В предишните две публикации в блога разгледахме както разгръщането на четирите типа клъстериране/репликация (MySQL/Galera, MySQL репликация, MongoDB и PostgreSQL), така и управлението/мониторинга на вашите съществуващи бази данни и клъстери. И така, след като прочетете тези две първи публикации в блога, вие успяхте да добавите вашите 20 съществуващи настройки за репликация към ClusterControl, да ги разширите и допълнително да разположите два нови клъстера на Galera, докато правите много други неща. Или може би сте внедрили системи MongoDB и/или PostgreSQL. И сега, как ги поддържате здрави?
Точно за това е тази публикация в блога:как да използвате функцията за наблюдение на производителността и съветниците на ClusterControl, за да поддържате здравите си бази данни и клъстери MySQL, MongoDB и/или PostgreSQL. И така, как се прави това в ClusterControl?
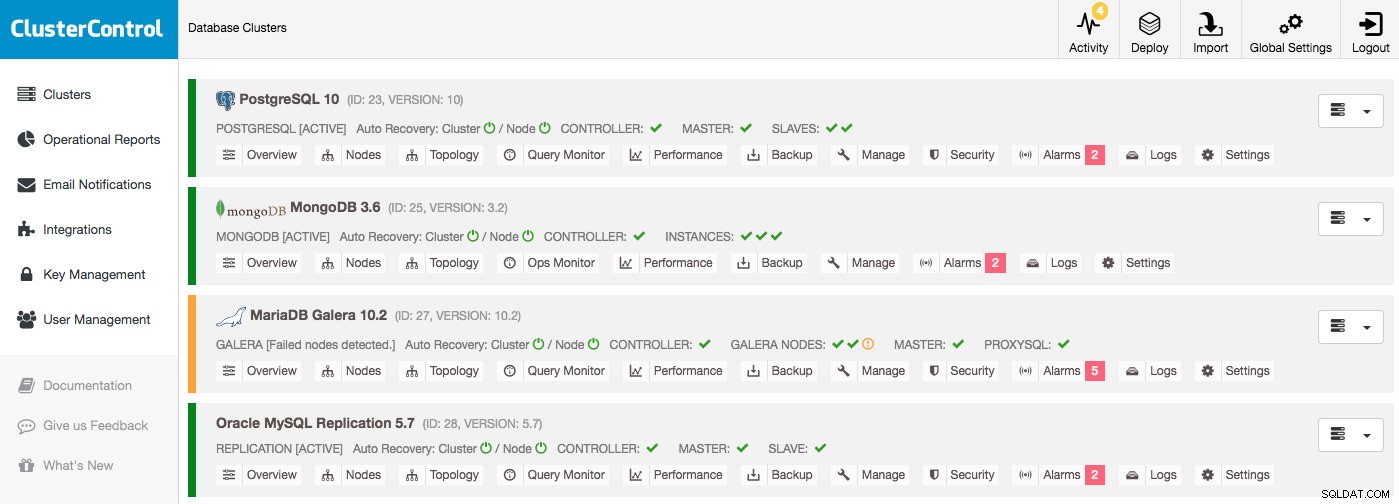
Списък с клъстери от бази данни
Най-важната информация вече може да бъде намерена в списъка с клъстери:докато няма аларми и няма показване на изключени хостове, всичко работи добре. Алармата се вдига, ако е изпълнено определено условие, напр. хостът се разменя и насочва вниманието ви към проблема, който трябва да проучите. Това означава, че алармите не само се вдигат по време на прекъсване, но и за да ви позволят проактивно да управлявате вашите бази данни.
Да предположим, че ще влезете в ClusterControl и ще видите списък с клъстери като този, определено ще имате какво да проучите:например един възел е надолу в клъстера Galera и всеки клъстер има различни аларми:
След като щракнете върху една от алармите, ще отидете на подробна страница за всички аларми на клъстера. Подробностите за алармата ще обяснят проблема и в повечето случаи също ще съветват действието за разрешаване на проблема.
Можете да настроите свои собствени аларми чрез създаване на персонализирани изрази, но това е отхвърлено в полза на нашето ново Developer Studio, което ви позволява да пишете персонализирани Javascripts и да ги изпълнявате като съветници. Ще се върнем към тази тема по-късно в тази публикация.
