MySQL главен-подчинен репликация е доста лесен и лесен за настройка. Това е основната причина хората да избират тази технология като първа стъпка за постигане на по-добра наличност на база данни. Това обаче идва с цената на сложността в управлението и поддръжката; Администраторът трябва да поддържа целостта на данните, особено по време на отказ, възстановяване, поддръжка, надстройка и т.н.
Има много статии, описващи как да се извърши операция за преодоляване на срив за настройка на репликация. Ние също покрихме тази тема в тази публикация в блога, Въведение в отказоустойчивостта за MySQL репликация – блогът 101. В тази публикация в блога ще покрием задачите след бедствие при възстановяване до оригиналната топология – извършване на операция при отказ.
Защо се нуждаем от отказ?
Лидерът на репликацията (главният) е най-критичният възел в настройката за репликация. Той изисква добри хардуерни спецификации, за да гарантира, че може да обработва записи, да генерира събития за репликация, да обработва критични четения и така нататък по стабилен начин. Когато се изисква преминаване при отказ по време на възстановяване или поддръжка, може да не е необичайно да откриете, че популяризираме нов лидер с по-нисък хардуер. Тази ситуация може временно да е наред, но за дълго време определеният главен трябва да бъде върнат, за да ръководи репликацията, след като се счита, че е здрава.
За разлика от отказоустойчивостта, операцията при отказ обикновено се случва в контролирана среда чрез превключване, рядко се случва в режим на паника. Това дава на оперативния екип известно време да планира внимателно и да репетира упражнението за плавен преход. Основната цел е просто да върнем добрия стар хозяин в най-новото състояние и да възстановим настройката за репликация до оригиналната й топология. Въпреки това, има някои случаи, когато връщането на отказ е от решаващо значение, например когато новопостъпилият главен код не работи както се очаква и засяга цялостната услуга на базата данни.
Как да извършим безопасно връщане при отказ?
След като се случи отказ, старият хозяин ще бъде извън веригата на репликация за поддръжка или възстановяване. За да извършите превключването, трябва да направите следното:
- Предоставете стария главен в правилното състояние, като го направите най-актуалния подчинен.
- Спрете приложението.
- Уверете се, че всички подчинени устройства са уловени.
- Повишете стария господар като нов лидер.
- Пренасочете всички подчинени устройства към новия главен.
- Стартирайте приложението, като пишете на новия главен файл.
Помислете за следната настройка за репликация:
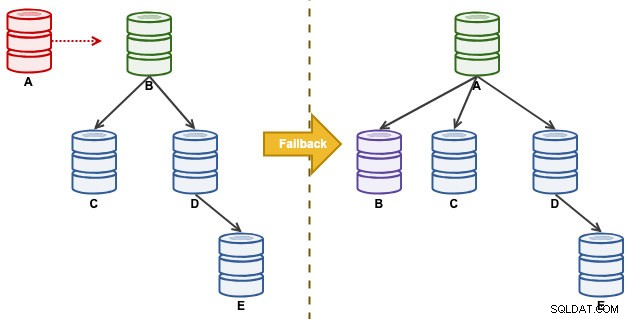
"A" беше главен до събитие, пълно с диск, което причини хаос във веригата за репликация. След събитие при отказ, нашата топология на репликация се ръководи от B и се репликира от C до E. Упражнението за възстановяване на отказ ще върне A като лидер и ще възстанови оригиналната топология преди бедствието. Обърнете внимание, че всички възли работят на MySQL 8.0.15 с активиран GTID. Различните основни версии може да използват различни команди и стъпки.
