Референтните показатели са една от дейностите, които администраторите на бази данни извършват. Пускате ги, за да видите как се държи вашият хардуер, стартирате ги, за да видите как вашето приложение и база данни работят заедно под напрежение. Вие ги изпълнявате в много различни ситуации. Нека поговорим малко за тях, какви са предизвикателствата, пред които ще се сблъскате, какви са проблемите, които трябва да избягвате.
Типове сравнителни показатели
Всеки бенчмарк е различен. Те служат за различни цели и това трябва да се вземе предвид, когато планирате да стартирате такъв. Като цяло можете да дефинирате два основни типа бенчмарк:синтетичен бенчмарк и, да го наречем, бенчмарк в „реалния свят“.
Синтетичните бенчмаркове обикновено са инструменти, които симулират някакъв вид работно натоварване. Това може да бъде OLTP работно натоварване, както в случая на Sysbench, може да бъде някакъв „стандартен“ бенчмарк като в TPC-C или TPC-H. Обикновено идеята е, че такъв бенчмарк симулира някакво работно натоварване и може да е полезно, ако вашето работно натоварване в реалния свят ще следва същия модел. Може също да се използва, за да се определи как вашата комбинация от хардуер и конфигурация на база данни работи заедно при даден тип натоварване. Предимствата на синтетичните бенчмаркове са съвсем ясни. Можете да ги стартирате навсякъде, те не зависят от някаква конкретна настройка или дизайн на схема. Е, те го правят, но измислят инструменти за настройка на всичко от празния сървър на база данни. Основният недостатък е, че това не е вашето натоварване. Ако ще стартирате OLTP тестове с помощта на Sysbench, тогава трябва да имате предвид, че приложението ви никога няма да бъде Sysbench. Може също да изпълнява OLTP натоварване, но миксът на заявките ще бъде различен. Никога и при никакви обстоятелства синтетичният бенчмарк няма да ви каже как точно ще се държи вашето приложение при даден микс хардуер/конфигурация.
От другия край на спектъра имаме, това, което нарекохме, сравнителни показатели за „реалния свят“. Това, което имаме предвид тук, е бенчмарк, който използва набор от данни и заявки, свързани с вашето приложение. Той не винаги има пълен набор от данни и пълен микс от заявки. Може да искате да се съсредоточите върху някои части от приложението си, но основната идея зад него е, че искате да разберете точните взаимодействия между приложението, хардуера и конфигурацията на базата данни, като цяло или в някакъв конкретен аспект.
Както споменахме по-горе, имаме два основни, различни типа бенчмаркове, но все пак те имат някои общи неща, които трябва да имате предвид, докато се опитвате да стартирате сравнителните показатели.
-
Решете какво искате да тествате
На първо място, сравнителният анализ в името на провеждането на бенчмаркове е безсмислен. Тя трябва да бъде проектирана така, че действително да постигне нещо. Какво искате да получите от еталонния тест? Искате ли да настроите заявките? Искате ли да настроите конфигурацията? Искате ли да оцените мащабируемостта на вашия стек? Искате ли да подготвите стека си за по-голямо натоварване? Искате ли да направите обща настройка на настройките за нов проект? Искате ли да определите най-добрите настройки за вашия хардуер? Това са примери за цели, които може да искате да постигнете. Всеки от тях ще изисква различен подход и различна настройка за сравнителен тест.
-
Правете една по една промяна
Каквото и да тествате и настройвате, от изключително значение е да правите само една промяна в конфигурацията наведнъж. Това е наистина критично. Бенчмаркът има за цел да ви даде някаква представа за производителността. Заявки в секунда, латентност, 99 процентил, всичко това ви казва колко бързо можете да изпълнявате заявките и колко стабилно и предвидимо е натоварването. Лесно е да се разбере дали промяната, която сте направили в конфигурацията, хардуера или микса на заявки, променя нещо:показателите от бенчмарка ще изглеждат различно. Работата е там, че ако направите няколко промени едновременно, няма начин да разберете коя е отговорна за цялостния резултат. Може да отиде дори по-далеч от това. Да приемем, че сте променили две стойности в конфигурацията на базата данни. Стойност A и B. Общото подобрение е 20%, което е доста добре само за промяна на конфигурацията. Под капака обаче промяната на стойност A доведе до подобрение от 30%, докато допълнителна промяна на стойност B я върна на 20%. При множество промени едновременно можете да наблюдавате само общото им въздействие, това не е начинът да определите правилно резултата от всяка една промяна, която сте направили. Разбира се, това значително увеличава времето, което ще прекарате в изпълнение на бенчмарка, но това е така.
