В предишния ни блог проучихмеВъведение в Hadoop и Функции на Hadoop , Сега в този блог ще разгледаме подробно функцията за висока наличност на HDFS NameNode.
На първо място, ще обсъдим HDFS NemNode High Availability Architecture, следващо с внедряването на Hadoop High Availability Architecture, използвайки възли на Quorum Journal и споделено съхранение.
Висока наличност на HDFS NameNode
ВHDFS , данните са много достъпни и достъпни въпреки хардуерната повреда. HDFS е най-надеждната система за съхранение, предназначена за съхранение на много големи файлове.
HDFS следва топология главен/подчинен. В кой главен елемент е NameNode и подчинените е DataNode . NameNode съхранява метаданни. Метаданните включват броя на блоковете, тяхното местоположение, реплики и други подробности. За по-бързото извличане на данни, метаданните са налични в главния. NameNode поддържа и възлага задачи на подчинения възел.
NameNode беше единичната точка на отказ (SPOF) преди Hadoop 2.0. HDFS клъстерът имаше един NameNode. Ако NameNode не успее, целият клъстер се срива.
Единична точка на повреда ограничава високата наличност по следните начини:
- Ако някое непланирано събитие се задейства, като сривове на възел, тогава клъстерът ще бъде недостъпен, освен ако оператор не рестартира новия възел на име.
- Също така планираните дейности по поддръжка, като надстройки на хардуера на NameNode, ще доведат до прекъсване на работата на клъстера Hadoop.
Архитектура за висока достъпност на HDFS NameNode
Въвеждането на Hadoop 2.0 преодоля товаSPOF чрез предоставяне на поддръжка на множество NameNode. Архитектурата на HDFS NameNode High Availability предоставя опцията за стартиране на два излишни NameNode в един и същ клъстер в активна/пасивна конфигурация с горещ режим на готовност.
- Активен възел на име – Той обработва всички HDFS клиентски операции в HDFS клъстера.
- Пасивен възел на име – Това е резервен именен възел. Той има подобни данни като активния NameNode.
Така че, когато Active NameNode се провали, пасивният NameNode ще поеме цялата отговорност на активния възел. По този начин HDFS клъстерът продължава да работи.
Проблемите при поддържането на последователност в клъстера с висока достъпност HDFS са както следва:
- Активният и Standby NameNode трябва винаги да са синхронизирани един с друг, т.е. трябва да имат едни и същи метаданни. Това позволява да се възстанови клъстерът Hadoop в същото състояние на пространството от имена, в което е претърпял срив. И това ще ни осигури бързо преминаване при отказ.
- Трябва да има само един NameNode активен в даден момент. В противен случай два NameNode ще доведат до повреда на данните. Наричаме този сценарий като „Сценарий с разделен мозък “, където клъстерът се разделя на по-малкия клъстер. Всеки от тях вярва, че това е единственият активен клъстер. „Оградата“ избягва подобно Фехтовка е процес, който гарантира, че само един NameNode остава активен в определен момент.
Внедряване на архитектура с висока достъпност на Hadoop
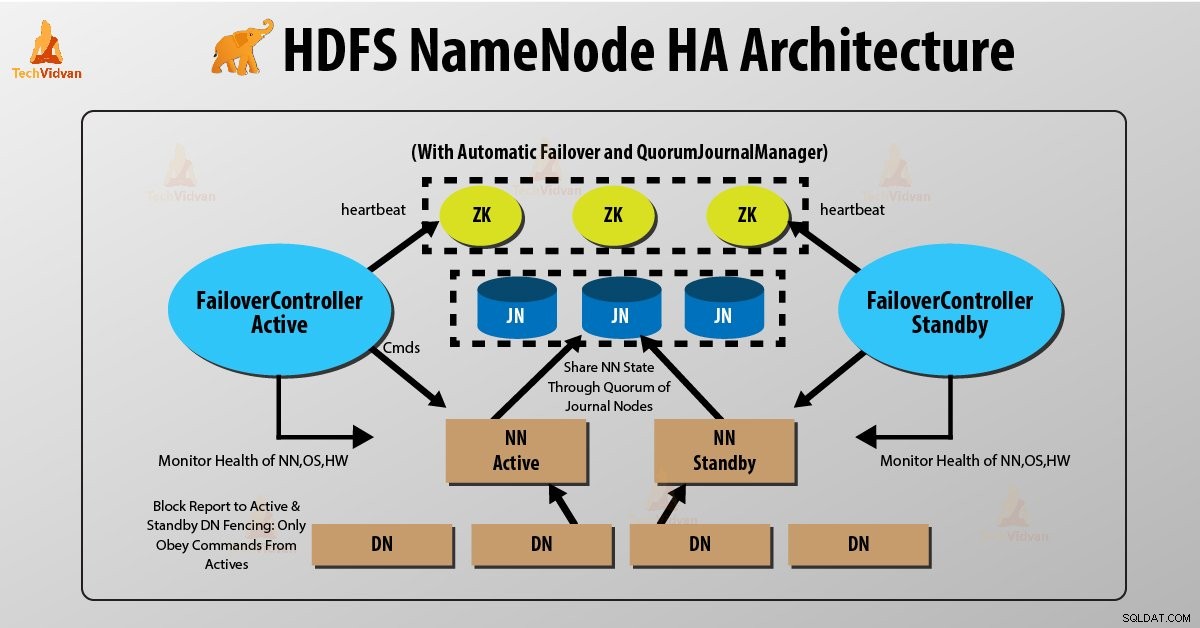
Два NameNode работят едновременно в HDFS NameNode High Availability Architecture. HDFS клиентът може да реализира конфигурацията Active и Standby NameNode по следните два начина:
- Използване на възли на кворумния журнал
- Използване на споделено хранилище
1. Използване на възли на кворумния журнал
Възлови дневници на кворума е реализация на HDFS. QJN предоставя журнали за редактиране. Позволява споделянето на тези регистрационни файлове за редактиране между активния и резервния NameNode.
