SCUMM (Severalnines ClusterControl Unified Monitoring &Management) е базирано на агенти решение с агенти, инсталирани на възлите на базата данни. Той предоставя набор от табла за наблюдение, които имат Prometheus като хранилище на данни със своя еластичен език за заявки и многоизмерен модел на данни. Prometheus изстъргва метрични данни от експортери, работещи на хостовете на базата данни.
Архитектурата ClusterControl SCUMM беше въведена с версия 1.7.0, разширяваща функционалността за наблюдение за MySQL, Galera Cluster, PostgreSQL и ProxySQL.
Новият ClusterControl 1.7.1 добавя наблюдение с висока разделителна способност за системите MongoDB.
 Списък на таблото за управление на ClusterControl MongoDB
Списък на таблото за управление на ClusterControl MongoDB В тази статия ще опишем двете основни табла за управление на MongoDB среди. MongoDB сървър и MongoDB Replicaset.
Табло за управление и списък с показатели
Списъкът с табла за управление и техните показатели:
| MongoDB сървър | |
|---|---|
| Име Име на ReplSet Време на работа на сървъра OpsCounters Връзки WT - Едновременни билети (четене) WT - Едновременни билети (запис) WT - Кеш Глобално заключване Твърди |
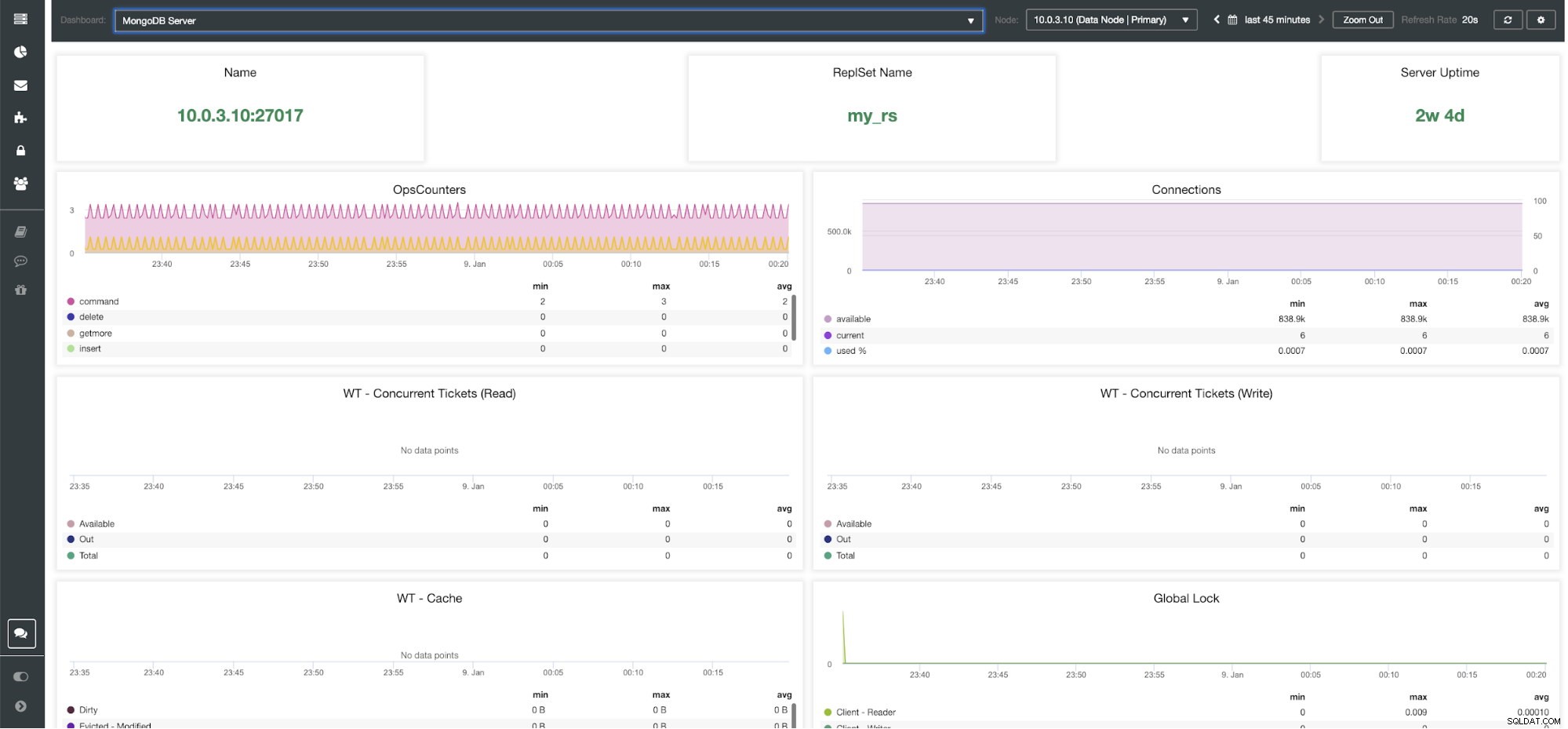 ClusterControl MongoDB Server Dashboard
ClusterControl MongoDB Server Dashboard| MongoDB ReplicaSet | |
|---|---|
| ReplSet Size ReplSet Name PRIMARY Server Version Replica Sets and Members Oplog Window per ReplSet Replication Headroom Общо PRIMARY/SECONDARY