-
Направете няколко бенчмарк теста
Компютрите са сложни системи сами по себе си. Те имат множество компоненти, които взаимодействат един с друг:памет, процесор, диск, мрежа. Тогава нека добавим към тази виртуализация, контейнеризация. След това софтуер – операционна система, приложение, база данни. Слой върху слой върху слой върху слой от елементи, които взаимодействат по някакъв начин. Не е лесно да се предвиди поведението му. Е, можете да кажете, че е почти невъзможно да се предвиди точно поведението на такива сложни системи. Това е причината, поради която провеждането на един бенчмарк тест не е достатъчно, за да се направят заключения. Ами ако, несъзнателно за вас, някакъв елемент, напълно несвързан с това, което искате да тествате, повлияе на цялостната производителност? Високо натоварване на друга виртуална машина, разположена на същия хост. Някой друг сървър предава поточно архивиране през мрежата. Това може временно да повлияе на производителността и да изкриви резултатите от сравнителния тест. Ако изпълните само едно бенчмарк тестване, в крайна сметка ще получите неправилни резултати. Ето защо най-добрата практика е да изпълните няколко преминавания на еталон и след това да премахнете най-бавния и най-бързия от тях, като осредните останалите.
-
Една снимка струва хиляди думи
Е, това е почти много точно описание на сравнителния анализ. Ако е възможно, винаги генерирайте графики. В идеалния случай проследявайте показателите по време на бенчмарка толкова често, колкото можете. Една секунда детайлност трябва да е достатъчна за повечето случаи. За да избегнем писането на хиляди думи, ще включим този пример. Кое според вас е по-полезно? Този набор от изходни показатели, които представляват среден QPS за всяко от 10 преминавания, като всяко преминаване отнема 600 секунди
11650,52
11237,97
11550.16
11247.08
11177,78
11163,76
11131.47
11235.06
11235,59
11277,25
Или този график:
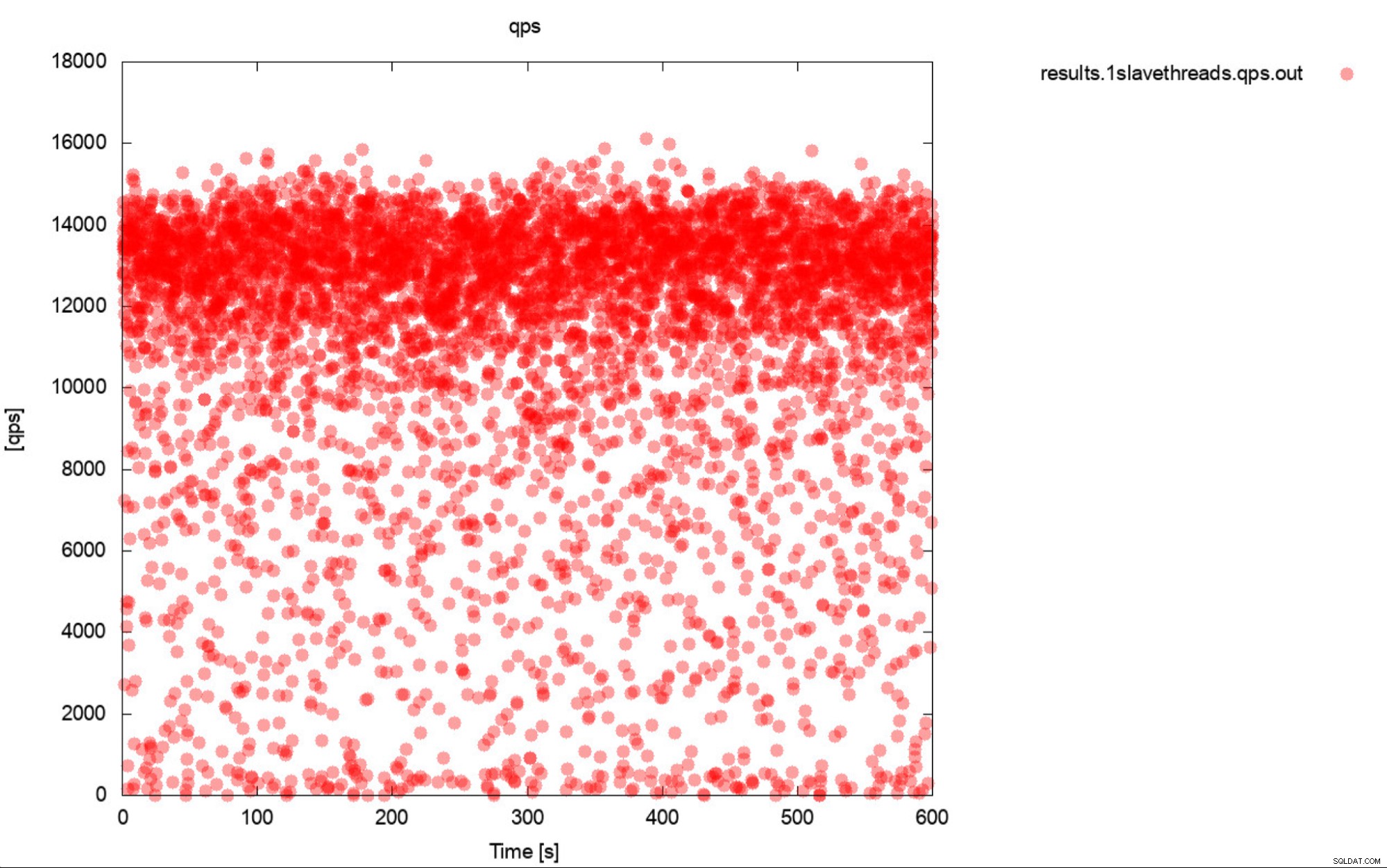
Средният QPS е 11k, но реалността е, че производителността е навсякъде място, включително спадове до 0 заявки, изпълнени в рамките на секунда, и определено е нещо, с което искате да работите и да подобрите производствените системи.
