Е, анализирането на разпространението на коронавируса SARS-CoV-2 не беше моят мечтан случай на употреба . Но въз основа на отговорите на статията на Ferry Djaja за проследяване на коронавирус COVID-19 почти в реално време със статията на SAP HANA XSA реших да добавя и моите две гроши.
[Актуализирано на 20-03-30 с променените връзки към изходните данни; и изходът на новата карта въз основа на новата детайлност на данните. Благодаря Дъглас Малтби за коментара ви!]
В публикацията си в блога Фери използва JavaScript в SAP HANA XSA, за да извлече данните от CSV файлове, актуализирани ежедневно от университета Джон Хопкинс.
Бих искал да ви покажа как можете да изтеглите и заредите тези файлове в SAP HANA, като използвате само няколко реда код благодарение на SAP HANA Python Client API за машинно обучение (hana_ml пакет).
Някои хора бяха объркани с визуализацията на картата в края — моля, имайте предвид, че тази статия се фокусира върху техническата употреба, свързваща различни компоненти, а не върху извършването на задълбочен анализ на данни за коронавирус.
Вземете среда на Python, напр. Юпитер
За това ще използвам Jupyter в контейнера на Docker. Моля, вижте предишната ми публикация Разбиране на контейнерите (част 05):споделени файлове между хоста и контейнерите, ако не сте запознати как да го стартирате. Освен това можете да направите всички същите стъпки по-долу от всяка друга среда на Python.
И така, имам моя контейнер myjupyter01 бягане. Свързан съм с потребителския интерфейс на Jupyter, както е описано в предишния блог.
Инсталирайте hana_ml
Изображението на Jupyter, което използвах от регистъра на Docker Hub, беше jupyter/minimal-notebook . Той вече съдържа някои популярни пакети за обработка на данни, като pandas .
Но освен това трябва да инсталирам hana_ml , който в текущата си версия 1.0.8 е достъпен в хранилището на PyPI:https://pypi.org/project/hana-ml/.
Командата за стартиране на инсталацията е python -m pip install hana_ml , но тъй като го стартирам от бележника на Jupyter с ядрото на Python3, трябва да го стартирам с ! в началото:
!python -m pip install hana_ml
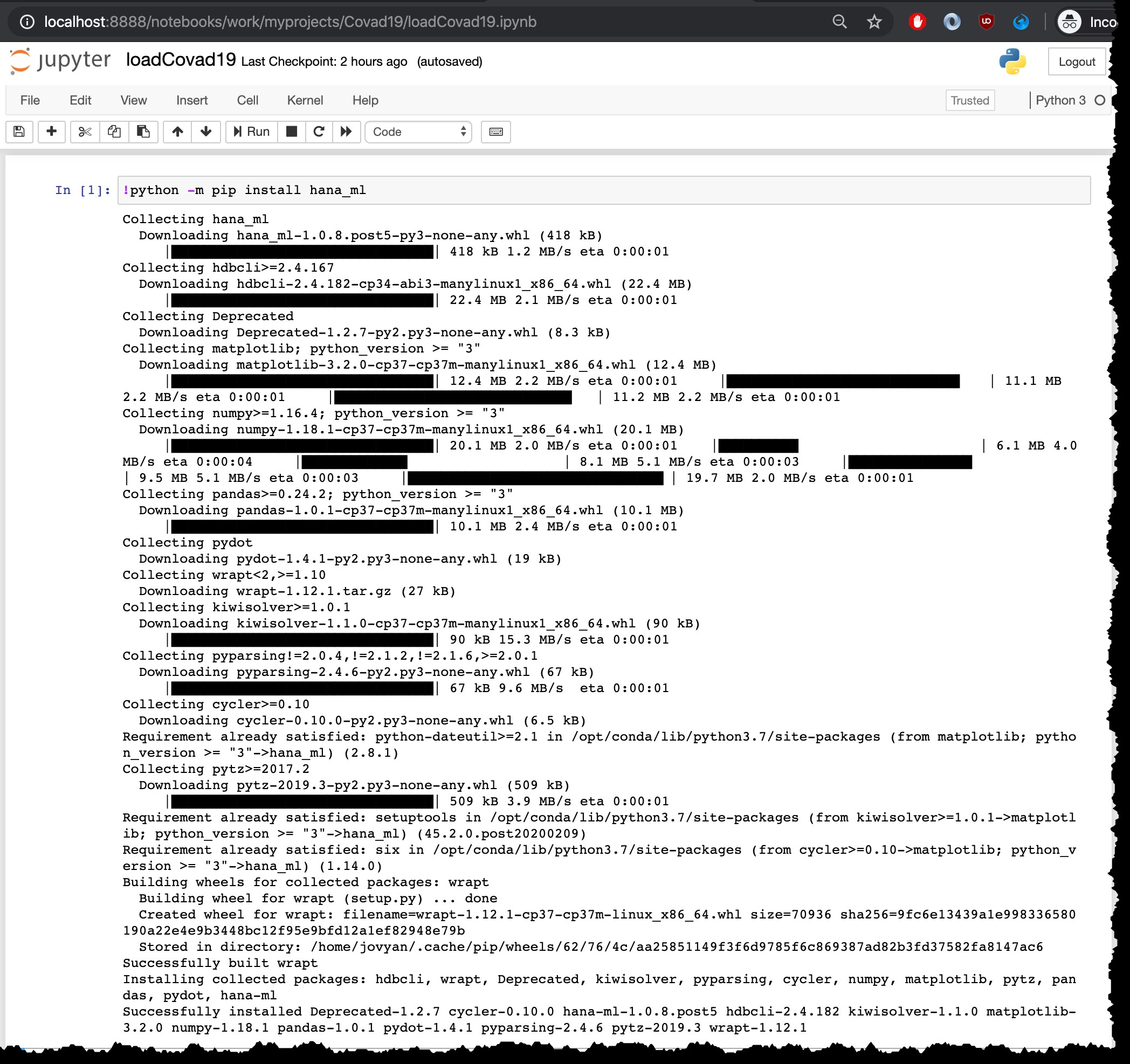
Очевидно тази стъпка на инсталиране трябва да се направи само веднъж. Няма нужда да го стартирате отново в същия контейнер, напр. при презареждане на най-новите файлове.
