tl;dr:Elasticache ви принуждава да използвате единичен екземпляр на redis, което е неоптимално.
Дългата версия:
Разбирам, че това е стара публикация (2 години към момента на писане), но мисля, че е важно да отбележа нещо, което не виждам тук.
На elasticache вашето разгръщане на redis се управлява от Amazon. Това означава, че сте останали с това, което те решат да стартират вашия redis.
Redis използва една нишка на изпълнение за четене/записване. Това гарантира последователност без заключване. Голямо предимство по отношение на производителността е да не управлявате брави и ключалки. Неприятната последица обаче е, че ако вашият EC2 има повече от 1 vCPU, те ще останат неизползвани. Такъв е случаят с всички екземпляри на elasticache с повече от един vCPU.
Размерът на екземпляра на elasticache по подразбиране е cache.r3.large , който има две ядра.
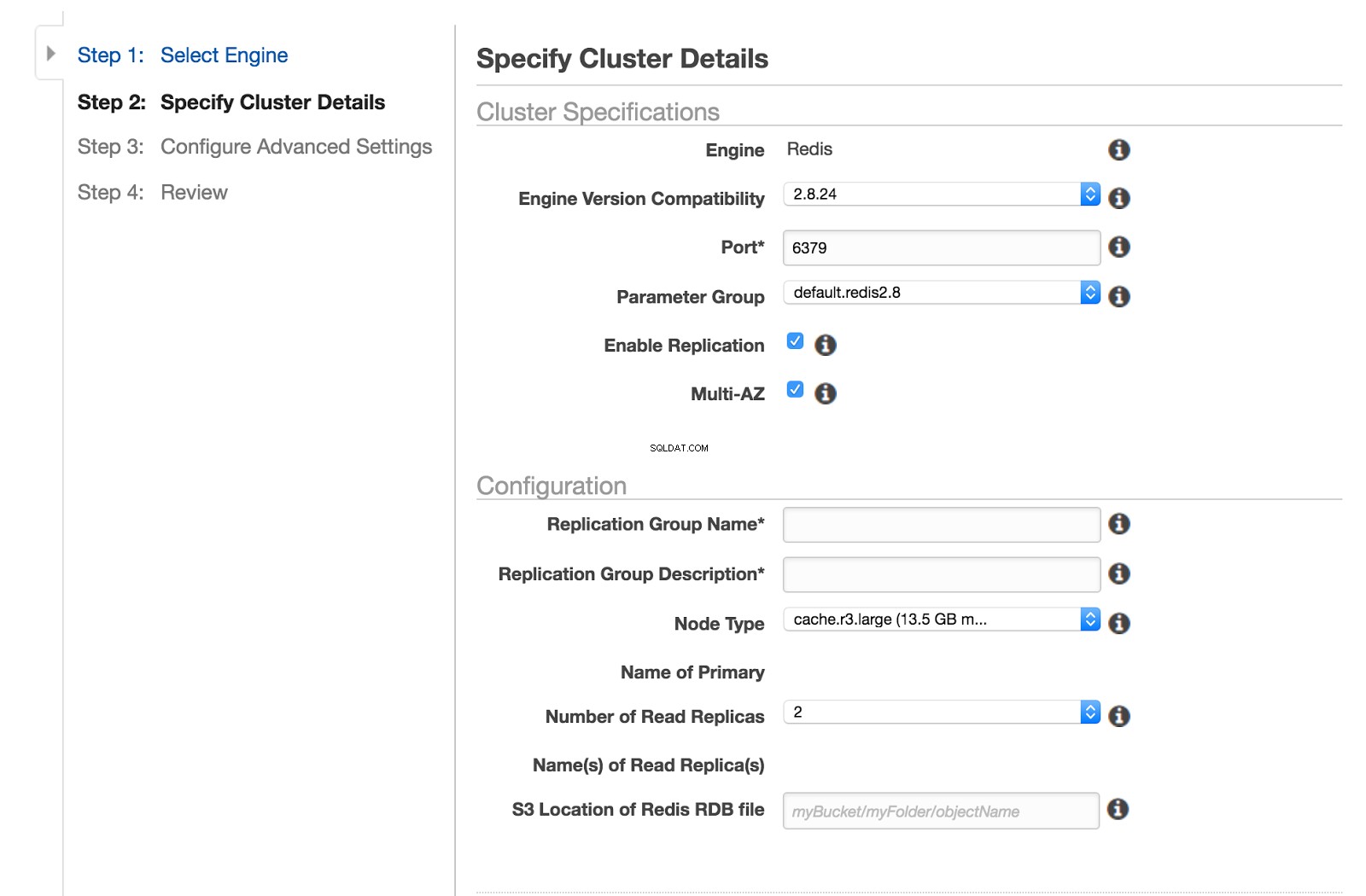
Всъщност има редица размери на екземпляра с множество vCPU. Много възможности този проблем да се прояви.
Изглежда, че Amazon вече са наясно с този проблем, но изглежда малко пренебрежително го правят.

Частта, която прави това особено уместно за този въпрос, е, че на вашия EC2 (тъй като управлявате собственото си внедряване) вие можете да внедрите multi-tenancy . Това означава, че имате много екземпляри на процеса на redis, който слуша на различни портове. Като изберете кой порт да четете/записвате към/от който в приложението въз основа на хеш на ключа на записа, можете да използвате всичките си vCPU.
Като странична бележка; разгръщането на redis elasticache на многоядрена машина винаги трябва да се изпълнява по-слабо в сравнение с разгръщането на elasticache с memcached на размера на екземпляра. При многократно наемане redis обикновено е победител.
Актуализация:
Amazon вече предоставя отделни показатели за CPU на вашия редис инстанция, EngineCPUUtilization. Вече не е необходимо да изчислявате своя процесор с калпавото умножение, но все още не е внедрено многократното наемане.



