ClusterControl е програмиран с редица алгоритми за възстановяване, за да реагира автоматично на различни типове често срещани повреди, засягащи системите ви с бази данни. Той разбира различни типове топологии на бази данни и управление на процесите, свързани с базата данни, за да ви помогне да определите най-добрия начин за възстановяване на клъстера. По някакъв начин ClusterControl подобрява наличността на вашата база данни.
Някои топологични мениджъри покриват само възстановяването на клъстер като MHA, Orchestrator и mysqlfailover, но трябва да се справите сами с възстановяването на възела. ClusterControl поддържа възстановяване както на ниво клъстер, така и на ниво възел.
Опции за конфигуриране
Има два компонента за възстановяване, поддържани от ClusterControl, а именно:
- Клъстер – Опит за възстановяване на клъстер до работно състояние
- Възел – Опит за възстановяване на възел до работно състояние
Тези два компонента са най-важните неща, за да се гарантира, че наличността на услугата е възможно най-висока. Ако вече имате мениджър на топология отгоре на ClusterControl, можете да деактивирате функцията за автоматично възстановяване и да оставите друг топологичен мениджър да се справи вместо вас. Имате всички възможности с ClusterControl.
Функцията за автоматично възстановяване може да бъде активирана и деактивирана с обикновен превключвател ON/OFF и работи за възстановяване на клъстер или възел. Зелените икони означават активирани, а червените икони означават деактивирани. Следната екранна снимка показва къде можете да го намерите в списъка на клъстерите на базата данни:
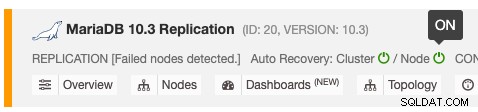
Има 3 параметъра на ClusterControl, които могат да се използват за контролиране на поведението при възстановяване. Всички параметри са по подразбиране на true (зададени с булево цяло число 0 или 1):
- enable_autorecovery – Активирайте възстановяването на клъстер и възел. Този параметър е надмножеството на enable_cluster_recovery и enable_node_recovery. Ако е зададено на 0, параметрите на подмножеството ще бъдат изключени.
- enable_cluster_recovery – ClusterControl ще извърши възстановяване на клъстер, ако е активирано.
- enable_node_recovery – ClusterControl ще извърши възстановяване на възел, ако е активиран.
Възстановяването на клъстера обхваща опит за възстановяване за извеждане на цялата топология на клъстера. Например, репликация главен-подчинен трябва да има поне един жив главен във всеки даден момент, независимо от броя на наличните подчинени устройства. ClusterControl се опитва да коригира топологията поне веднъж за клъстери за репликация, но безкрайно за репликация с множество глави като NDB Cluster и Galera Cluster.
Възстановяването на възел обхваща проблема с възстановяването на възел, като например ако възел е бил спрян без познания за ClusterControl, например чрез команда за спиране на системата от SSH конзолата или е бил убит от OOM процес.
Възстановяване на възел
ClusterControl е в състояние да възстанови възел на базата данни в случай на периодична повреда чрез наблюдение на процеса и свързаност с възлите на базата данни. За процеса той работи подобно на systemd, където ще се увери, че услугата MySQL е стартирана и работи, освен ако не сте я спрели умишлено чрез потребителския интерфейс на ClusterControl.
Ако възелът се върне онлайн, ClusterControl ще установи връзка обратно към възела на базата данни и ще извърши необходимите действия. Следното е какво би направил ClusterControl, за да възстанови възел:
- Ще изчака systemd/chkconfig/init да стартира наблюдаваните услуги/процеси за 30 секунди
- Ако наблюдаваните услуги/процеси все още не работят, ClusterControl ще се опита да стартира услугата за база данни автоматично.
- Ако ClusterControl не може да възстанови наблюдаваните услуги/процеси, ще бъде повдигнат аларма.
Обърнете внимание, че ако изключване на базата данни е инициирано от потребител, ClusterControl няма да се опита да възстанови конкретния възел. Той очаква потребителят да го стартира обратно чрез потребителския интерфейс на ClusterControl, като отиде на Node -> Node Actions -> Start Node или използва изрично командата на OS.
