MongoDB е NoSQL база данни, която поддържа голямо разнообразие от източници на входни набори от данни. Той е в състояние да съхранява данни в гъвкави документи, подобни на JSON, което означава, че полетата или метаданните могат да варират от документ до документ и структурата на данните може да се променя с течение на времето. Моделът на документа прави данните лесни за работа чрез съпоставяне с обектите в кода на приложението. MongoDB е известен още като разпределена база данни в основата си, така че високата наличност, хоризонталното мащабиране и географското разпространение са вградени и лесни за използване. Предлага се с възможност за безпроблемна промяна на параметрите за обучение на модел. Data Scientists могат лесно да обединят структурирането на данни с това генериране на модел.
Какво е машинно обучение?
Машинното обучение е науката за карането на компютрите да се учат и да действат като хората и да подобряват обучението си с течение на времето по автономен начин. Процесът на обучение започва с наблюдения или данни, като примери, пряк опит или инструкции, за да се търсят модели в данните и да се вземат по-добри решения в бъдеще въз основа на примерите, които предоставяме. Основната цел е да позволи на компютрите да се учат автоматично без човешка намеса или помощ и съответно да коригират действията.
Богат модел за програмиране и заявки
MongoDB предлага както собствени драйвери, така и сертифицирани конектори за разработчици и учени по данни, изграждащи модели за машинно обучение с данни от MongoDB. PyMongo е страхотна библиотека за вграждане на синтаксис на MongoDB в кода на Python. Можем да импортираме всички функции и методи на MongoDB, за да ги използваме в нашия код за машинно обучение. Това е страхотна техника за получаване на многоезична функционалност в един код. Допълнителното предимство е, че можете да използвате основните характеристики на тези езици за програмиране, за да създадете ефективно приложение.
Езикът за заявки MongoDB с богати вторични индекси позволява на разработчиците да създават приложения, които могат да заявяват и анализират данните в множество измерения. Достъпът до данни може да се осъществява чрез единични ключове, диапазони, текстово търсене, графики и геопространствени заявки чрез сложни агрегации и задания MapReduce, връщащи отговори за милисекунди.
За да паралелизира обработката на данни в клъстер на разпределена база данни, MongoDB предоставя конвейера за агрегация и MapReduce. Конвейерът за агрегиране на MongoDB е моделиран по концепцията за тръбопроводи за обработка на данни. Документите влизат в многоетапен тръбопровод, който трансформира документите в обобщен резултат, използвайки собствени операции, изпълнявани в MongoDB. Най-основните етапи на конвейера осигуряват филтри, които работят като заявки, и трансформации на документи, които променят формата на изходния документ. Други операции на конвейера предоставят инструменти за групиране и сортиране на документи по специфични полета, както и инструменти за агрегиране на съдържанието на масиви, включително масиви от документи. В допълнение, етапите на конвейера могат да използват оператори за задачи като изчисляване на средните или стандартните отклонения в колекциите от документи и манипулиране на низове. MongoDB също така предоставя собствени операции MapReduce в базата данни, като използва персонализирани функции на JavaScript за изпълнение на картата и намаляване на етапите.
В допълнение към собствената си рамка за заявки, MongoDB предлага и високопроизводителен конектор за Apache Spark. Конекторът разкрива всички библиотеки на Spark, включително Python, R, Scala и Java. Данните MongoDB се материализират като DataFrames и Datasets за анализ с машинно обучение, графики, стрийминг и SQL API.
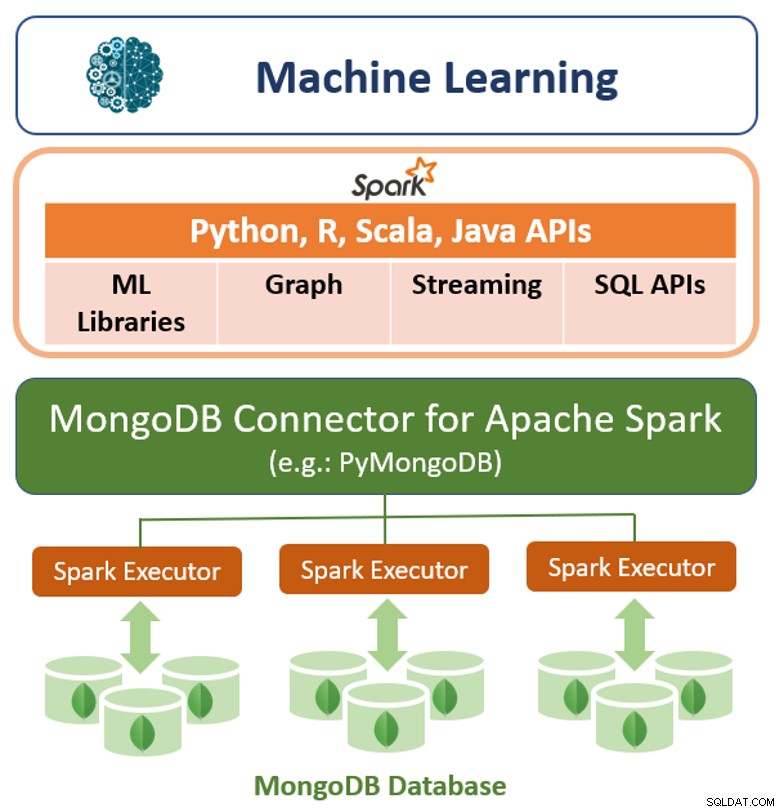
Конекторът MongoDB за Apache Spark може да се възползва от конвейера за агрегация на MongoDB и вторичния индекси за извличане, филтриране и обработка само на диапазона от данни, от който се нуждае – например, анализ на всички клиенти, разположени в определена география. Това е много различно от простите NoSQL хранилища за данни, които не поддържат нито вторични индекси, нито агрегации в базата данни. В тези случаи Spark ще трябва да извлече всички данни въз основа на прост първичен ключ, дори ако за процеса на Spark се изисква само подмножество от тези данни. Това означава повече разходи за обработка, повече хардуер и по-дълго време за анализ за учените по данни и инженерите. За да увеличи максимално производителността в големи, разпределени набори от данни, конекторът MongoDB за Apache Spark може да локализира съвместно устойчиви разпределени набори от данни (RDD) с изходния възел MongoDB, като по този начин минимизира движението на данни в клъстера и намалява латентността.