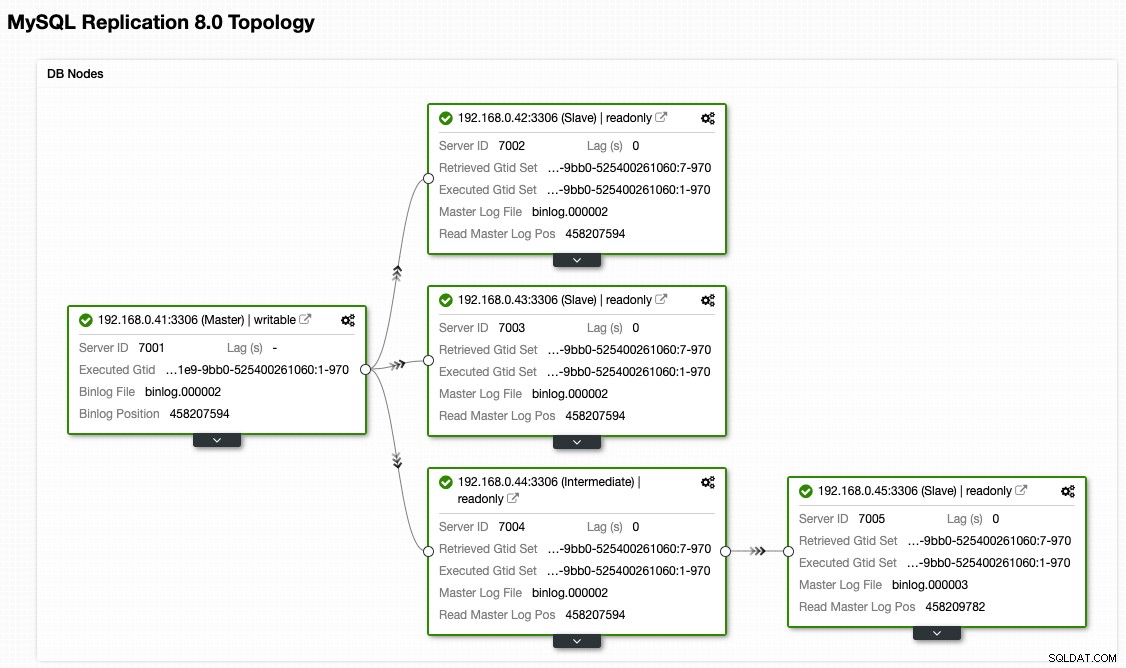
Макар че ето как изглежда нашата архитектура сега след отказ (взето от изгледа Topology на ClusterControl):
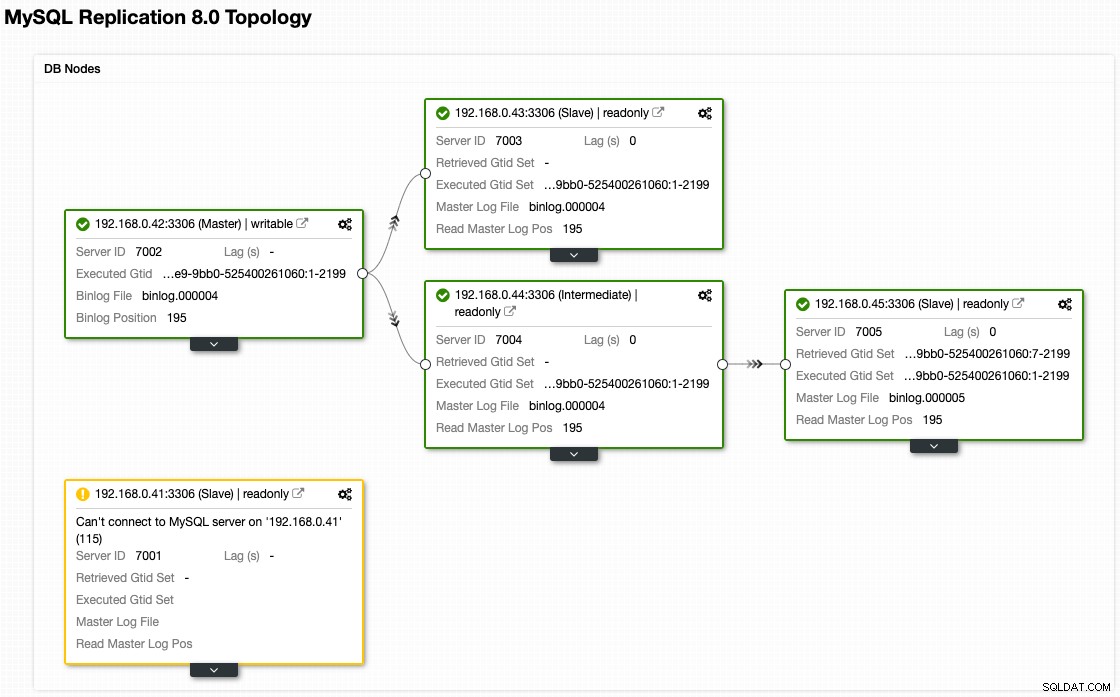
Осигуряване на възел
Преди A може да бъде главен, той трябва да бъде актуализиран с текущото състояние на базата данни. Най-добрият начин да направите това е да превърнете A като подчинен на активния главен, B. Тъй като всички възли са конфигурирани с log_slave_updates=ON (това означава, че подчинен също произвежда двоични регистрационни файлове), всъщност можем да изберем други подчинени устройства като C и D като източникът на истината за първоначално синхронизиране. Въпреки това, колкото по-близо до активния господар, толкова по-добре. Имайте предвид допълнителното натоварване, което може да причини, когато правите резервно копие. Тази част отнема по-голямата част от часовете за отказ. В зависимост от състоянието на възела и размера на набора от данни, синхронизирането на стария главен код може да отнеме известно време (може да са часове и дни).