Възстановяването включва всички услуги, свързани с база данни, като ProxySQL, HAProxy, MaxScale, Keepalived, Prometheus експортери и garbd. Специално внимание към експортерите на Prometheus, където ClusterControl използва програма, наречена "демон", за да демонизира процеса на експортиране. ClusterControl ще се опита да се свърже с порта за слушане на експортера за проверка на здравето и проверка. Затова се препоръчва да отворите портовете за експортиране от сървъра ClusterControl и Prometheus, за да сте сигурни, че няма фалшива аларма по време на възстановяване.
Възстановяване на клъстер
ClusterControl разбира топологията на базата данни и следва най-добрите практики при извършване на възстановяването. За клъстер на база данни, който се предлага с вградена толерантност на грешки като Galera Cluster, NDB Cluster и MongoDB Replicaset, процесът на отказ ще се извърши автоматично от сървъра на базата данни чрез изчисляване на кворума, сърдечен ритъм и превключване на роли (ако има такива). ClusterControl следи процеса и прави необходимите корекции на визуализацията, като отразяване на промените в изглед на топология и коригиране на компонента за наблюдение и управление за новата роля, например нов първичен възел в набор от реплика.
За технологии за бази данни, които нямат вградена толерантност към грешки с автоматично възстановяване, като MySQL/MariaDB Replication и PostgreSQL/TimescaleDB Streaming Replication, ClusterControl ще изпълни процедурите за възстановяване, като следва най-добрите практики, предоставени от доставчик на база данни. Ако възстановяването не успее, е необходима намеса на потребителя и, разбира се, ще получите аларма за това.
При смесена/хибридна топология, например асинхронен подчинен, който е свързан към клъстер Galera или NDB клъстер, възелът ще бъде възстановен от ClusterControl, ако възстановяването на клъстера е активирано.
Възстановяването на клъстер не се прилага за самостоятелен MySQL сървър. Препоръчително е обаче да включите възстановяването както на възел, така и на клъстер за този тип клъстер в потребителския интерфейс на ClusterControl.
Репликация на MySQL/MariaDB
ClusterControl поддържа възстановяване на следната настройка за репликация на MySQL/MariaDB:
- Master-slave с MySQL GTID
- Master-slave с MariaDB GTID
- Master-slave с без GTID (както MySQL, така и MariaDB)
- Master-master с MySQL GTID
- Master-master с MariaDB GTID
- Асинхронно подчинено устройство, свързано към клъстер Galera
ClusterControl ще зачита следните параметри, когато извършва възстановяване на клъстер:
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replication_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
За повече подробности относно всеки от параметъра вижте страницата с документация.
ClusterControl ще спазва следните правила, когато наблюдава и управлява репликация главен-подчинен:
- Всички възли ще бъдат стартирани с read_only=ON и super_read_only=ON (независимо от ролята им).
- В даден момент е разрешено да работи само един главен (read_only=OFF).
- Разчитайте на MySQL променлива report_host, за да картографирате топологията.
- Ако има два или повече възли, които имат read_only=OFF наведнъж, ClusterControl автоматично ще настрои read_only=ON на двата главни, за да ги защити от случайни записвания. Необходима е намеса на потребителя, за да се избере действителният главен файл, като се деактивира само за четене. Отидете на Възли -> Действия на възел -> Деактивиране само за четене.
В случай, че активният главен обект се повреди, ClusterControl ще се опита да извърши превключване на главната грешка в следния ред:
- След 3 секунди недостъпност на главната, ClusterControl ще вдигне аларма.
- Проверете наличността на подчинените устройства, поне един от подчинените трябва да е достъпен от ClusterControl.
- Изберете роба като кандидат за господар.
- ClusterControl ще изчисли вероятността от грешни транзакции, ако GTID е активиран.
- Ако не бъде открита грешна транзакция, избраният ще бъде повишен като нов главен.
- Създаване и предоставяне на потребител за репликация, който да се използва от подчинени устройства.
- Промяна на главния за всички подчинени устройства, които сочеха към стария хозяин към новоповишения главен.
- Стартирайте подчинен и активирайте само за четене.
- Изчистете регистрационните файлове на всички възли.
- Ако промоцията на подчинен е неуспешна, ClusterControl ще прекрати задачата за възстановяване. Необходима е намеса на потребителя или рестартиране на услугата cmon, за да се задейства отново задачата за възстановяване.