Преглед на клъстера – Табла за управление
Когато отворим прегледа на клъстера, можем веднага да видим най-важните показатели за ефективността на клъстера в разделите. Този преглед може да се различава в зависимост от типа на клъстера, тъй като например Galera има различни показатели за производителност, които да наблюдавате от традиционните MySQL, PostgreSQL или MongoDB.
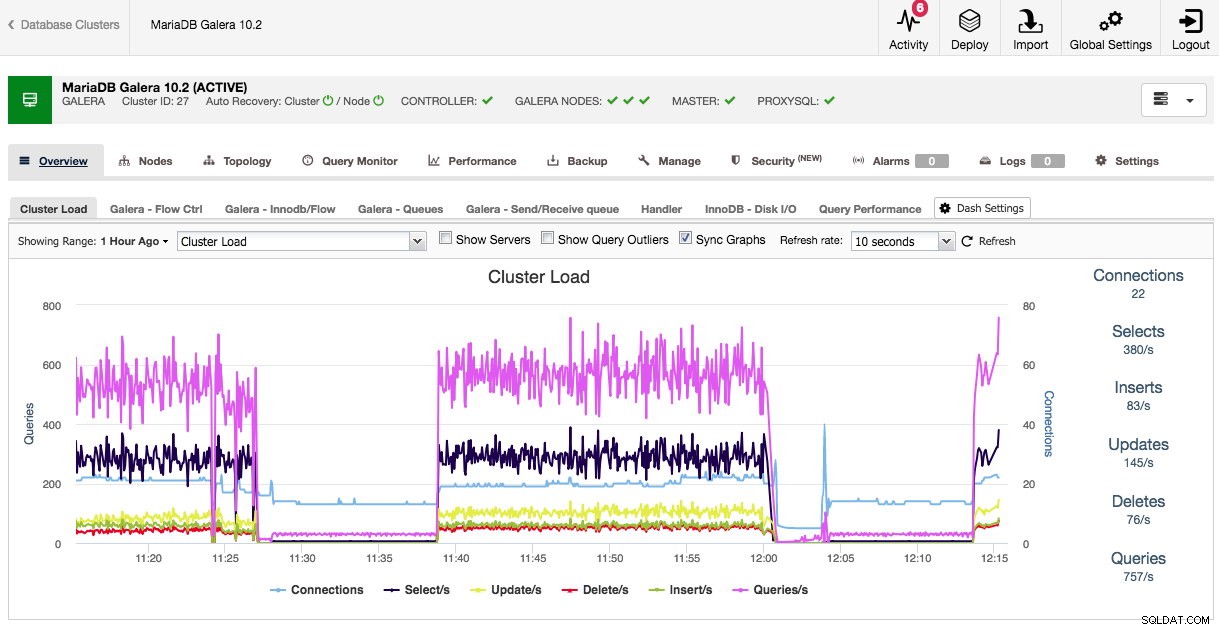
И прегледът по подразбиране, и предварително избраните раздели могат да се персонализират. Като щракнете върху Общ преглед -> Настройки на тирето получавате диалог, който ви позволява да дефинирате таблото:
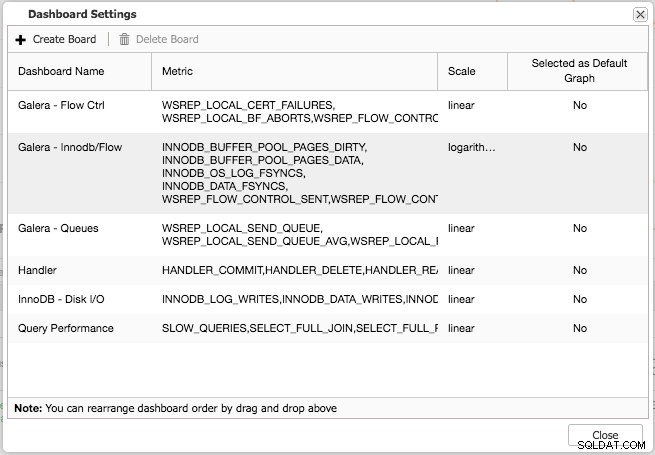
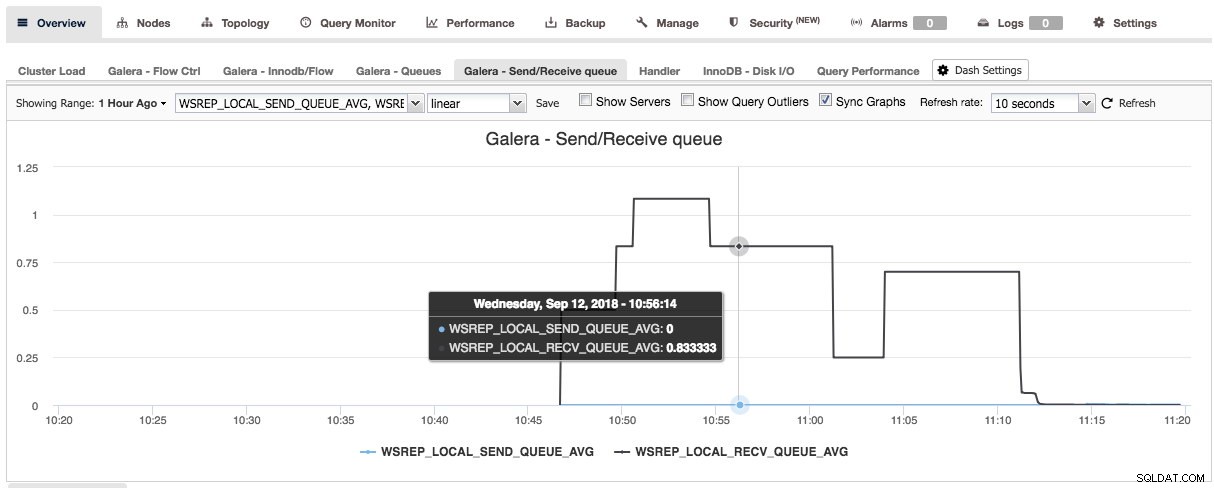
С натискане на знака плюс можете да добавите и дефинирате свои собствени показатели за изобразяване на графика на таблото. В нашия случай ще дефинираме ново табло за управление, включващо специфичната средна стойност на опашката за изпращане и получаване на Galera:
