Правенето на правилно архивиране на базата данни е критична задача. Освен да настроите архитектурата с висока наличност на вашия MongoDB за услуги за бази данни, вие също трябва да имате резервни копия на вашите бази данни, за да гарантирате наличността на данни в случай на бедствие. Например, ако случайно изтриете някои данни от производствена база данни, единственият начин да възстановите данните от гледна точка на базата данни е да възстановите от архивиране.
Наскоро ClusterControl започна да поддържа нов метод за архивиране, наречен Percona Backup за MongoDB, разработен от Percona. Може да изпълнява последователни архиви за MongoDB реплики и разчленени клъстери.
В този блог ще разгледаме управлението на архивиране на MongoDB реплики и разчленени клъстери.
Архивиране на MongoDB във високодостъпна архитектура
ClusterControl поддържа 3 метода за архивиране, които са mongodump, mongodb последователен и Percona Backup за Mongodb. Последователното архивиране на mongodb използва помощната програма mongodump като метод за архивиране, а архивът може да бъде възстановен с помощта на mongorestore.
Последният поддържан метод за архивиране е Percona Backup за Mongodb за последователно и в момента архивиране на набор от реплики и разчленени клъстери, той изисква агент, който да работи на всеки възел или набор от реплики или възли на фрагменти и възли за управление за клъстери от фрагменти, както е описано тук.