Използвайте pandas за импортиране на файлове с данни
Нека импортираме същите три файла (confirmed , deaths , recovered ) от https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series, както Фери използва в своя пример.
import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
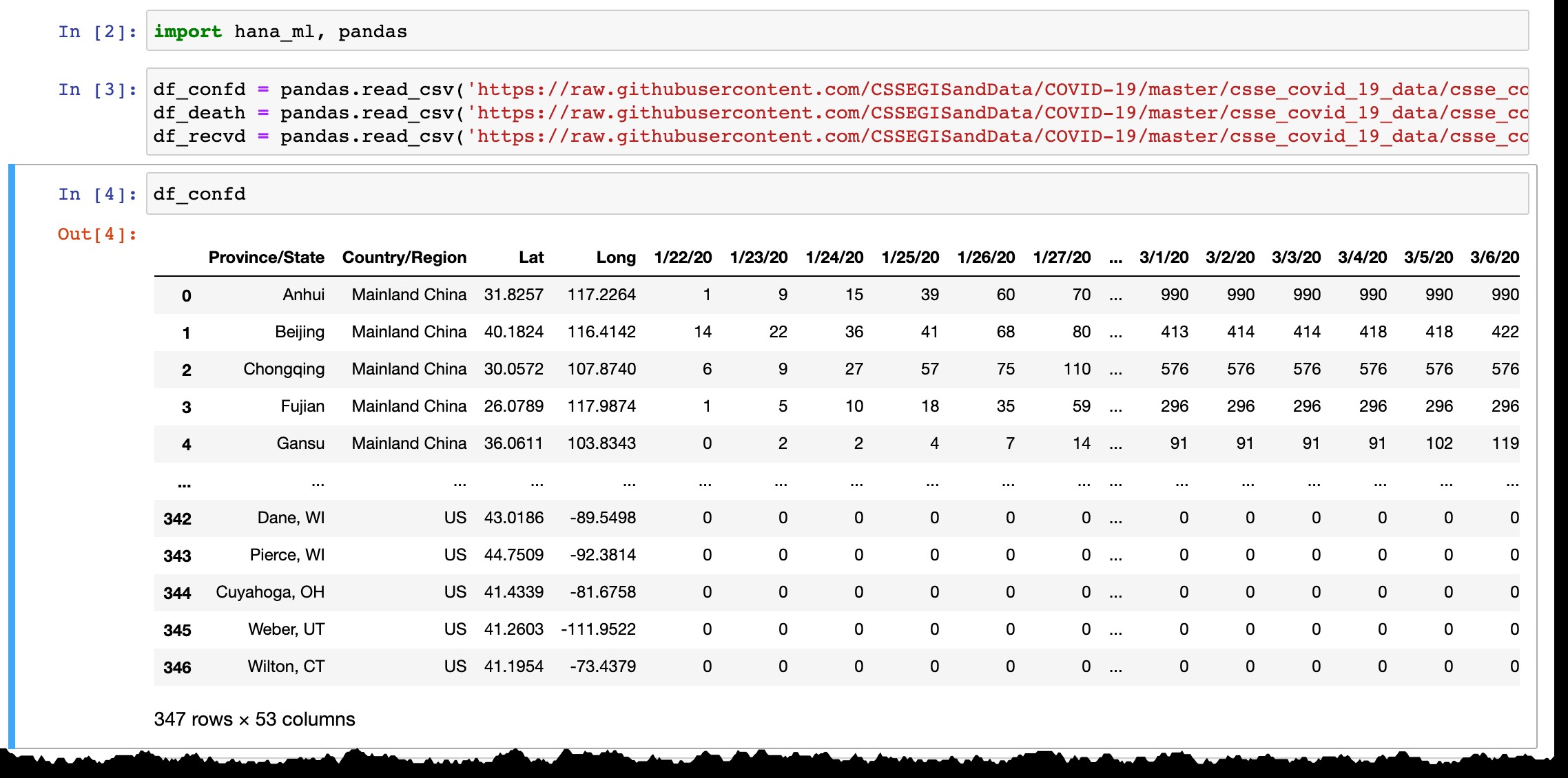
Както можете да видите от визуализацията на рамката с данни Pandas, тя изброява само държави или провинции с потвърдени случаи и всеки ден новата колона се добавя с най-новите данни от предишния ден. Редове се добавят, когато първият случай(и) се потвърди в новия регион.