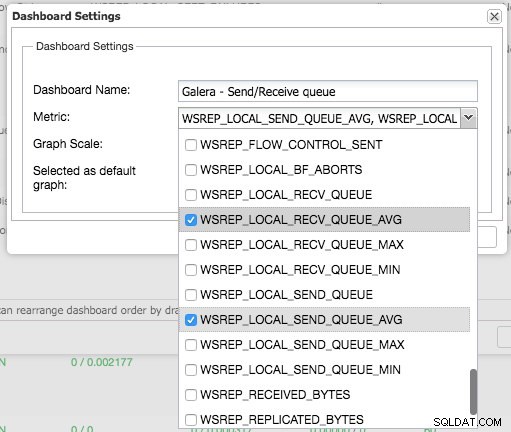
Това ново табло за управление трябва да ни даде добра представа за средната дължина на опашката на нашия клъстер Galera.
След като натиснете Save, новото табло ще стане достъпно за този клъстер:
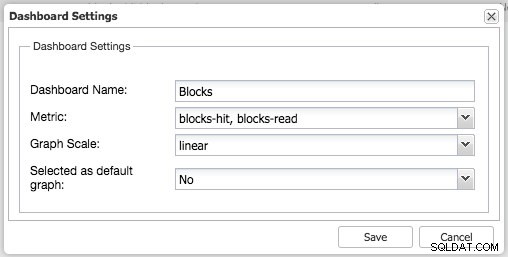
По същия начин можете да направите това и за PostgreSQL, например можем да наблюдаваме ударите на споделените блокове спрямо прочетените блокове:
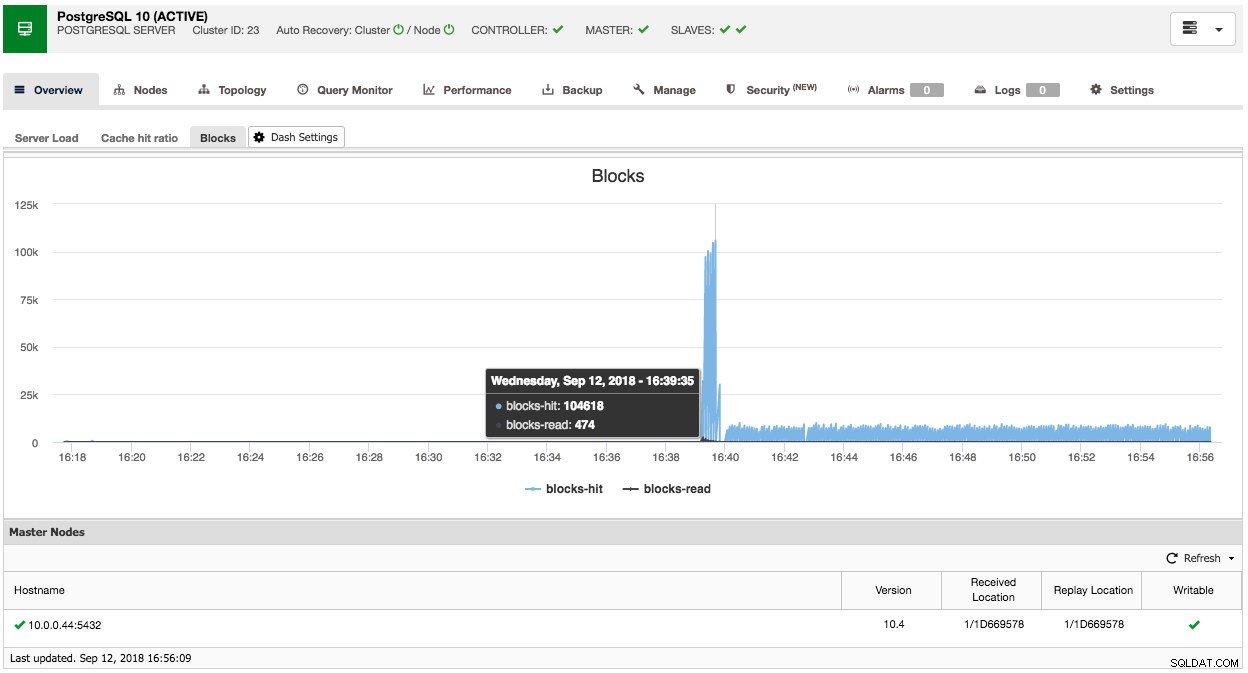
Така че, както можете да видите, е сравнително лесно да персонализирате собственото си (по подразбиране) табло за управление.
Преглед на клъстера - Монитор на заявки
Разделът Монитор на заявки е достъпен както за MySQL, така и за PostgreSQL базирани настройки и се състои от три табла за управление:Най-популярни заявки, Изпълняващи се заявки и Отклонения на заявките.
В таблото за управление на Running Queries ще намерите всички текущи заявки, които се изпълняват. Това по същество е еквивалент на израза SHOW FULL PROCESSLIST в базата данни MySQL.
И двата водещи заявки и отклонения от заявки разчитат на въвеждането на бавния регистър на заявките или схемата за ефективност. Използването на схема на производителност винаги се препоръчва и ще се използва автоматично, ако е активирано. В противен случай ClusterControl ще използва дневника на бавните заявки на MySQL, за да улови изпълняваните заявки. За да предотврати ClusterControl да бъде твърде натрапчив и бавният регистър на заявките да нарасне твърде голям, ClusterControl ще изпробва дневника на бавните заявки, като го включва и изключва. Този цикъл по подразбиране е настроен на 1 секунда заснемане и long_query_time е настроен на 0,5 секунди. Ако искате да промените тези настройки за вашия клъстер, можете да промените това чрез Настройки -> Монитор на заявки .
