Ефективността на базата данни не разчита само на фина настройка на най-критичните параметри, но също така стига до подходящо представяне на данни в свързаните колекции. Наскоро работих по проект, който разработи приложение за социален чат и след няколко дни тестване забелязахме известно забавяне при извличане на данни от базата данни. Нямахме толкова много потребители, така че изключихме настройката на параметрите на базата данни и се съсредоточихме върху нашите заявки, за да стигнем до основната причина.
За наша изненада разбрахме, че структурирането на данните ни не е напълно подходящо, тъй като имахме повече от 1 заявка за четене, за да извлечем конкретна информация.
Концептуалният модел за това как се поставят секциите на приложението зависи до голяма степен от структурата на колекциите на базата данни. Например, ако влезете в социално приложение, данните се подават в различните секции според дизайна на приложението, както е изобразено от представянето на базата данни.
Накратко, за добре проектирана база данни, структурата на схемата и връзките за събиране са ключови неща за нейната подобрена скорост и интегритет, както ще видим в следващите раздели.
Ще обсъдим факторите, които трябва да вземете предвид при моделирането на вашите данни.
Какво е моделиране на данни
Моделирането на данни обикновено е анализ на елементи от данни в база данни и доколко те са свързани с други обекти в тази база данни.
В MongoDB например можем да имаме колекция от потребители и колекция от профили. Колекцията от потребители изброява имената на потребителите за дадено приложение, докато колекцията от профили улавя настройките на профилите за всеки потребител.
При моделирането на данни трябва да проектираме връзка за свързване на всеки потребител към съответния профил. Накратко, моделирането на данни е основната стъпка в проектирането на база данни, освен формирането на архитектурната основа за обектно-ориентирано програмиране. Той също така дава представа за това как ще изглежда физическото приложение по време на напредъка на разработката. Архитектура за интеграция на база данни на приложение може да бъде илюстрирана както по-долу.
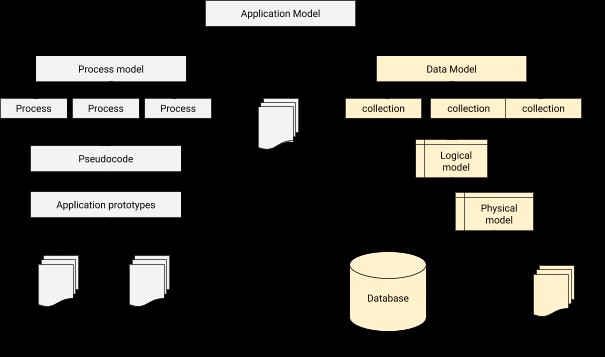
Процесът на моделиране на данни в MongoDB
Моделирането на данни идва с подобрена производителност на базата данни, но за сметка на някои съображения, които включват:
- Модели за извличане на данни
- Балансиране на нуждите на приложението като:заявки, актуализации и обработка на данни
- Характеристики за производителност на избраната машина за база данни
- Присъщата структура на самите данни
Структура на документа MongoDB
Документите в MongoDB играят основна роля при вземането на решение коя техника да се приложи за даден набор от данни. Обикновено има две връзки между данните, които са:
- Вградени данни
- Референтни данни
Вградени данни
В този случай свързаните данни се съхраняват в рамките на един документ или като стойност на поле, или като масив в самия документ. Основното предимство на този подход е, че данните са денормализирани и следователно предоставят възможност за манипулиране на свързаните данни в една операция с база данни. Следователно, това подобрява скоростта, с която се извършват CRUD операциите, поради което се изискват по-малко заявки. Нека разгледаме пример за документ по-долу:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}В този набор от данни имаме ученик с неговото име и друга допълнителна информация. Полето Настройки е вградено с обект, а освен това полето placeLocation също е вградено с обект с конфигурации за географска ширина и дължина. Всички данни за този студент се съдържат в един документ. Ако трябва да извлечем цялата информация за този ученик, просто стартираме:
db.students.findOne({StudentName : "George Beckonn"})Силни страни на вграждането
- Повишена скорост на достъп до данни:За подобрена скорост на достъп до данни, вграждането е най-добрият вариант, тъй като една операция на заявка може да манипулира данни в посочения документ само с едно търсене в базата данни.
- Намалено несъответствие на данните:По време на работа, ако нещо се обърка (например прекъсване на връзката с мрежата или прекъсване на захранването), може да бъдат засегнати само няколко броя документи, тъй като критериите често избират един документ.