Ефективност, мащабируемост и излишък
Времето за обучение на модела може да бъде намалено чрез изграждане на платформата за машинно обучение върху производителен и мащабируем слой база данни. MongoDB предлага редица иновации за увеличаване на пропускателната способност и минимизиране на латентността на работните натоварвания за машинно обучение:
- WiredTiger е известен като машина за съхранение по подразбиране за MongoDB, разработена от архитектите на Berkeley DB, най-широко разпространеният вграден софтуер за управление на данни в света. WiredTiger мащабира модерни многоядрени архитектури. Използвайки различни техники за програмиране, като указатели за опасност, алгоритми без заключване, бързо блокиране и предаване на съобщения, WiredTiger максимизира изчислителната работа на ядро на процесора и такт. За да сведе до минимум излишните разходи на диска и I/O, WiredTiger използва компактни файлови формати и компресия на съхранение.
- За най-чувствителните към забавяне приложения за машинно обучение, MongoDB може да бъде конфигуриран с механизма за съхранение в паметта. Базиран на WiredTiger, този механизъм за съхранение дава на потребителите предимствата на изчисленията в паметта, без да се отменя богатата гъвкавост на заявките, анализите в реално време и мащабируемия капацитет, предлагани от конвенционалните дискови бази данни.
- За да паралелизира обучението на модела и да мащабира входните набори от данни извън един възел, MongoDB използва техника, наречена разделяне, която разпределя обработката и данните между клъстери от хардуер със суровини. Разделянето на MongoDB е напълно еластично, автоматично балансира данните в клъстера, когато входният набор от данни нараства или когато възлите се добавят и премахват.
- В рамките на клъстер MongoDB данните от всеки шард се разпределят автоматично до множество реплики, хоствани на отделни възли. Наборите реплики на MongoDB осигуряват излишък за възстановяване на данни за обучение в случай на неуспех, намалявайки излишните разходи за контролни точки.
Настройваща се последователност на MongoDB
MongoDB е силно последователен по подразбиране, позволявайки на приложенията за машинно обучение незабавно да прочетат това, което е записано в базата данни, като по този начин се избягва сложността на разработчиците, наложена от евентуално последователни системи. Силната последователност ще осигури най-точните резултати за алгоритмите за машинно обучение; в някои сценарии обаче е приемливо да се търгува последователност срещу конкретни цели за производителност чрез разпределяне на заявки в клъстер от вторични членове на набора реплики на MongoDB.
Гъвкав модел на данни в MongoDB
Моделът на документни данни на MongoDB улеснява разработчиците и учените по данни да съхраняват и агрегират данни от всякаква форма на структура в базата данни, без да се отказват от сложни правила за валидиране, за да управляват качеството на данните. Схемата може да бъде динамично модифицирана без прекъсване на приложение или база данни, което е резултат от скъпоструващи модификации на схеми или редизайн, извършен от системите за релационни бази данни.
Записването на модели в база данни и зареждането им с помощта на python също е лесен и много необходим метод. Изборът на MongoDB също е предимство, тъй като е база данни с документи с отворен код, а също и водеща NoSQL база данни. MongoDB също така служи като конектор за разпределената рамка на apache spark.
Динамичната природа на MongoDB
Динамичната природа на MongoDB позволява използването му в задачи за манипулиране на база данни при разработване на приложения за машинно обучение. Това е много ефективен и лесен начин за извършване на анализ на набори от данни и бази данни. Резултатът от анализа може да се използва при обучение на модели за машинно обучение. Препоръчва се анализаторите на данни и програмистите за машинно обучение да придобият майсторство в MongoDB и да го прилагат в много различни приложения. Рамката за агрегиране на MongoDB се използва за работен процес на науката за данни за извършване на анализ на данни за множество приложения.
Заключение
MongoDB предлага няколко различни възможности като:гъвкав модел на данни, богато програмиране, модел на данни, модел на заявка и неговата регулируема последователност, които правят обучението и използването на алгоритми за машинно обучение много по-лесни, отколкото с традиционните релационни бази данни. Изпълнението на MongoDB като бекенд база данни ще даде възможност за съхраняване и обогатяване на данни за машинно обучение позволява постоянство и повишена ефективност.