- Когато старият главен код е наличен отново, той ще бъде стартиран само за четене и няма да бъде част от репликацията. Изисква се намеса на потребителя.
В същото време ще бъдат повдигнати следните аларми:
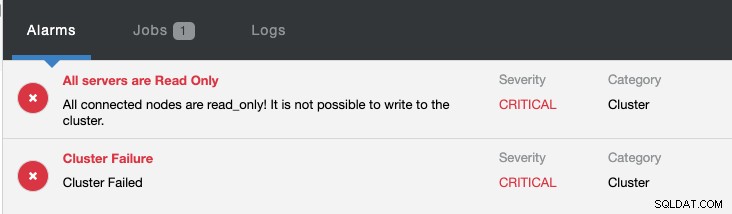
Вижте Въведение в отказоустойчивостта за MySQL репликация – блогът 101 и Автоматично отказване на MySQL репликация – Ново в ClusterControl 1.4, за да получите допълнителна информация за това как да конфигурирате и управлявате отказ на MySQL репликация с ClusterControl.
Поточно репликация на PostgreSQL/TimescaleDB
ClusterControl поддържа възстановяване на следната настройка за репликация на PostgreSQL:
- Поточно репликация на PostgreSQL
- TimescaleDB поточно репликация
ClusterControl ще зачита следните параметри, когато извършва възстановяване на клъстер:
- enable_cluster_autorecovery
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_failover_whitelist
- replication_failover_blacklist
За повече подробности относно всеки от параметъра вижте страницата с документация.
ClusterControl ще спазва следните правила за управление и наблюдение на настройка за поточно репликация на PostgreSQL:
- wal_level е настроен на "replica" (или "hot_standby" в зависимост от версията на PostgreSQL).
- Променлива archive_mode е зададена на ВКЛ. на главния.
- Задайте файл recovery.conf на подчинените възли, което превръща възела в горещ режим на готовност с активиран режим само за четене.
В случай, че активният главен код се повреди, ClusterControl ще се опита да извърши възстановяването на клъстера в следния ред:
- След 10 секунди недостъпност на главната, ClusterControl ще вдигне аларма.
- След 10 секунди грациозно изчакване, ClusterControl ще инициира основната задача за преодоляване на отказ.
- Изпробвайте replayLocation и receiveLocation на всички налични възли, за да определите най-напредналия възел.
- Промотирайте най-напредналия възел като нов главен.
- Спрете подчинени устройства.
- Проверете състоянието на синхронизация с pg_rewind.
- Рестартиране на подчинените с новия главен.
- Ако промоцията на подчинен е неуспешна, ClusterControl ще прекрати задачата за възстановяване. Необходима е намеса на потребителя или рестартиране на услугата cmon, за да се задейства отново задачата за възстановяване.
- Когато старият хозяин е наличен отново, той ще бъде принуден да се изключи и няма да бъде част от репликацията. Необходима е намеса на потребителя. Вижте по-долу.
Когато старият главен код се върне онлайн, ако услугата PostgreSQL работи, ClusterControl ще принуди изключване на услугата PostgreSQL. Това е за защита на сървъра от случайни записи, тъй като той ще бъде стартиран без файл за възстановяване (recovery.conf), което означава, че ще може да се записва. Трябва да очаквате следните редове да се появят в postgresql-{day}.log:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downPostgreSQL беше стартиран, след като сървърът беше отново онлайн около 05:06:10, но ClusterControl извършва бързо изключване 17 секунди след това около 05:06:27. Ако това е нещо, което не бихте искали да бъде, можете за момент да деактивирате възстановяването на възел за този клъстер.
Вижте Автоматично преминаване при отказ на Postgres Replication и Failover за PostgreSQL Replication 101, за да получите допълнителна информация за това как да конфигурирате и управлявате отказ на PostgreSQL репликация с ClusterControl.
Заключение
Автоматичното възстановяване на ClusterControl разбира топологията на клъстера на базата данни и е в състояние да възстанови повреден или влошен клъстер до напълно оперативен клъстер, което ще подобри значително времето на работа на услугата на базата данни. Опитайте ClusterControl сега и постигнете своите деветки в SLA и наличност на база данни. Не познавате своите деветки? Вижте този страхотен калкулатор за деветки.