- Намалени CRUD операции. Това означава, че операциите за четене всъщност ще надхвърлят броя на записите. Освен това е възможно да се актуализират свързани данни в една операция за атомно запис. Т.е. за горните данни можем да актуализираме телефонния номер и също така да увеличим разстоянието с тази единствена операция:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
Слабости на вграждането
- Ограничен размер на документа. Всички документи в MongoDB са ограничени до размера на BSON от 16 мегабайта. Следователно общият размер на документа заедно с вградените данни не трябва да надхвърля това ограничение. В противен случай за някои механизми за съхранение, като MMAPv1, данните може да прераснат и да доведат до фрагментация на данните в резултат на влошена производителност на запис.
- Дублиране на данни:множество копия на едни и същи данни затрудняват заявките за реплицираните данни и може да отнеме повече време за филтриране на вградени документи, което надхвърля основното предимство на вграждането.
Точкова нотация
Точковата нотация е идентификационната характеристика за вградени данни в програмната част. Използва се за достъп до елементи от вградено поле или масив. В примерните данни по-горе можем да върнем информация за ученика, чието местоположение е „Посолство“ с тази заявка, използвайки нотацията с точки.
db.users.find({'Settings.location': 'Embassy'})Референтни данни
Връзката с данни в този случай е, че свързаните данни се съхраняват в различни документи, но към тези свързани документи се издава някаква референтна връзка. За примерните данни по-горе можем да ги реконструираме по такъв начин, че:
Потребителски документ
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}Документ за настройки
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}Има 2 различни документа, но те са свързани с една и съща стойност за полетата _id и id. Така моделът на данните е нормализиран. Въпреки това, за да имаме достъп до информация от свързан документ, трябва да издадем допълнителни заявки и следователно това води до увеличено време за изпълнение. Например, ако искаме да актуализираме ParentPhone и свързаните с него настройки за разстояние, ще имаме поне 3 заявки, т.е.
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})Силни страни на препращане
- Последователност на данните. За всеки документ се поддържа канонична форма, поради което шансовете за несъответствие на данните са доста ниски.
- Подобрена цялост на данните. Благодарение на нормализирането е лесно да се актуализират данните независимо от продължителността на операцията и следователно да се гарантират правилни данни за всеки документ, без да се причинява объркване.
- Подобрено използване на кеша. Каноничните документи, до които се осъществява често достъп, се съхраняват в кеша, а не за вградени документи, до които се осъществява достъп няколко пъти.
- Ефективно използване на хардуера. Противно на вграждането, което може да доведе до надрастване на документа, препратката не насърчава растежа на документа, като по този начин намалява използването на диск и RAM.
- Подобрена гъвкавост, особено с голям набор от поддокументи.
- По-бързо пише.
Слабости на препращането
- Множество търсения:Тъй като трябва да търсим в редица документи, които отговарят на критериите, времето за четене се увеличава при извличане от диск. Освен това това може да доведе до пропуски в кеша.
- Много заявки се издават за постигане на някаква операция, следователно нормализираните модели на данни изискват повече двупосочни пътувания до сървъра за завършване на конкретна операция.
Нормализация на данните
Нормализирането на данните се отнася до преструктуриране на база данни в съответствие с някои нормални форми с цел подобряване на целостта на данните и намаляване на случаите на излишък на данни.
Моделирането на данни се върти около 2 основни техники за нормализиране, а именно:
-
Нормализирани модели на данни
Както се прилага в референтните данни, нормализирането разделя данните на множество колекции с препратки между новите колекции. Единична актуализация на документа ще бъде издадена към другата колекция и ще бъде приложена съответно към съответстващия документ. Това осигурява ефективно представяне на актуализиране на данни и обикновено се използва за данни, които се променят доста често.
-
Денормализирани модели на данни
Данните съдържат вградени документи, което прави операциите за четене доста ефективни. Това обаче е свързано с повече използване на дисково пространство, а също и с трудности при синхронизирането. Концепцията за денормализация може да се приложи добре към поддокументи, чиито данни не се променят често.
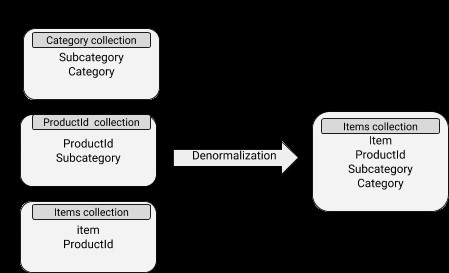
Схема MongoDB
Схемата е основно очертан скелет от полета и тип данни, които всяко поле трябва да съдържа за даден набор от данни. Като се има предвид гледната точка на SQL, всички редове са проектирани да имат едни и същи колони и всяка колона трябва да съдържа определения тип данни. В MongoDB обаче имаме гъвкава схема по подразбиране, която не поддържа еднакво съответствие за всички документи.