След като проблемът на "A" е разрешен и е готов за присъединяване към веригата за репликация, най-добрата първа стъпка е да опитате репликиране от "B" (192.168.0.42) с оператор CHANGE MASTER:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Ако репликацията работи, трябва да видите следното в състоянието на репликация:
Slave_IO_Running: Yes
Slave_SQL_Running: YesАко репликацията е неуспешна, вижте Last_IO_Error или Last_SQL_Error от изхода за състоянието на подчинено устройство. Например, ако видите следната грешка:
Last_IO_Error: error connecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 2След това трябва да създадем потребителя за репликация на текущия активен главен код, B:
mysql> CREATE USER example@sqldat.com IDENTIFIED BY 'p4ss';
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com;След това рестартирайте подчинения на A, за да започнете да репликирате отново:
mysql> STOP SLAVE;
mysql> START SLAVE;Друга често срещана грешка, която ще видите, е този ред:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ...Това вероятно означава, че подчинения има проблем с четенето на двоичния регистрационен файл от текущия главен. В някои случаи подчиненият може да е доста изостанал, при което необходимите двоични събития за стартиране на репликацията са липсвали от текущия главен файл или двоичният файл на главната програма е бил прочистен по време на отказ и т.н. В този случай най-добрият начин е да извършите пълно синхронизиране, като направите пълен архив на B и го възстановите на A. На B можете да използвате или mysqldump, или Percona Xtrabackup, за да направите пълно архивиране:
$ mysqldump -uroot -p --all-databases --single-transaction --triggers --routines > dump.sql # for mysqldump
$ xtrabackup --defaults-file=/etc/my.cnf --backup --parallel 1 --stream=xbstream --no-timestamp | gzip -6 - > backup-full-2019-04-16_071649.xbstream.gz # for xtrabackupПрехвърлете архивния файл в A, инициализирайте отново съществуващата инсталация на MySQL за правилно почистване и извършете възстановяване на базата данни:
$ systemctl stop mysqld # if mysql is still running
$ rm -Rf /var/lib/mysql # wipe out old data
$ mysqld --initialize --user=mysql # initialize database
$ systemctl start mysqld # start mysql
$ grep -i 'temporary password' /var/log/mysql/mysqld.log # retrieve the temporary root password
$ mysql -uroot -p -e 'ALTER USER example@sqldat.com IDENTIFIED BY "p455word"' # mandatory root password update
$ mysql -uroot -p < dump.sql # restore the backup using the new root passwordСлед като бъде възстановено, настройте връзката за репликация към активния главен B (192.168.0.42) и активирайте само за четене. На A изпълнете следните оператори:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */За Percona Xtrabackup, моля, вижте страницата с документация за това как да възстановите до A. Това включва предпоставка за подготовка на архива, преди да замените директорията с данни MySQL.
След като A започне да репликира правилно, наблюдавайте Seconds_Behind_Master в състояние на подчинен. Това ще ви даде представа колко далеч е изоставил робът и колко време трябва да изчакате, преди да го настигне. В този момент нашата архитектура изглежда така:
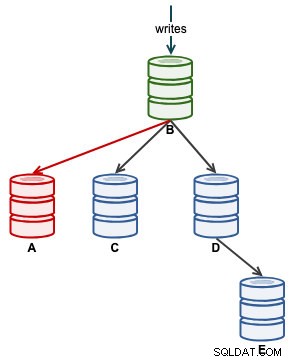
След като Seconds_Behind_Master падне обратно на 0, това е моментът, в който A е настигнал като актуален роб.
Ако използвате ClusterControl, имате опцията да синхронизирате повторно възела чрез възстановяване от съществуващ архив или да създадете и поточно архивирате директно от активния главен възел:
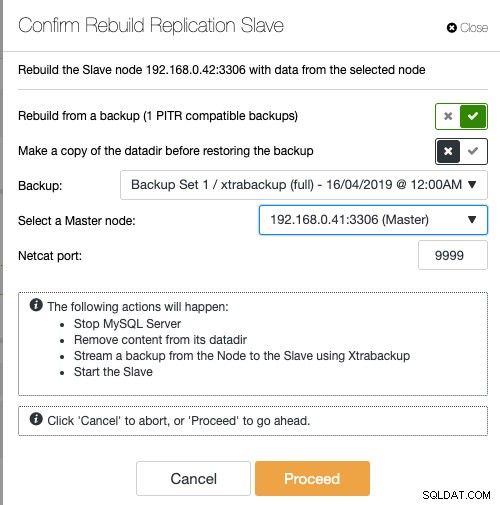
Поставянето на подчинения със съществуващо архивно копие е препоръчителният начин за изграждане на подчинения, тъй като не оказва никакво влияние върху активния главен сървър при подготовката на възела.