Standby Namenode комуникира и се синхронизира с активния NameNode за висока наличност. Това ще се случи от група демони, наречени „Journal nodes“. Възлите на дневника на кворума се изпълняват като група от възли на журнала. Там трябва да има поне три възела на дневника.
За N възли на журнала системата може да толерира най-много (N-1)/2 повреди. Така системата продължава да работи. Така че за три възела на журнала системата може да толерира повреда на един {(3-1)/2} от тях.
Всеки път, когато активен възел извършва каквато и да е модификация, той регистрира модификацията на всички възли в дневника.
Възелът в режим на готовност чете редакциите от възлите на дневника и се прилага към собственото си пространство от имена по постоянен начин. В случай на отказ, режимът на готовност ще гарантира, че е прочел всички редакции от възлите на дневника, преди да се повиши в активно състояние. Това гарантира, че състоянието на пространството от имена е напълно синхронизирано, преди да възникне грешка.
За да осигури бързо преминаване при отказ, възелът в режим на готовност трябва да има актуална информация за местоположението на блоковете данни в клъстера. За да се случи това, IP адресът и на двата NameNode е достъпен за всички възли с данни и те изпращат информация за местоположението на блока и сърдечни удари и на двата NameNode.
Ограждане на NameNode
За правилната работа на HA клъстер, само един от NameNodes трябва да е активен в даден момент. В противен случай състоянието на пространството от имена ще се отклони между двата NameNode. Така че ограждането е процес за осигуряване на тази собственост в клъстер.
- Възлите на дневника изпълняват тази ограда, като позволяват само един NameNode да бъде записващ в даден момент.
- Резервният NameNode поема отговорността да записва до възлите на дневника и забранява на всеки друг NameNode да остане активен.
- Накрая, новият активен NameNode може да изпълнява своите дейности.
2. Използване на споделено хранилище
В режим на готовност и активният NameNode се синхронизират един с друг чрез използване на „споделено устройство за съхранение“. За тази реализация както активният NameNode, така и резервният Namenode трябва да имат достъп до конкретната директория на споделеното устройство за съхранение (т.е. мрежова файлова система).
Когато активният NameNode извърши каквато и да е промяна на пространството от имена, той регистрира запис на модификацията в регистрационен файл за редактиране, съхранен в споделената директория. Резервният NameNode наблюдава тази директория за редакции и когато се появят редакции, резервният NameNode ги прилага към своето собствено пространство от имена. В случай на неуспех, резервният NameNode ще гарантира, че е прочел всички редакции от споделеното хранилище, преди да се повиши в активно състояние. Това гарантира, че състоянието на пространството от имена е напълно синхронизирано, преди да настъпи отказ.
За да предотврати „сценарията с разделен мозък“, при който състоянието на пространството от имена се отклонява между двата NameNode, администраторът трябва да конфигурира поне един метод за ограждане за споделеното хранилище.
Заключение
Следователно, Hadoop 2.0 HDFS HA осигурява единичен активен NameNode и единичен резервен NameNode. Но някои внедрявания се нуждаят от висока степен на толерантност на грешки . Hadoop нова версия 3.0, позволява на потребителя да изпълнява много резервни възли на име.
Например, конфигуриране на пет journalnode и три NameNode. В резултат на това клъстерът hadoop е в състояние да толерира повреда на два възела, а не на един.
Моля, споделете своя опит и предложения във връзка с високата наличност на HDFS NameNode в секцията за коментари по-долу.