онлайн за ReplSet Отворени курсори за ReplSet ReplSet - Курсори с изтекъл време за набор Максимално забавяне на репликация за ReplSet Размер на Oplog OpsCounters Ping Time to Replica Set Members от PRIMARY(s) |
 Табло за управление на ClusterControl MongoDB ReplicaSet
Табло за управление на ClusterControl MongoDB ReplicaSet Системите за бази данни силно зависят от ресурсите на ОС, така че можете да намерите и две допълнителни табла за преглед на системата и Преглед на клъстера на вашата среда MongoDB.
| Преглед на системата | |
|---|---|
| Време на работа на сървъра Ядра на процесора Общо RAM Средно натоварване Използване на процесора Използване на RAM Използване на дисково пространство Използване на мрежа Disk IOPS Disk IO Util % Disk Throughput |
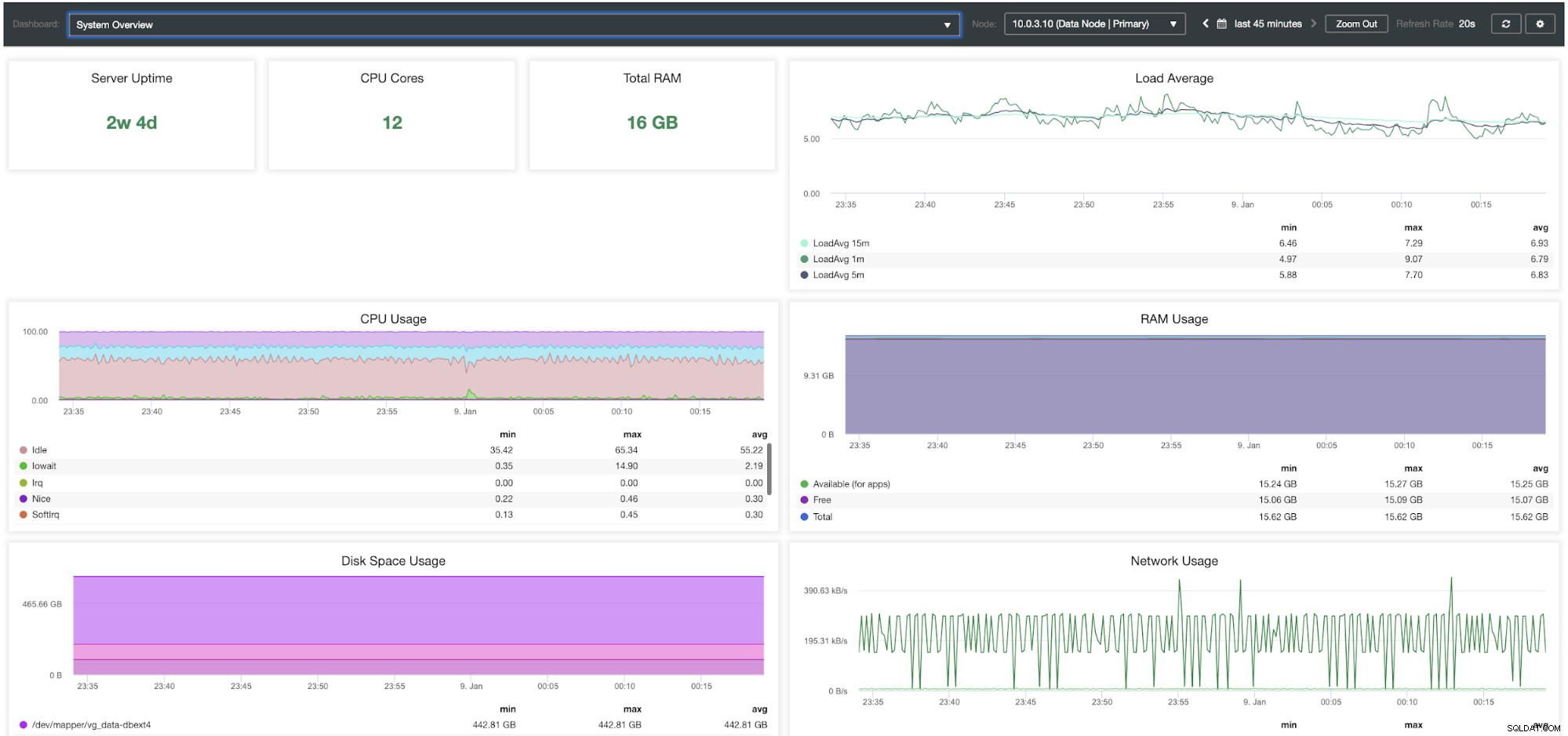 Общ преглед на системата за управление на ClusterControl
Общ преглед на системата за управление на ClusterControl| Преглед на клъстера | |
|---|---|
| Средно зареждане 1m Зареждане средно 5m Зареждане средно 15m Налична памет за приложения Мрежа TX Мрежа RX IOPS за четене на диск IOPS за запис на диск Запис на диск + IOPS за четене |
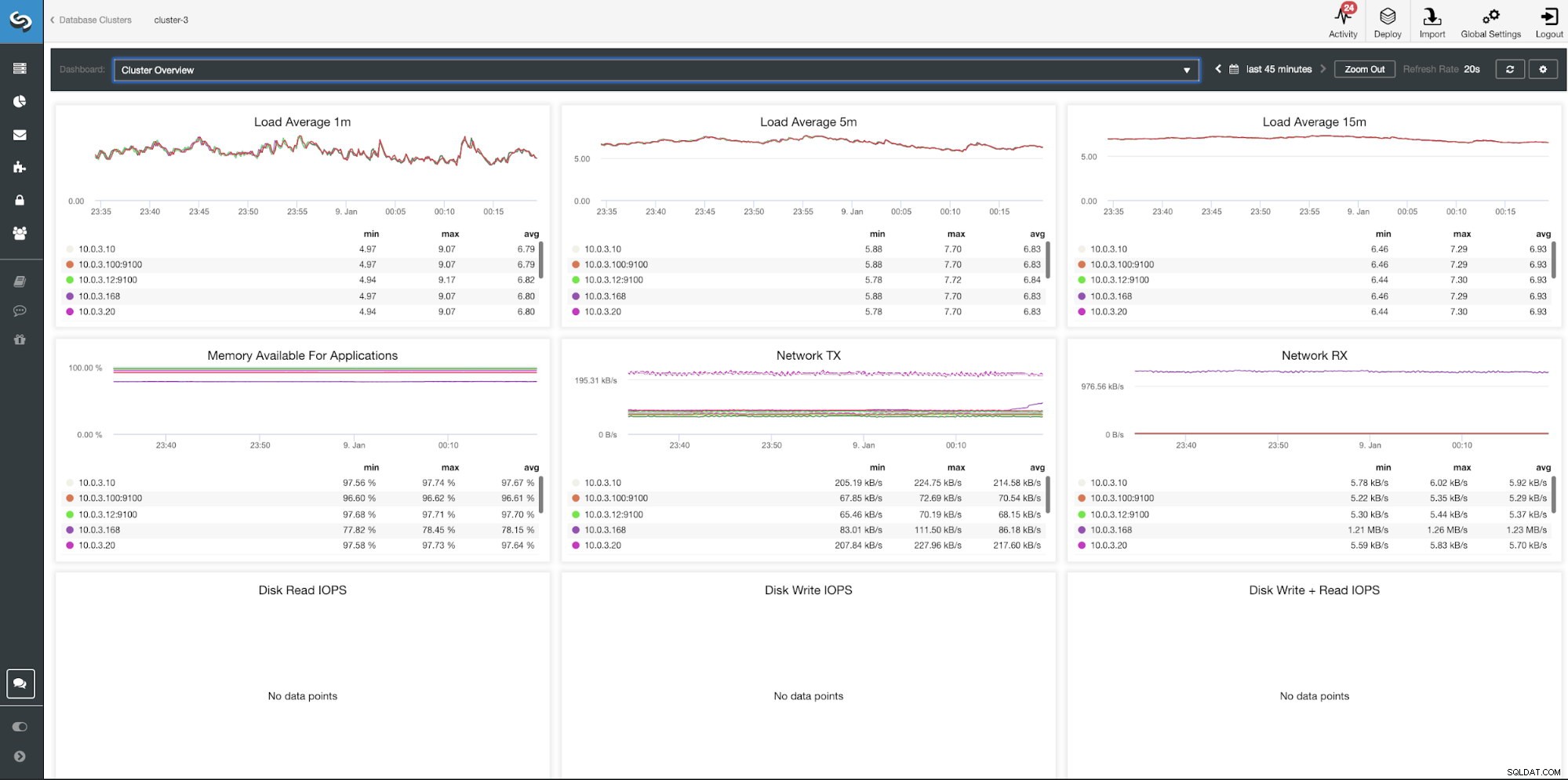 Табло за управление с преглед на клъстера ClusterControl
Табло за управление с преглед на клъстера ClusterControl Табло за управление на сървъра MongoDB
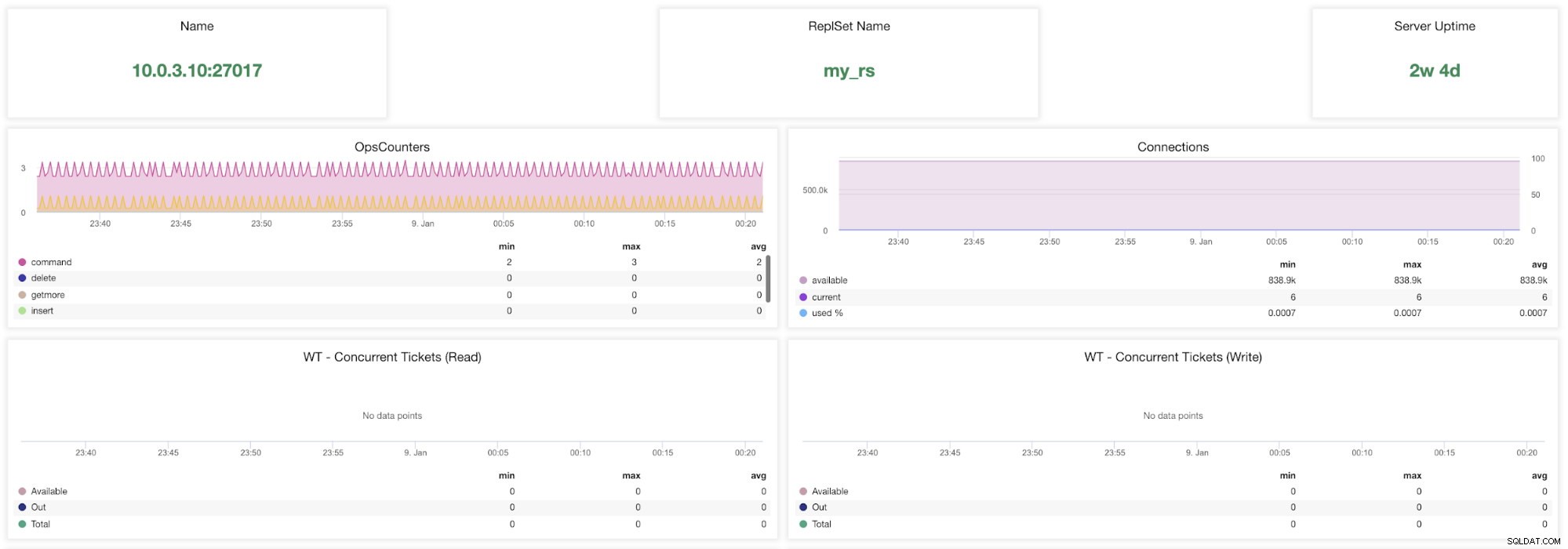 ClusterControl MongoDB метрики
ClusterControl MongoDB метрики Име - Адрес на сървъра и порт.