-
Заявките в секунда не са най-важният показател
Може да си мислите, че заявката в секунда е светият граал на производителността, тъй като представлява колко заявки може да изпълни една база данни в рамките на една секунда. Истината е, че това не е най-важният показател, особено ако говорим за осреднена продукция от бенчмарк. QPS представлява пропускателната способност, но игнорира латентността. Можете да опитате да изпратите голям обем заявки, но след това в крайна сметка чакате те да върнат резултати. Това не е, което потребителите очакват от приложението. Потребителите очакват стабилна производителност. Не е нужно да е много бързо, но когато завършването на някое действие отнема секунда, ние сме склонни да очакваме, че изпълнението на това действие винаги ще отнеме тази 1 секунда. Ако по някаква причина започне да отнема повече време, хората са склонни да се тревожат. Това е основната причина, поради която сме склонни да предпочитаме латентността, особено нейния P99 (99-ти персентил) като по-надежден показател. Закъснението ни казва колко време е трябвало да изчака приложението за резултата от базата данни. P99 ни казва латентността, че 99% от заявките са по-ниски от. Да кажем, че имаме P99 от 100ms, това означава, че 99% от заявките връщат резултати не по-бавни от 100ms. Ако видим латентност на P99 ниска, това означава, че почти всички заявки се връщат бързо и работят по стабилен и предвидим начин. Това е нещо, което нашите потребители искат да видят.
-
Разберете какво се случва, преди да направите заключения
Последната точка, която имаме в този кратък блог, но бихме казали, че е най-важната. Ще видите различни странни и неочаквани резултати и поведение по време на бенчмаркове. Още по-лошо е, че може да видите доста стандартни, повтарящи се, но все пак дефектни резултати. Повечето от тях могат да бъдат проследени до поведението на базата данни или хардуера. Това е наистина от решаващо значение - преди да приемете резултата за даденост, трябва да можете да обясните поведението и да опишете какво се е случило. Знаем, че не е лесно и знаем, че наистина изисква познания, специфични за базата данни, особено знания, свързани с вътрешността на базата данни. Знаем, че в реалния свят хората обикновено не се занимават с това, те просто искат да получат някакви резултати. Работата е там, особено в случаите, когато се опитвате да подобрите производителността чрез конфигурация или хардуерни настройки, разбирането на случилото се под капака ви позволява да изберете правилния начин, по който трябва да продължи вашата настройка. Освен това дава възможност да се разбере дали изпълненият еталон може да има някакъв смисъл. Наистина ли тестваме правилния елемент? Пример би бил тест, извършен през мрежата (защото не бихте искали да използвате локални процесорни ядра на възела на базата данни за инструмент за сравнителен анализ). Много е вероятно самата мрежа и softirq натоварването на процесора да бъдат ограничаващият фактор, много по-рано, отколкото бихте се натъкнали на „очаквани“ тесни места като насищане на процесора. Ако не сте наясно с вашата среда и нейното поведение, вие ще измервате производителността на вашата мрежа, за да прехвърляте големи обеми данни, а не производителността на процесора.
Както виждате, сравнителният анализ не е най-лесното нещо за правене, трябва да имате известно ниво на информираност какво се случва, трябва да имате подходящ план за това, което ще правите и какво искаш да тестваш? В следващата част на този блог ще преминем през някои от реалните тестови случаи. Какво може да се обърка, какви проблеми ще срещнем и как да се справим с тях.



