Високата наличност е висок процент от време, през което системата работи и реагира според нуждите на бизнеса. За системите с производствени бази данни обикновено най-висок приоритет е да се поддържа близо до 100%. Ние изграждаме клъстери на база данни, за да елиминираме всички единични точки на повреда. Ако даден екземпляр стане недостъпен, друг възел трябва да може да поеме натоварването и да продължи оттам. В един перфектен свят клъстерът от база данни би разрешил всички наши проблеми с наличността на системата. За съжаление, макар всичко да изглежда добре на хартия, реалността често е различна. И така, къде може да се обърка?
Системите за транзакционни бази данни се предлагат със сложни машини за съхранение. Поддържането на последователност на данните в множество възли прави тази задача много по-трудна. Клъстерирането въвежда редица нови променливи, които силно зависят от мрежата и основната инфраструктура. Не е необичайно самостоятелен екземпляр на база данни, който работи добре на един възел, внезапно се представя лошо в клъстерна среда.
Сред многото неща, които могат да повлияят на наличността на клъстера, проблемите с латентността играят решаваща роля. Каква е обаче латентността? Свързано ли е само с мрежата?
Терминът "латентност" всъщност се отнася до няколко вида закъснения, възникнали при обработката на данни. Това е колко време отнема дадена информация да премине от етап към друг.
В тази публикация в блога ще разгледаме двете основни решения за висока достъпност за MySQL и MariaDB и как всяко от тях може да бъде засегнато от проблеми със закъснението.
В края на статията ще разгледаме съвременните балансери на натоварването и ще обсъдим как те могат да ви помогнат да решите някои видове проблеми с латентността.
В предишна статия моят колега Кшищоф Ксионжек писа за „Справяне с ненадеждни мрежи при изработване на HA решение за MySQL или MariaDB“. Ще намерите съвети, които могат да ви помогнат да проектирате вашата готова за производство HA архитектура и да избегнете някои от проблемите, описани тук.
Репликация главен-подчинен за висока наличност.
MySQL главен-подчинен репликация е може би най-популярният тип клъстер на база данни на планетата. Едно от основните неща, които искате да наблюдавате, докато изпълнявате своя главен-подчинен клъстер за репликация, е забавянето на подчинените. В зависимост от изискванията на вашето приложение и начина, по който използвате вашата база данни, латентността на репликация (подчинено забавяне) може да определи дали данните могат да бъдат прочетени от подчинения възел или не. Данните, предоставени на главен, но все още не са налични на асинхронно подчинено устройство, означават, че ведомото има по-старо състояние. Когато не е добре да четете от подчинен, ще трябва да отидете при главния и това може да повлияе на производителността на приложението. В най-лошия случай вашата система няма да може да се справи с цялото натоварване на главен.
Подчинено забавяне и остарели данни
За да проверите състоянието на репликацията главен-подчинен, трябва да започнете с командата по-долу:
SHOW SLAVE STATUS\G
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.3.100
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000021
Read_Master_Log_Pos: 5101
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 809
Relay_Master_Log_File: binlog.000021
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 5101
Relay_Log_Space: 1101
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3-1179
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.01 sec)Използвайки горната информация, можете да определите колко добра е цялостната латентност на репликация. Колкото по-ниска е стойността, която виждате в „Seconds_Behind_Master“, толкова по-добра е скоростта на пренос на данни за репликация.