Конфигурирането и планирането на последователно архивиране с помощта на Percona Backup за Mongodb в ClusterControl е много лесно. Отидете на страницата за архивиране и след това конфигурирайте Percona Backup за Mongodb. Предпоставката е Percona Backup за MongoDB да работи на всеки възел, който също може да бъде инсталиран от ClusterControl.
Трябва първо да инсталираме агента Percona Backup за MongoDB, преди да можем да планираме архивиране, както е посочено по-долу:
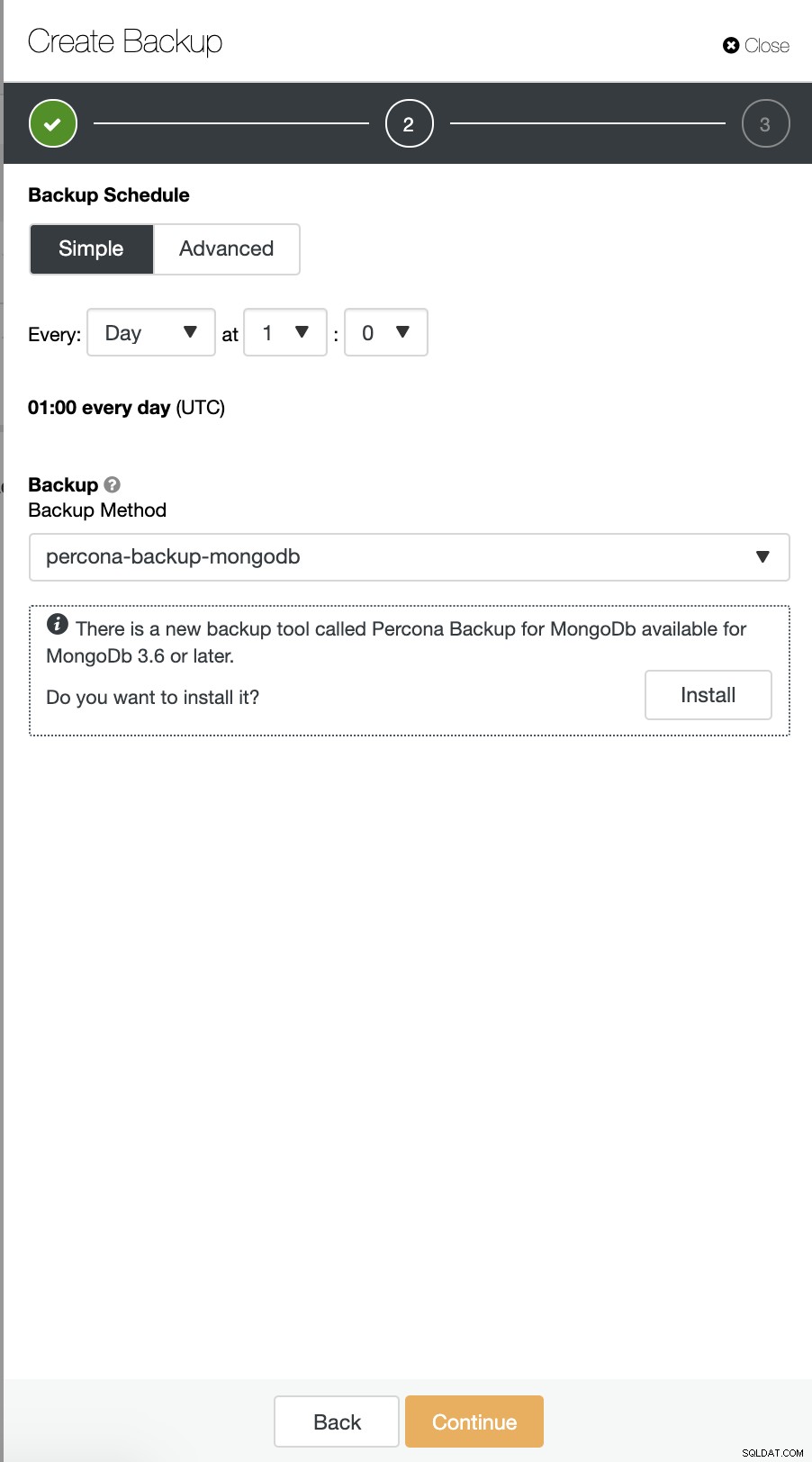
И след това конфигурирайте резервната директория. Моля, обърнете внимание, че директорията за архивиране трябва да бъде споделен диск, който е бил монтиран на всички възли с точно същия монтиран път, както по-долу:
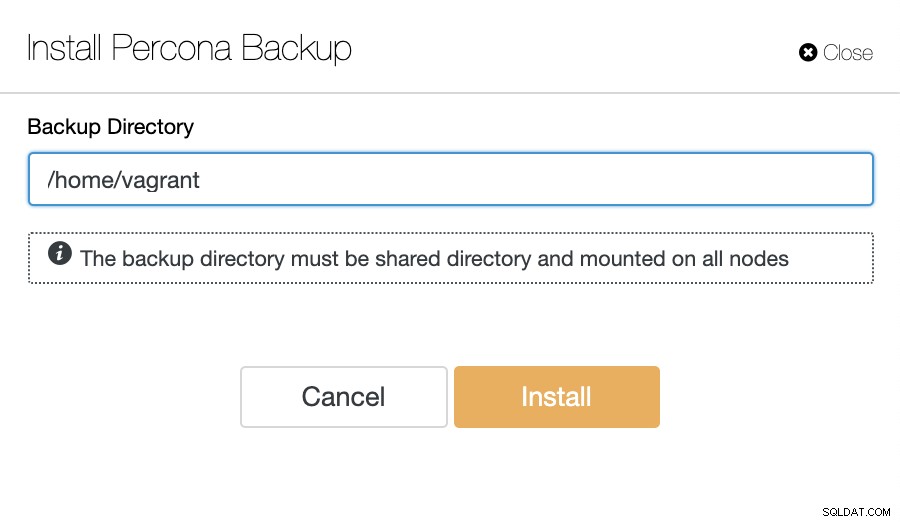
Ако нямате готов споделен диск в системата, можете да използвате NFS, за да постигнете това. За да конфигурираме NFS сървъра, се нуждаем от специален сървър/виртуална машина с достатъчно свободно място за съхранение на архива. Инсталирайте библиотеката nfs-utils и nfs-utils-lib в сървъра, както е посочено по-долу (ако приемем, че използваме базирана на CentOS):
[example@sqldat.com ~]# yum install nfs-utils nfs-utils-lib
[example@sqldat.com ~]# yum install portmapИ стартирайте услугите portmap и nfs.
[example@sqldat.com ~]# /etc/init.d/portmap start
[example@sqldat.com ~]# /etc/init.d/nfs startСлед това добавете нови записи в /etc/exports, както е показано по-долу:
[example@sqldat.com ~]# vi /etc/exports
/backup 10.10.10.11(rw,sync,no_root_squash)На възела на базата данни просто трябва да монтираме диска за съхранение като споделено хранилище.