Име на ReplsSet - Представя името на набора реплики, към който принадлежи сървърът.
Време на работа на сървъра - Време от последното рестартиране на сървъра.
Ops Counters - Брой заявки, получени през избрания период от време, разбити по вида на операцията. Тези преброявания включват всички получени операции, включително тези, които не са били успешни.
Връзки - Тази графика показва един от най-важните показатели за наблюдение - броят на връзките, получени през избрания период от време, включително неуспешни заявки. Ненормалното натоварване на трафика може да доведе до проблеми с производителността. Ако MongoDB изчерпва връзките си, може да не успее да обработва входящите заявки своевременно.
WT - едновременни билети (четене) / WT - едновременни билети (записване) Тези две графики показват билети за четене и запис, които контролират едновременността в WiredTiger (WT). Билетите за WT контролират колко операции за четене и запис могат да се изпълнят на механизма за съхранение по едно и също време. Когато наличните билети за четене и запис паднат до нула, броят на едновременно изпълняваните операции е равен на конфигурираните стойности за четене/запис. Това означава, че всички други операции трябва да изчакат, докато една от работещите нишки завърши работата си върху механизма за съхранение, преди да се изпълнят.
 ClusterControl MongoDB метрики
ClusterControl MongoDB метрики WT – Кеш (Мръсно, изгонено - променено, изгонено - непроменено, макс.) - Размерът на кеша е най-важното копче за WiredTiger. По подразбиране MongoDB 3.x запазва 50% (60% в 3.2) от наличната памет за своя кеш на данни.
Глобално заключване (Client-Read, Client - Write, Current Queue - Reader, Current Queue - Writer) - Лошите модели на проектиране на схеми или тежките заявки за четене и запис от много клиенти могат да причинят обширно заключване. Когато това се случи, има нужда да се поддържа последователност и да се избягват конфликти при записване.
За да постигне това, MongoDB използва многогранично заключване, което позволява операциите по заключване да се случват на различни нива, като глобално ниво, база данни или ниво на събиране .
Твърди (съобщ., редовни, превъртания, потребител) – Тази графика показва броя на заявленията, които се издигат всяка секунда. Високите стойности и отклоненията от тенденциите трябва да бъдат прегледани.
Табло за управление на MongoDB ReplicaSet
Показателите, показани в това табло за управление, имат значение само ако използвате набор от реплики.
 ClusterControl MongoDB ReplicaSet Metrics
ClusterControl MongoDB ReplicaSet Metrics Размер на набор от реплики - Броят на членовете в комплекта реплика. Стандартното внедряване на набор от реплики за производствената система е тричленен набор от реплика. Най-общо казано, препоръчва се набор от реплика да има нечетен брой членове с право на глас. Толерантността на грешки за набор от реплики е броят на членовете, които могат да станат недостъпни и все още да оставят достатъчно членове в набора, за да изберат първичен. Толерантността на грешки за трима члена е един, за пет е два и т.н.