Гъвкава схема
Гъвкавата схема в MongoDB дефинира, че документите не трябва непременно да имат едни и същи полета или тип данни, тъй като полето може да се различава в различните документи в колекцията. Основното предимство на тази концепция е, че можете да добавяте нови полета, да премахвате съществуващи или да променяте стойностите на полетата на нов тип и по този начин да актуализирате документа в нова структура.
Например можем да имаме тези 2 документа в една и съща колекция:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}В първия документ имаме поле за възраст, докато във втория документ няма поле за възраст. Освен това типът данни за полето ParentPhone е число, докато във втория документ е зададен на false, което е булев тип.
Гъвкавостта на схемата улеснява съпоставянето на документи с обект и всеки документ може да съответства на полета с данни на представения обект.
Твърда схема
Колкото и да казахме, че тези документи могат да се различават един от друг, понякога може да решите да създадете твърда схема. Твърдата схема ще дефинира, че всички документи в колекция ще споделят една и съща структура и това ще ви даде по-добър шанс да зададете някои правила за валидиране на документи като начин за подобряване на целостта на данните по време на операции по вмъкване и актуализиране.
Типове данни за схема
Когато използвате някои сървърни драйвери за MongoDB, като mongoose, има някои предоставени типове данни, които ви позволяват да извършвате валидиране на данни. Основните типове данни са:
- Стринг
- Номер
- Булева
- Дата
- Буфер
- ObjectId
- Масив
- Смесено
- Десетично 128
- Карта
Разгледайте примерната схема по-долу
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});Примерен случай на употреба
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);Проверка на схема
Колкото и да можете да извършвате валидиране на данни от страната на приложението, винаги е добра практика да правите валидирането и от края на сървъра. Постигаме това, като използваме правилата за валидиране на схемата.
Тези правила се прилагат по време на операциите за вмъкване и актуализиране. Те се декларират на базата на събиране по време на процеса на създаване обикновено. Въпреки това, можете също да добавите правилата за валидиране на документи към съществуваща колекция, като използвате командата collMod с опции за валидиране, но тези правила не се прилагат към съществуващите документи, докато не се приложи актуализация към тях.
По същия начин, когато създавате нова колекция с помощта на командата db.createCollection(), можете да издадете опцията за валидатор. Разгледайте този пример, когато създавате колекция за ученици. От версия 3.6 MongoDB поддържа валидирането на JSON схемата, следователно всичко, от което се нуждаете, е да използвате оператора $jsonSchema.
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})В този дизайн на схема, ако се опитаме да вмъкнем нов документ като:
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})Функцията за обратно извикване ще върне грешката по-долу, поради някои нарушени правила за валидиране, като например предоставената стойност на годината, не е в посочените граници.
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})Освен това можете да добавите изрази на заявка към вашата опция за валидиране, като използвате оператори на заявка с изключение на $where, $text, near и $nearSphere, т.е.:
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )Нива на валидиране на схема
Както бе споменато по-горе, обикновено се издава валидиране на операциите за запис.
Валидирането обаче може да се приложи и към вече съществуващи документи.
Има 3 нива на валидиране:
- Строго:това е нивото на проверка по подразбиране на MongoDB и прилага правилата за валидиране към всички вмъквания и актуализации.
- Умерено:Правилата за валидиране се прилагат по време на вмъквания, актуализации и към вече съществуващи документи, които отговарят само на критериите за валидиране.
- Изключено:това ниво задава правилата за валидиране за дадена схема на нула, следователно няма да се извършва валидиране на документите.
Пример:
Нека вмъкнем данните по-долу в клиентска колекция.
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]Ако приложим умереното ниво на валидиране, използвайки:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )Правилата за валидиране ще бъдат приложени само към документа с _id от 1, тъй като той ще отговаря на всички критерии.
За втория документ, тъй като правилата за валидиране не отговарят на издадените критерии, документът няма да бъде валидиран.
Действия за проверка на схема
След извършване на валидиране на документи, може да има някои, които могат да нарушават правилата за валидиране. Винаги има нужда да се предостави действие, когато това се случи.
MongoDB предоставя две действия, които могат да бъдат издадени към документите, които не отговарят на правилата за валидиране:
- Грешка:това е действието по подразбиране на MongoDB, което отхвърля всяко вмъкване или актуализация, в случай че нарушава критериите за валидиране.
-
Предупреждение:Това действие ще запише нарушението в дневника на MongoDB, но позволява операцията за вмъкване или актуализиране да бъде завършена. Например:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })Ако се опитаме да вмъкнем документ като този:
db.students.insert( { name: "Amanda", status: "Updated" } );Gpa липсва независимо от факта, че е задължително поле в схемата, но тъй като действието за валидиране е настроено да предупреждава, документът ще бъде запазен и съобщение за грешка ще бъде записано в дневника на MongoDB.