Промотирайте стария майстор
Преди да повишите A като нов главен, най-сигурният начин е да спрете всички операции по запис на B. Ако това не е възможно, просто принудете B да работи в режим само за четене:
mysql> SET GLOBAL read_only = 'ON';
mysql> SET GLOBAL super_read_only = 'ON';След това, на A, стартирайте SHOW SLAVE STATUS и проверете следното състояние на репликация:
Read_Master_Log_Pos: 45889974
Exec_Master_Log_Pos: 45889974
Seconds_Behind_Master: 0
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updatesСтойността на Read_Master_Log_Pos и Exec_Master_Log_Pos трябва да бъде идентична, докато Seconds_Behind_Master е 0 и състоянието трябва да бъде „Slave has read all relay log“. Уверете се, че всички подчинени са обработили всички изявления в своя регистрационен файл, в противен случай рискувате новите заявки да повлияят на транзакциите от регистрационния файл на релето, задействайки всякакви проблеми (например, приложението може да премахне някои редове, до които се осъществява достъп от транзакции от релейния дневник).
На A, спрете репликацията и използвайте израза RESET SLAVE ALL, за да премахнете цялата конфигурация, свързана с репликацията, и деактивирайте само четене:
mysql> STOP SLAVE;
mysql> RESET SLAVE ALL;
mysql> SET GLOBAL read_only = 'OFF';
mysql> SET GLOBAL super_read_only = 'OFF';В този момент A е готов да приеме записи (read_only=OFF), но подчинените не са свързани към него, както е илюстрирано по-долу:
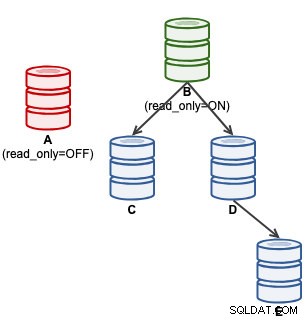
За потребители на ClusterControl, популяризирането на A може да се извърши чрез използване на функцията „Повишаване на подчинен“ под Действия на възел. ClusterControl автоматично ще понижи активния главен B, ще повиши подчиненото устройство A като главен и ще пренасочи C и D към репликиране от A. B ще бъде оставен настрана и потребителят трябва изрично да избере „Промяна на главната репликация“, за да се присъедини отново към B, репликиращ от A на по-късен етап .
Пренасочване на роб
Вече е безопасно да промените главната на свързани подчинени устройства за репликация от A (192.168.0.41). На всички подчинени с изключение на E, конфигурирайте следното:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.41', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Ако сте потребител на ClusterControl, можете да пропуснете тази стъпка, тъй като пренасочването се извършва автоматично, когато сте решили да повишите A преди това.
След това можем да стартираме нашето приложение да пише на A. В този момент нашата архитектура изглежда нещо подобно:
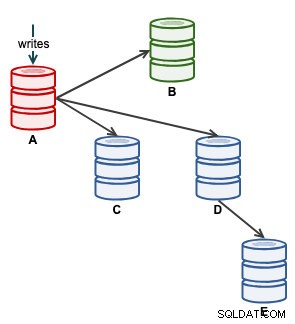
От изглед на топологията на ClusterControl възстановихме нашия клъстер за репликация до оригиналната му архитектура, която изглежда така:
Обърнете внимание, че упражнението при отказ е много по-малко рисково в сравнение с превключването при отказ. Важно е да планирате това упражнение в непиковите часове, за да сведете до минимум въздействието върху бизнеса си.
Последни мисли
Операциите по отказ и връщане при отказ трябва да се извършват внимателно. Операцията е доста проста, ако имате малък брой възли, но за множество възли със сложна верига на репликация, това може да бъде рисково и податливо на грешки упражнение. Показахме също как ClusterControl може да се използва за опростяване на сложни операции, като ги изпълнява чрез потребителския интерфейс, плюс изгледът на топологията се визуализира в реално време, така че да имате разбиране за топологията на репликация, която искате да изградите.