Най-добрите заявки, както казва името, ще покажат най-популярните заявки, които са били взети в извадка. Можете да ги сортирате по различни колони:например честота, средно време на изпълнение, общо време за изпълнение или време на стандартно отклонение:
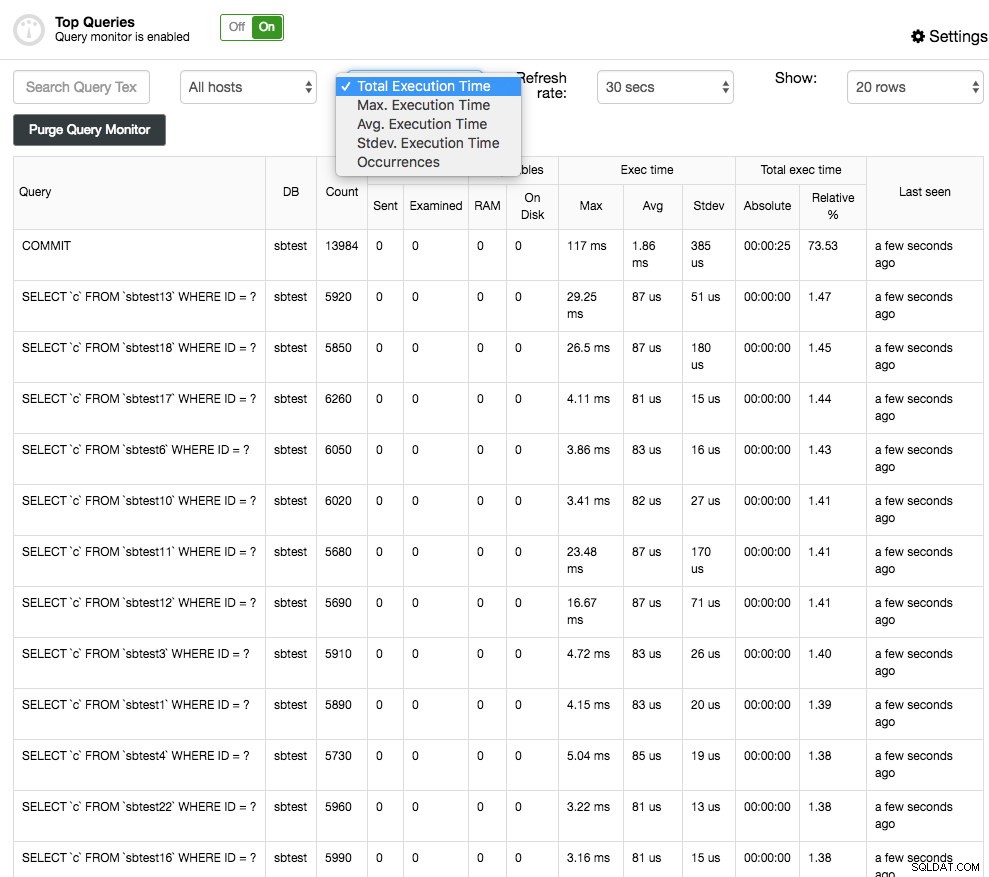
Можете да получите повече подробности за заявката, като я изберете и това ще представи плана за изпълнение на заявката (ако е наличен) и съвети/съвети за оптимизация. Отклоненията на заявките са подобни на водещите заявки, но след това ви позволяват да филтрирате заявките по хост и да ги сравнявате във времето.
Преглед на клъстера - Операции
Подобно на системите PostgreSQL и MySQL, клъстерите MongoDB имат преглед на операциите и са подобни на Running Queries на MySQL. Този преглед е подобен на издаването на командата db.currentOp() в MongoDB.
Преглед на клъстера – производителност
MySQL/Galera
Разделът за производителност е може би най-доброто място за намиране на цялостната производителност и здраве на вашите клъстери. За MySQL и Galera той се състои от страница с общ преглед, съветниците, прегледи на състоянието/променливите, анализатора на схемата и регистъра на транзакциите.