Име на ReplSet - Това е името, присвоено в конфигурационния файл на MongoDB. Името се отнася до /etc/mongod.conf replSet стойност.
ОСНОВНО - Първичният възел получава всички операции на запис и записва всички други промени в своя набор от данни в своя дневник за операции. Стойността е да идентифицирате IP и порта на вашия първичен възел в клъстера от реплика на MongoDB.
Версия на сървъра - Идентифицирайте версията на сървъра. ClusterControl версия 1.7.1 поддържа MongoDB версии 3.2/3.4/3.6/4.0.
Набори реплики и членове (min, max, avg) – Тази графика може да ви помогне да идентифицирате активни членове през периода от време. Можете да проследявате минималния, максималния и средния брой на първичните и вторичните възли и как тези числа се променят с течение на времето. Всяко отклонение може да повлияе на отказоустойчивостта и наличността на клъстера.
Oplog прозорец за ReplSet - Прозорецът за репликация е основен показател за наблюдение. MongoDB oplog е единична колекция, която е ограничена в (предварително зададен) размер. Може да се опише като разликата между първото и последното времеви печат в oplog.rs. Това е времето, през което вторичният може да бъде офлайн, преди да е необходимо първоначално синхронизиране за синхронизиране на екземпляра. Тези показатели ви информират колко време ви остава, преди следващата ни транзакция да бъде премахната от oplog.
 ClusterControl MongoDB ReplicaSet Metrics
ClusterControl MongoDB ReplicaSet Metrics Разстояние за репликация - Тази графика представя разликата между основния oplog прозорец и забавянето на репликацията на вторичните възли. Оплогът на MongoDB е ограничен по размер и ако възелът изостава твърде много, той няма да може да го настигне. Ако това се случи, ще бъде издадена пълна синхронизация и това е скъпа операция, която трябва да се избягва по всяко време.
Общо PRIMARY/SECONDARY онлайн на ReplSet - Общ брой възли на клъстера за периода от време.
Отворени курсори за ReplSet (закрепени, изчакване, общо) - Заявката за четене идва с курсор, който е указател към набора от данни на резултата. Той ще остане отворен на сървъра и следователно ще консумира памет, освен ако не бъде прекратен от настройката по подразбиране на MongoDB. Трябва да идентифицирате неактивни курсори и да ги отрежете, за да спестите памет.
ReplSet - Курсори за изчакване на SetsMax Репликационно забавяне на ReplSet - Закъснението на репликацията е много важно, за да следите, ако увеличавате четенията чрез добавяне на още вторични. MongoDB ще използва тези вторични данни само ако не изостават твърде много. Ако вторичният има забавяне на репликацията, рискувате да обслужите остарели данни, които вече са били презаписани на основния.
OplogSize - Някои натоварвания може да изискват по-голям размер на oplog. Актуализации на множество документи наведнъж, изтривания са равни на същото количество данни като вмъкване или значителния брой актуализации на място.
OpsConters - Тази графика показва броя на изпълнените заявки.
Време за пинг за реплика, задаване на член от основен - Това ви позволява да откривате членове на набора от реплики, които не работят или са недостъпни от основния възел.
Заключителни бележки
Новата функция на таблото за управление на MongoDB ClusterControl 1.7.1 е достъпна безплатно в Community Edition. Оперативните екипи на базата данни могат да спечелят от това, като използват графиките с висока разделителна способност, особено когато изпълняват ежедневните си процедури като анализ на основната причина и планиране на капацитета.
Въпросът е само с едно щракване, за да разположите нови агенти за наблюдение. ClusterControl инсталира агенти на Prometheus, конфигурира метрики и поддържа достъп до конфигурацията на експортерите на Prometheus чрез своя GUI, така че можете по-добре да управлявате конфигурацията на параметри като флагове на колектор за експортерите (Prometheus).
Чрез адекватно наблюдение на броя на заявките за четене и запис можете да предотвратите претоварване на ресурсите, бързо да намерите произхода на потенциалните претоварвания и да знаете кога да увеличите мащаба.



