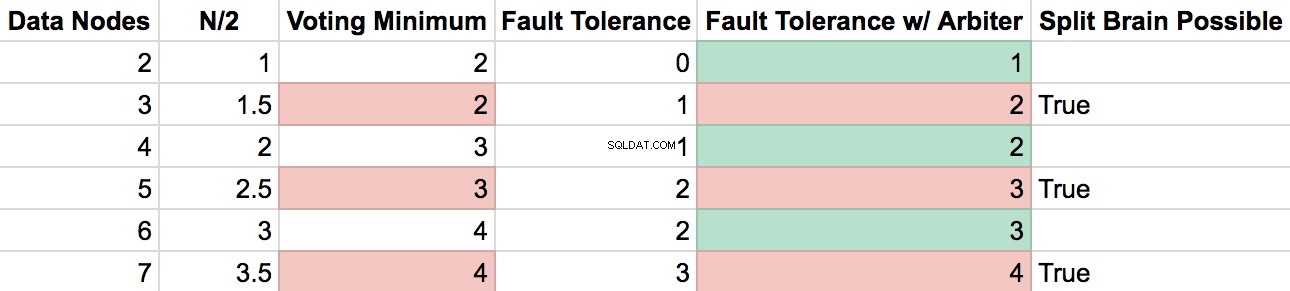
Създадох електронна таблица, за да илюстрирам по-добре ефекта на възлите Arbiter в набор от реплики.
Основно се свежда до следните точки:
- С RS от 2 възела за данни , загубата на 1 сървър ви води под минимума за гласуване (който е "по-голям от N/2"). Арбитър решава това.
- С RS от четно номерирани възли за данни , добавянето на арбитър увеличава вашата толерантност към грешки с 1, без да прави възможно да имате 2 клъстера за гласуване поради разделяне.
- С RS от нечетно номерирани възли с данни , добавянето на арбитър би позволило разделяне да създаде 2 изолирани клъстера с гласове „повече от N/2“ и следователно сценарий с разделен мозък.
Изборите са обяснени [с лоши] подробности тук. В този документ заявява че РС може да има 50 членове (четен брой) и 7 членове с право на глас. Наблягам на "състояния", защото не обяснява как работи. Струва ми се, че ако имате разделение с 4 членове (всички гласуващи) от едната страна и 46 членове (3 гласуващи) от другата, бихте предпочели 46-те да изберат първични и 4-те да бъдат четене- само клъстер. Но точно това предотвратява "ограниченото гласуване". В тази ситуация всъщност ще имате 4-членен клъстер с основен и 46-членен клъстер, който се чете само. Обясняването на смисъла в това е извън обхвата на този въпрос и отвъд познанията ми.