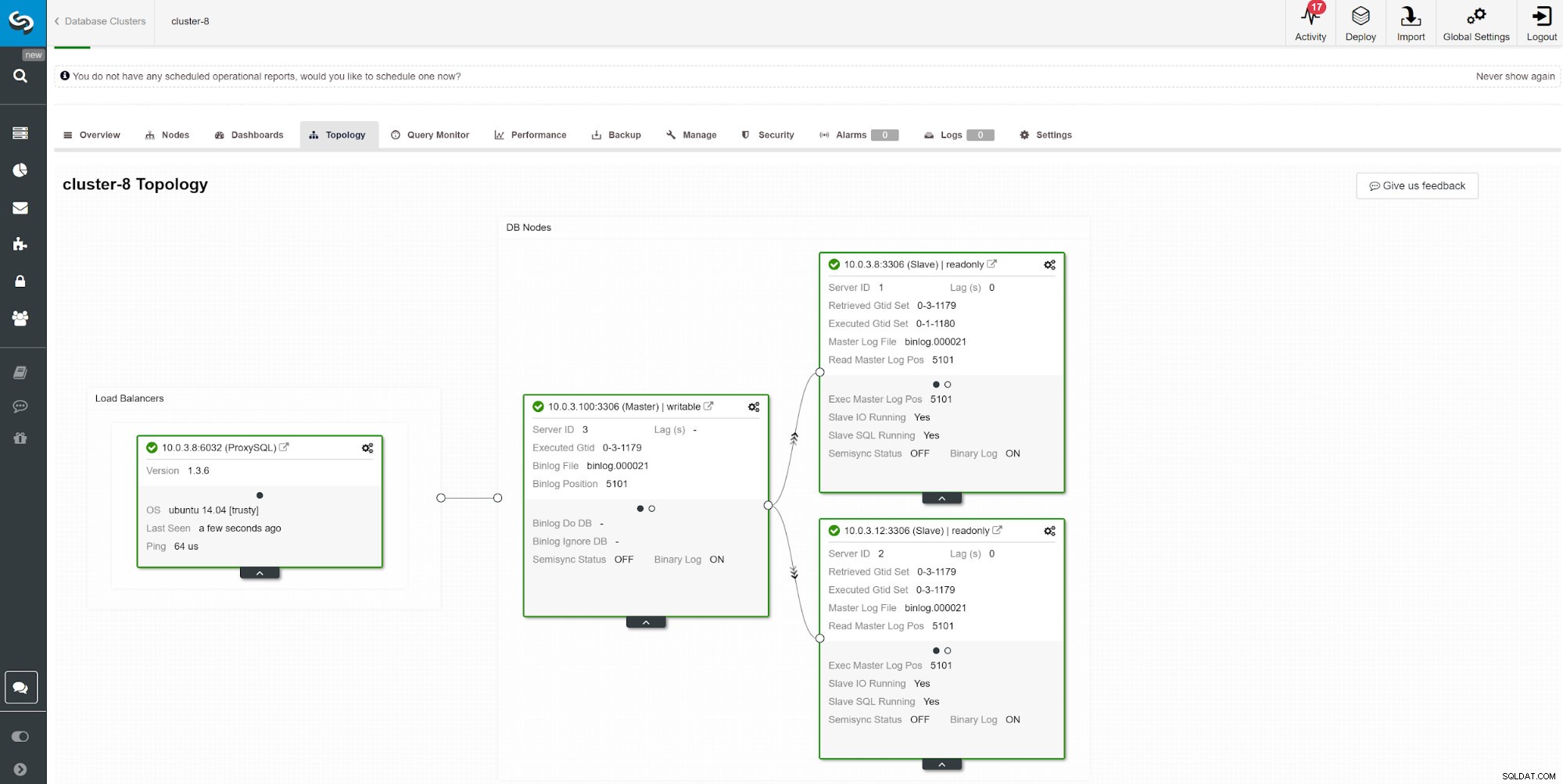 Друг начин за наблюдение на подчинено забавяне е да използвате мониторинг на репликацията на ClusterControl. На тази екранна снимка можем да видим състоянието на репликация на асимхронния главен-подчинен (2x) клъстер с ProxySQL.
Друг начин за наблюдение на подчинено забавяне е да използвате мониторинг на репликацията на ClusterControl. На тази екранна снимка можем да видим състоянието на репликация на асимхронния главен-подчинен (2x) клъстер с ProxySQL. Има редица неща, които могат да повлияят на времето за репликация. Най-очевидното е пропускателната способност на мрежата и колко данни можете да прехвърлите. MySQL идва с множество опции за конфигурация за оптимизиране на процеса на репликация. Основните параметри, свързани с репликацията, са:
- Прилага се паралелно
- Алгоритъм за логически часовник
- Компресия
- Селективна репликация главен-подчинен
- Режим на репликация
Прилага се паралелно
Не е необичайно да започнете настройката на репликацията с активиране на прилагането на паралелен процес. Причината за това е по подразбиране, MySQL върви с последователно прилагане на двоичен дневник, а типичният сървър на база данни идва с няколко CPU за използване.