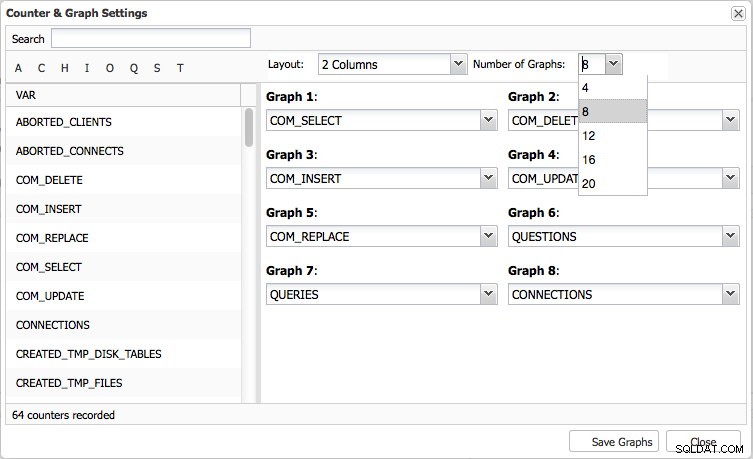
Страницата Общ преглед ще ви даде графичен преглед на най-важните показатели във вашия клъстер. Това очевидно е различно за всеки тип клъстер. Осем показателя са зададени по подразбиране, но можете лесно да зададете свои собствени - до 20 графики, ако е необходимо:
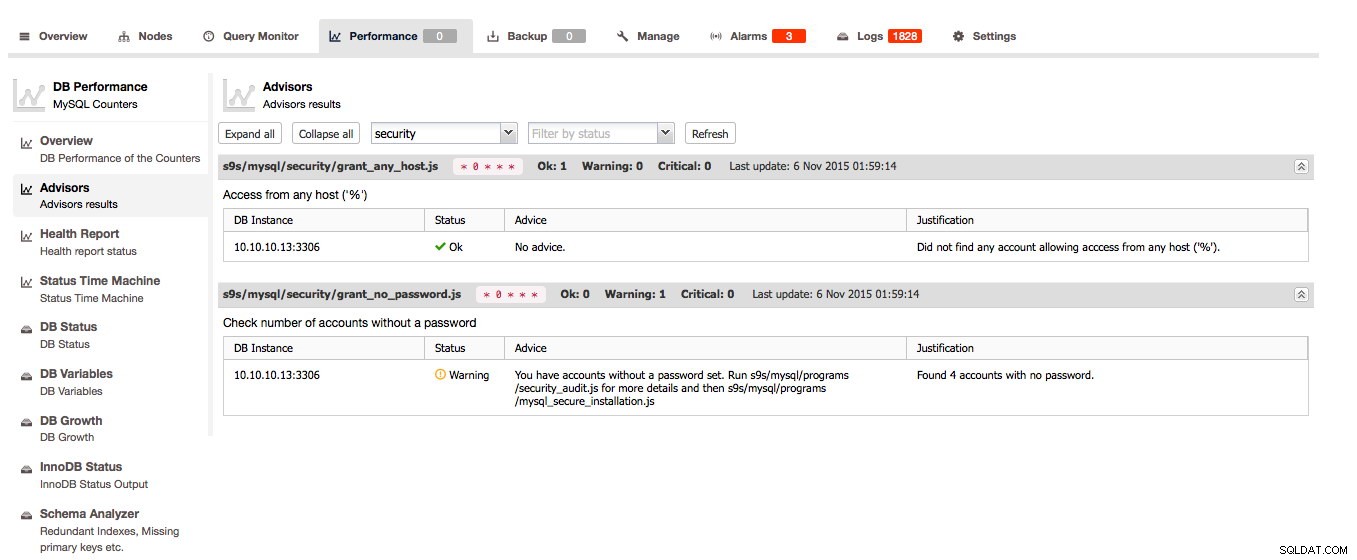
Съветниците са една от ключовите характеристики на ClusterControl:съветниците са скриптирани проверки, които могат да се изпълняват при поискване. Съветниците могат да оценят почти всеки известен факт за хоста и/или клъстера и да дадат своето мнение за здравето на хоста и/или клъстера и дори могат да дадат съвет как да разрешат проблеми или да подобрят своите хостове!
Най-добрата част тепърва предстои:можете да създавате свои собствени проверки в Developer Studio (ClusterControl -> Manage -> Developer Studio ), изпълнявайте ги на редовен интервал и ги използвайте отново в секцията Съветници. Публикувахме блог за тази нова функция по-рано тази година.
Ще пропуснем прегледа на състоянието/променливите на MySQL и Galera, тъй като това е полезно за справка, но не и за тази публикация в блога:достатъчно е добре да знаете, че е тук.