Последно нещо, просто щракнете върху бутона за инсталиране и това ще задейства нова задача за конфигуриране на агента на всеки възел.

След като всички PBM ggent бъдат инсталирани, можем да конфигурираме метода за архивиране за клъстер, както е по-долу:

Физическо срещу логическо архивиране
Архивирането на MongoDB поддържа логическо архивиране и физическо архивиране. Методът за логическо архивиране с помощта на помощната програма mongodump е включен, когато инсталирате пакета mongodb. Mongodump се нуждае от достъп до вашата база данни mongodb, следователно изисква достъп до идентификационни данни за mongodump с привилегии на роли за архивиране и трябва да има разрешение за действие за намиране за архивиране на базата данни.
Работи за формати за изхвърляне на данни BSON. Mongodump ще се свърже с вашата база данни с предоставени идентификационни данни, ще прочете всички данни във вашата база данни и ще изхвърли данните във файлове. Тъй като това е процес с една нишка, архивирането ще отнеме повече време, особено при голям размер на базата данни. Mongodump не поддържа атомарността на транзакциите в сегментите, поради което не може да се използва като стратегия за архивиране за mongodb версия 4.2 и по-нова в раздробен клъстер. Percona Backup за MongoDB е логично архивиране, но поддържа последователно архивиране на клъстери.
Физическото архивиране в MongoDB работи чрез моментна снимка на файловите системи mongodb, копира основните mongodb файлове на друго място като базово архивиране на вашата база данни mongodb. Моментната снимка на файловата система е операционна система, ако използвате LVM (Logical Volume Manager) като софтуер за управление на вашето разположение на диска и устройство или софтуерно устройство, напр. Veritas или NetApp Backup. Трябва да активирате журналирането, регистрационния файл на промените в активността в mongodb, преди да стартирате моментната снимка на файловата система, за да направите резервното копие последователно.
Освен моментната снимка на файловата система, можете също да използвате командата cp или rsync за копиране на файлове с данни на MongoDB, но трябва да спрете процеса на запис в mongodb, тъй като процесът на копиране на файлове с данни не е атомна операция. Архивът не може да се използва за възстановяване на точка във времето в набори от реплики или архитектури с разчленени клъстери.
Percona Backup за MongoDB се състои от два компонента, pbm-agent, който трябва да бъде инсталиран на всеки възел, и pbm като интерфейс на командния ред за взаимодействие и изпълнение на архивирането. Координатата на pbm-agent между възлите на базата данни и стартиране на процеса на архивиране и възстановяване. Pbm-агентът ще реши най-добрия възел за вземане на резервно копие.
PITR архивиране
В много системи за бази данни е обичайно да се използва контролна точка за изхвърляне на данните в диска. MongoDB използва WiredTiger машина за съхранение като машина за съхранение по подразбиране и също така използва контролни точки, за да осигури последователен изглед на данните. Не само това, контролната точка в MongoDB може да се използва за възстановяване от последната контролна точка. Журналирането работи между всяка контролна точка, журналирането е необходимо за възстановяване от неочаквани прекъсвания, които се случват по всяко време между контролните точки. Журналирането гарантира, че операциите по запис се записват на диск, MongoDB ще създаде запис в дневник за всяка промяна, включително променените байтове и местоположението на диска.
Mongodump и mongorestore могат да се използват за резервно копие за възстановяване в даден момент, има опция за използване на oplog. Oplog е ограничена колекция в MongoDB, която проследява всички промени в колекциите за всяка транзакция на запис (напр. вмъкване, актуализиране, изтриване). Така че, ако искате да извършите възстановяване в даден момент, трябва да възстановите от последното пълно архивиране и също така да използвате oplog файла, за да приложите промените към точното време, което искате да възстановите. Друг инструмент, който може да се използва, е Percona Backup за MongoDB, процесът е подобен на mongodump, трябва да възстановим от архива и след това да приложим oplog.
Заключение
Правенето на последователно архивиране е важно, особено при клъстерни настройки на MongoDB (набор от реплики или разчленен клъстер). ClusterControl предоставя лесен начин за конфигуриране на Percona Backup за MongoDB във вашия клъстер и планиране на вашите архиви.