За да заобиколите прилагането на последователен дневник, MariaDB и MySQL предлагат паралелна репликация. Реализацията може да се различава в зависимост от доставчика и версията. напр. MySQL 5.6 предлага паралелна репликация, докато една схема разделя заявките, докато MariaDB (начална версия 10.0) и MySQL 5.7 могат да обработват паралелна репликация между схеми. Различните доставчици и версии идват със своите ограничения и функции, така че винаги проверявайте документацията.
Изпълнението на заявки чрез паралелни подчинени нишки може да ускори вашия репликационен поток, ако пишете тежко. Ако обаче не сте, би било най-добре да се придържате към традиционната еднонишкова репликация. За да активирате паралелна обработка, променете slave_parallel_workers на броя на процесорните нишки, които искате да включите в процеса. Препоръчително е да запазите стойността по-ниска от броя на наличните нишки на процесора.
Паралелната репликация работи най-добре с груповите ангажименти. За да проверите дали имате групови ангажименти, изпълнете следната заявка.
show global status like 'binlog_%commits';Колкото по-голямо е съотношението между тези две стойности, толкова по-добре.
Логически часовник
Slave_parallel_type=LOGICAL_CLOCK е реализация на часовников алгоритъм на Lamport. Когато се използва многонишков подчинен, тази променлива указва метода, използван за решаване на кои транзакции е разрешено да се изпълняват паралелно на подчинения. Променливата няма ефект върху подчинени устройства, за които многонишковостта не е активирана, така че се уверете, че slave_parallel_workers е зададено по-високо от 0.
Потребителите на MariaDB също трябва да проверят оптимистичния режим, въведен във версия 10.1.3, тъй като той също може да ви даде по-добри резултати.
GTID
MariaDB идва със собствена реализация на GTID. Последователността на MariaDB се състои от домейн, сървър и транзакция. Домейните позволяват репликация от няколко източника с различен идентификатор. Различни идентификатори на домейни могат да се използват за репликиране на част от данни извън ред (паралелно). Докато това е наред за приложението ви, това може да намали забавянето на репликацията.
Подобна техника се прилага и за MySQL 5.7, който също може да използва главния и независим канали за репликация.
Компресия
Мощността на процесора става по-евтина с течение на времето, така че използването й за компресиране на binlog може да бъде добър вариант за много среди на база данни. Параметърът slave_compressed_protocol казва на MySQL да използва компресия, ако и master, и slave го поддържат. По подразбиране този параметър е деактивиран.
Започвайки от MariaDB 10.2.3, избраните събития в двоичния журнал могат да бъдат компресирани по избор, за да се запазят мрежовите трансфери.
Формати за репликация
MySQL предлага няколко режима на репликация. Изборът на правилния формат за репликация помага да се сведе до минимум времето за предаване на данни между възлите на клъстера.
Мултимастър репликация за висока наличност
Някои приложения не могат да си позволят да работят с остарели данни.
В такива случаи може да искате да наложите последователност между възлите със синхронна репликация. Поддържането на синхрон на данните изисква допълнителен плъгин и за някои най-доброто решение на пазара за това е Galera Cluster.
Клъстерът Galera идва с wsrep API, който е отговорен за предаването на транзакции до всички възли и изпълнението им в съответствие с подреждане в целия клъстер. Това ще блокира изпълнението на последващи заявки, докато възелът не приложи всички набори за запис от своята опашка за приложение. Въпреки че е добро решение за последователност, може да се натъкнете на някои архитектурни ограничения. Често срещаните проблеми със закъснението могат да бъдат свързани с:
- Най-бавният възел в клъстера
- Операции за хоризонтално мащабиране и запис
- Геолокирани клъстери
- Висок пинг
- Размер на транзакцията
Най-бавният възел в клъстера
По проект, производителността на запис на клъстера не може да бъде по-висока от производителността на най-бавния възел в клъстера. Започнете прегледа на клъстера, като проверите ресурсите на машината и проверете конфигурационните файлове, за да се уверите, че всички те работят при едни и същи настройки за производителност.
