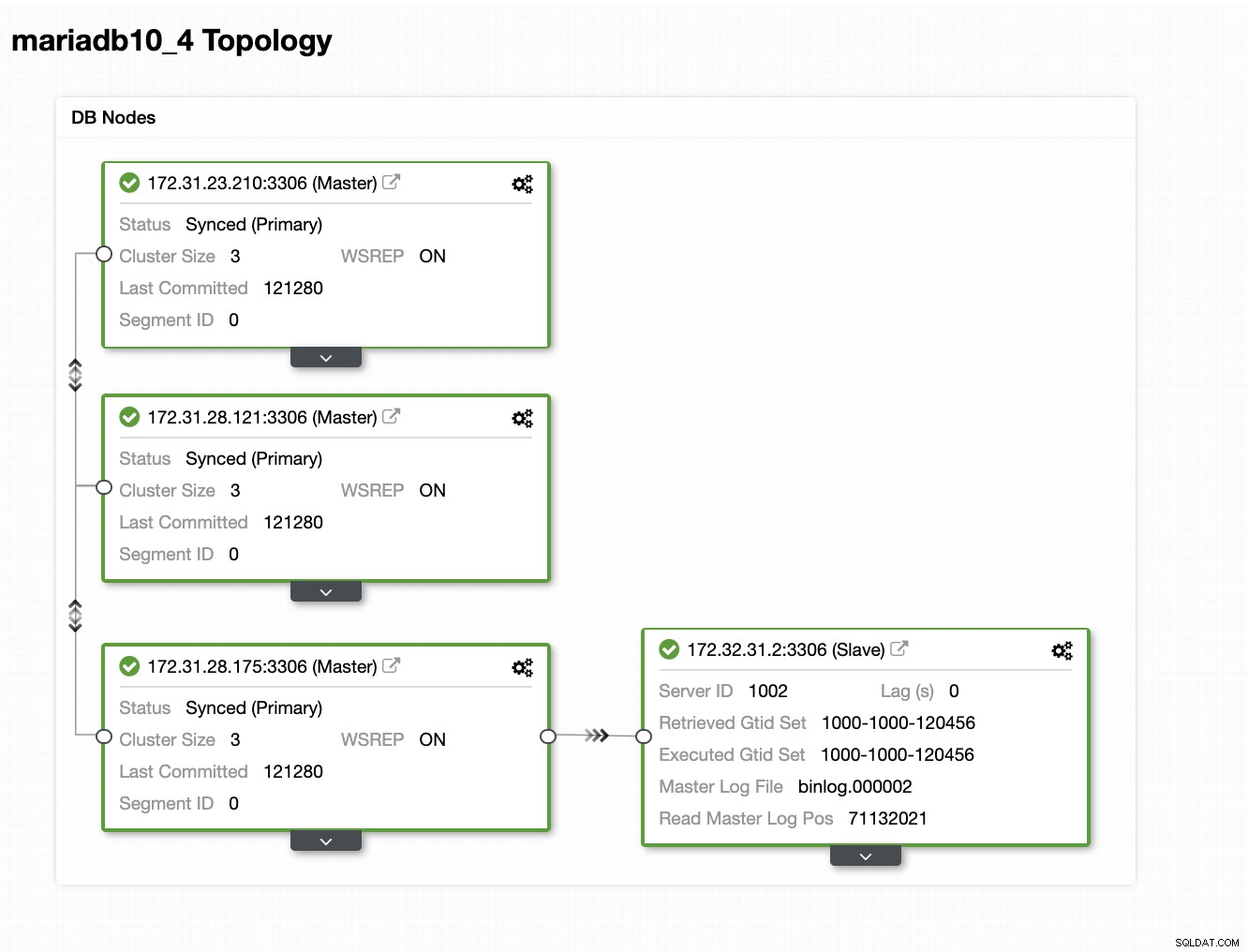
Както може да забележите, нашият възел 172.32.31.2 служи като нашия горещ режим на готовност възел има различен CIDR, който има префикси като 172.32.% us-west-2 (Орегон), докато другите възли са с 172.31.% разположени на us-east-2 (Охайо). Те са изцяло в различен регион, така че в случай, че възникне повреда в мрежата на вашите възли на Galera, можете да преминете при отказ към вашия възел за горещ режим на готовност.
Заключение
Изграждането на горещ режим на готовност на Amazon AWS е лесно и просто. Всичко, от което се нуждаете, е да определите изискванията си за капацитет и вашата мрежова топология, сигурност и протоколи, които трябва да бъдат настроени.
Използването на VPC Peering помага да се ускори комуникацията между различни региони, без да се влиза в публичен интернет, така че връзката остава в рамките на мрежовата инфраструктура на Amazon.
Използването на асинхронна репликация с един подчинен, разбира се, не е достатъчно, но този блог служи като основа за това как можете да инициирате това. Вече можете лесно да създадете друг клъстер, където асинхронното подчинено устройство се реплицира, и да създадете друга серия от клъстери на Galera, служещи като ваши възли за възстановяване след бедствие, или можете също да използвате променлива gmcast.segment в Galera, за да репликирате синхронно точно както това, което имаме в този блог.