Сега да предположим, че вашата база данни се разраства, но искате да знаете колко бързо се е разраснала през последната седмица. Всъщност можете да следите нарастването както на данните, така и на размера на индекса точно в ClusterControl:
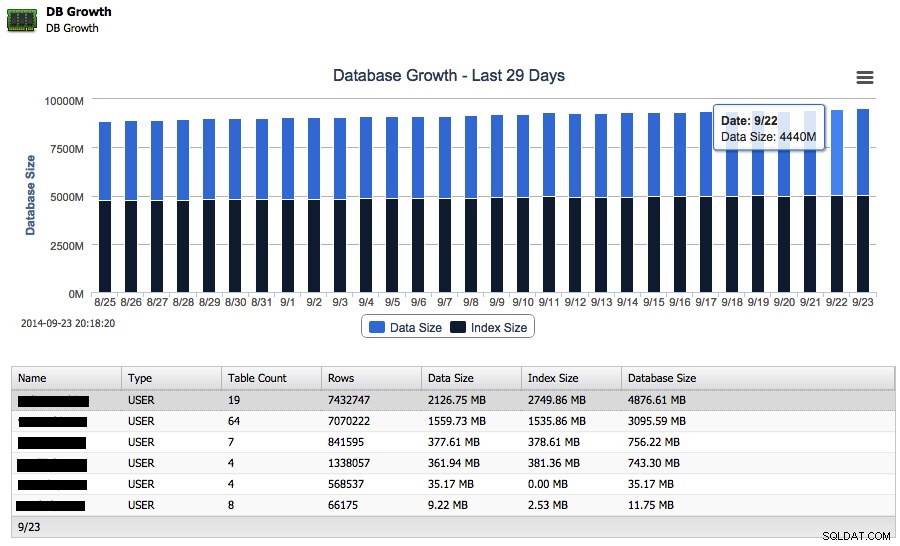
Освен общия ръст на диска, той може да отчете и първите 25 най-големи схеми.
Друга важна характеристика е Schema Analyzer в ClusterControl:
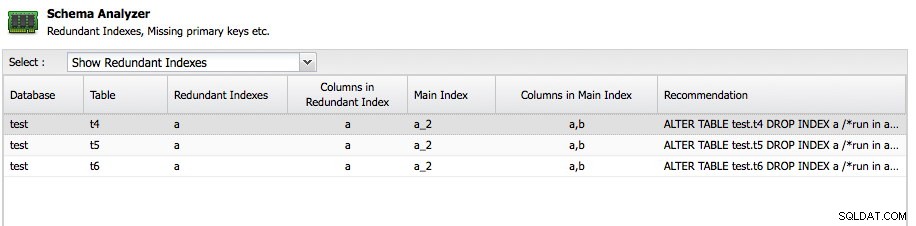
ClusterControl ще анализира вашите схеми и ще търси излишни индекси, MyISAM таблици и таблици без първичен ключ. Разбира се, изцяло от вас зависи да поддържате таблица без първичен ключ, защото някое приложение може да я е създало по този начин, но поне е страхотно да получите съветите тук безплатно. Schema Analyzer дори препоръчва необходимия оператор ALTER за отстраняване на проблема.
PostgreSQL
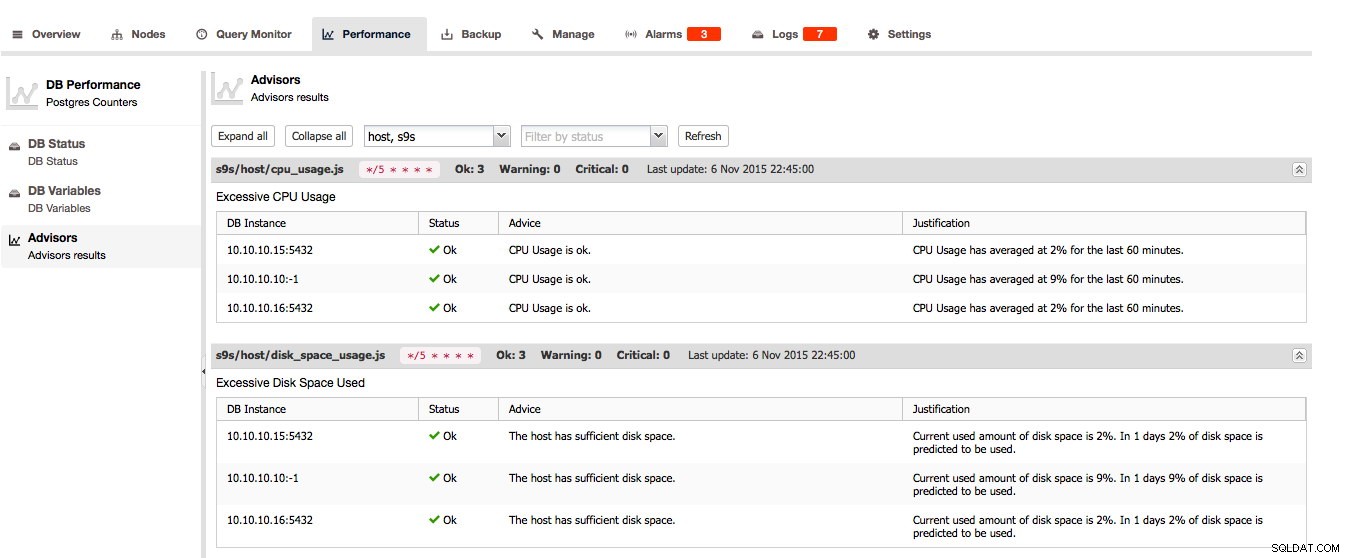
За PostgreSQL съветниците, състоянието на DB и DB променливите могат да бъдат намерени тук:
MongoDB
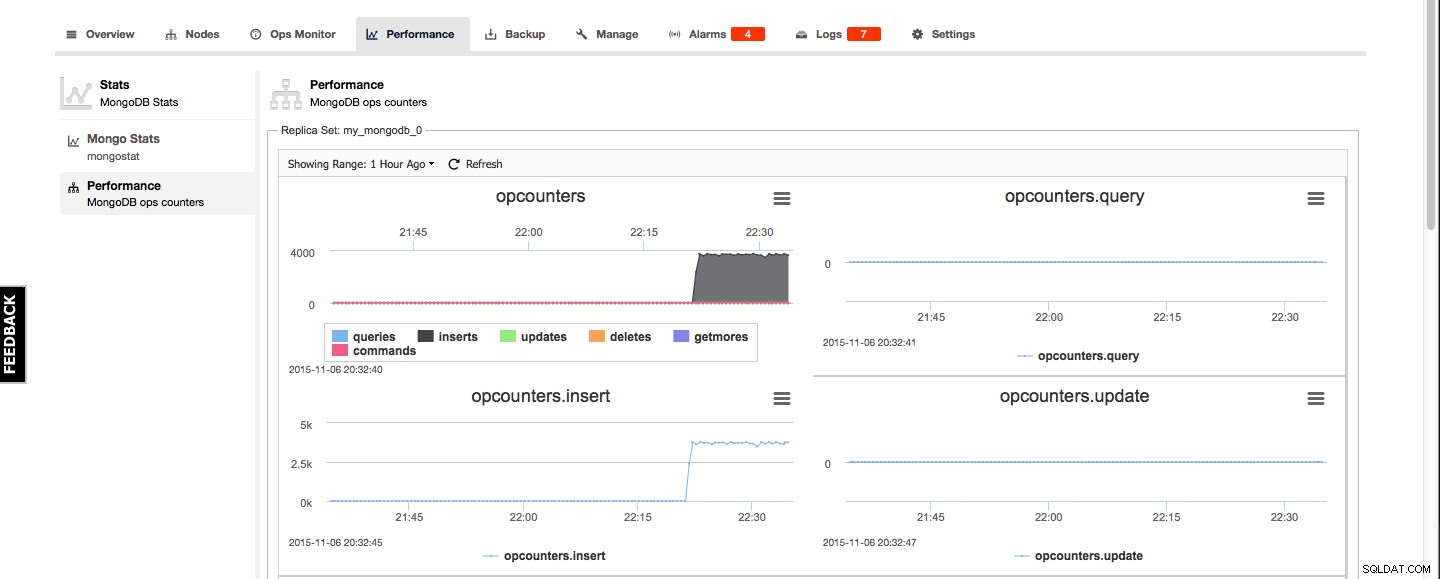
За MongoDB статистиката на Mongo и прегледът на производителността могат да бъдат намерени в раздела Производителност. Mongo Stats е преглед на изхода на mongostat, а прегледът на производителността дава добър графичен преглед на броячите на MongoDB:
Последни мисли
Показахме ви как да поддържате очните си ябълки върху най-важните функции за наблюдение и проверка на здравето на ClusterControl. Очевидно това е само началото на пътуването, тъй като скоро ще започнем друга серия от блогове за възможностите на Developer Studio и как можете да правите повечето от собствените си проверки. Също така имайте предвид, че нашата поддръжка за MongoDB и PostgreSQL не е толкова обширна, колкото нашия набор от инструменти MySQL, но ние непрекъснато подобряваме това.
Може да се запитате защо сме пропуснали наблюдението на производителността и проверките на здравето на HAProxy, ProxySQL и MaxScale. Направихме това умишлено, тъй като поредицата от блогове обхващаше само внедряването на клъстери досега, а не разполагането на HA компоненти. Така че това е темата, която ще разгледаме следващия път.