Паралелизиране
Паралелните нишки не гарантират по-добра производителност, но може да ускорят синхронизирането на нови възли с клъстера. Състоянието wsrep_cert_deps_distance ни казва възможната степен на паралелизиране. Това е стойността на средното разстояние между най-високата и най-ниската последователна стойност, която евентуално може да се приложи паралелно. Можете да използвате променливата на състоянието wsrep_cert_deps_distance, за да определите максималния възможен брой подчинени нишки.
Хоризонтално мащабиране
Като добавим повече възли в клъстера, имаме по-малко точки, които могат да се провалят; информацията обаче трябва да премине през множество инстанции, докато не бъде ангажирана, което умножава времето за отговор. Ако имате нужда от мащабируеми записи, помислете за архитектура, базирана на разделяне. Добро решение може да бъде механизмът за съхранение на Spider.
В някои случаи, за да намалите информацията, споделена в възлите на клъстера, можете да помислите да имате един записващ в даден момент. Сравнително лесно е за прилагане, докато използвате балансьор на натоварване. Когато правите това ръчно, уверете се, че имате процедура за промяна на стойността на DNS, когато вашият възел за запис изпадне.
Геолокирани клъстери
Въпреки че Galera Cluster е синхронен, е възможно да се разположи клъстер Galera в центрове за данни. Синхронната репликация като MySQL Cluster (NDB) реализира двуфазен комит, при който съобщенията се изпращат до всички възли в клъстер във фаза „подготовка“, а друг набор от съобщения се изпращат във фаза „комит“. Този подход обикновено не е подходящ за географски различни възли поради латентностите при изпращане на съобщения между възли.
Висок пинг
Galera Cluster с настройките по подразбиране не се справя добре с високата мрежова латентност. Ако имате мрежа с възел, който показва високо време за пинг, помислете за промяна на параметрите evs.send_window и evs.user_send_window. Тези променливи определят максималния брой пакети данни в репликация в даден момент. За настройките на WAN променливата може да бъде зададена на значително по-висока стойност от стойността по подразбиране 2. Обичайно е да се зададе на 512. Тези параметри са част от wsrep_provider_options.
--wsrep_provider_options="evs.send_window=512;evs.user_send_window=512"Размер на транзакцията
Едно от нещата, които трябва да имате предвид, докато управлявате Galera Cluster, е размерът на транзакцията. Намирането на баланса между размера на транзакцията, производителността и процеса на сертифициране на Galera е нещо, което трябва да прецените във вашето приложение. Можете да намерите повече информация за това в статията Как да подобрим производителността на Galera Cluster за MySQL или MariaDB от Ашраф Шариф.
Чета за причинно-следствена последователност на балансира на натоварването
Дори и с минимизирания риск от проблеми със забавянето на данните, стандартната асинхронна репликация на MySQL не може да гарантира последователност. Все още е възможно данните все още да не са репликирани в подчинен, докато приложението ви ги чете от там. Синхронната репликация може да реши този проблем, но има архитектурни ограничения и може да не отговаря на изискванията на вашето приложение (например интензивни групови записи). И така, как да го преодолеем?
Първата стъпка за избягване на четене на остарели данни е да информирате приложението за забавянето на репликацията. Обикновено се програмира в код на приложението. За щастие има модерни балансатори на натоварване на базата данни с поддръжка на адаптивно маршрутизиране на заявки, базирано на GTID проследяване. Най-популярните са ProxySQL и Maxscale.
ProxySQL 2.0
ProxySQL Binlog Reader позволява на ProxySQL да знае в реално време кой GTID е бил изпълнен на всеки MySQL сървър, подчинен и главен. Благодарение на това, когато клиент изпълнява четене, което трябва да осигури причинно-следствено четене, ProxySQL веднага знае на кой сървър може да бъде изпълнена заявката. Ако по каквато и да е причина записите все още не са били изпълнени на подчинен, ProxySQL ще знае, че записващият е бил изпълнен на главен и ще изпрати прочитаното там.
Maxscale 2.3
MariaDB въведе случайни четения в Maxscale 2.3.0. Начинът, по който работи, е подобен на ProxySQL 2.0. По принцип, когато causal_reads са разрешени, всички последващи четения, извършени на подчинени сървъри, ще се извършват по начин, който предотвратява забавянето на репликацията да повлияе на резултатите. Ако подчинението не е настигнало главната в рамките на конфигурираното време, заявката ще бъде повторена на главната.