Използвайте pandas за повторно форматиране на рамката с данни
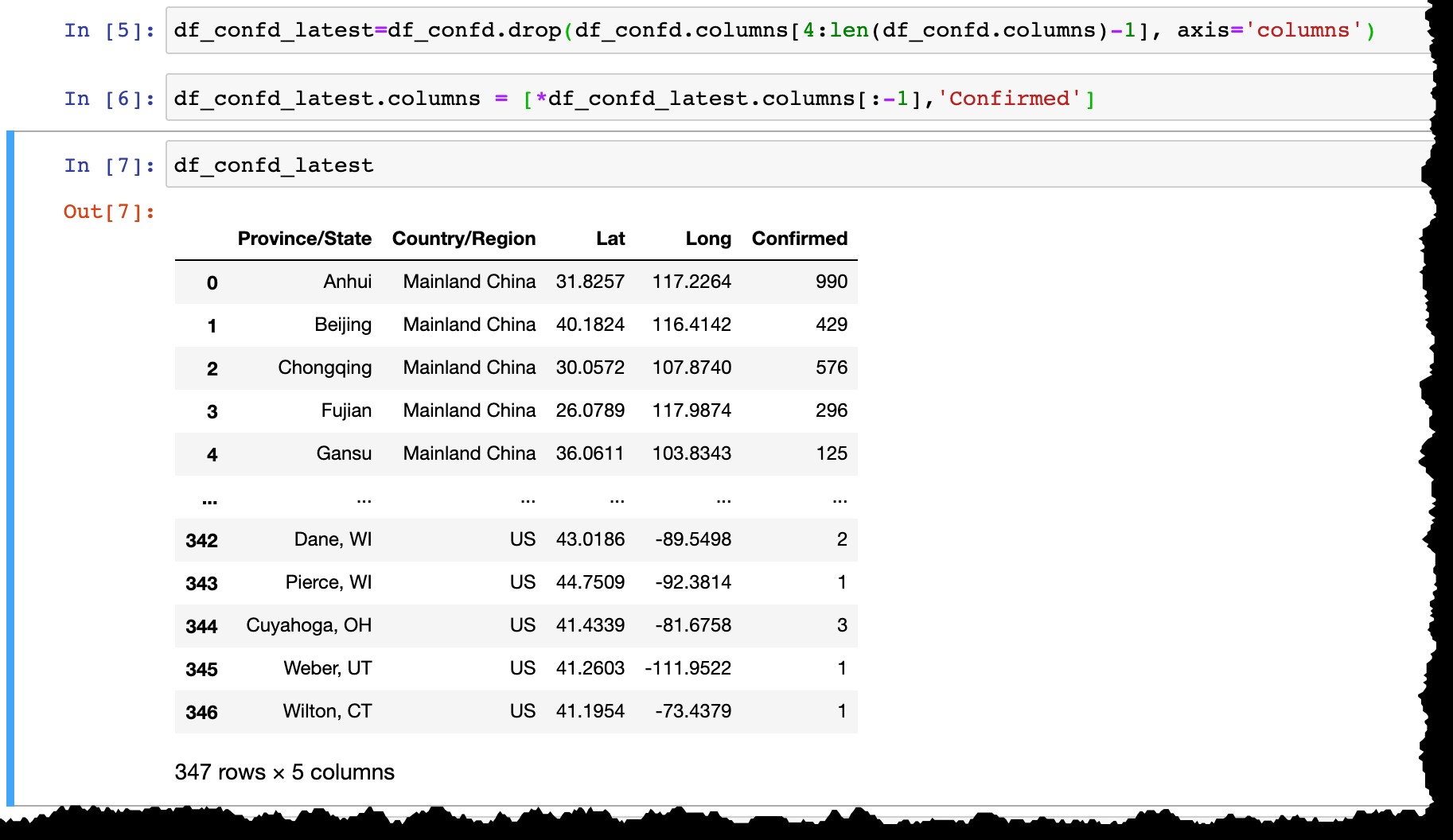
Преди да запазим данните в SAP HANA, нека:
- Премахнете всички колони с дата, с изключение на последната,
- Преименувайте последната колона от действителната дата (като днешната
3/10/20доConfirmed).
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']
Използвайте hana_ml за запазване на данните в таблицата SAP HANA
Сега нека се свържа с моя екземпляр на SAP HANA Express с потребителя hanaml който вече съществува там...
cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')
…и конвертирайте рамката с данни на Pandas df_confd_latest в рамка от данни на HANA hdf_confd .
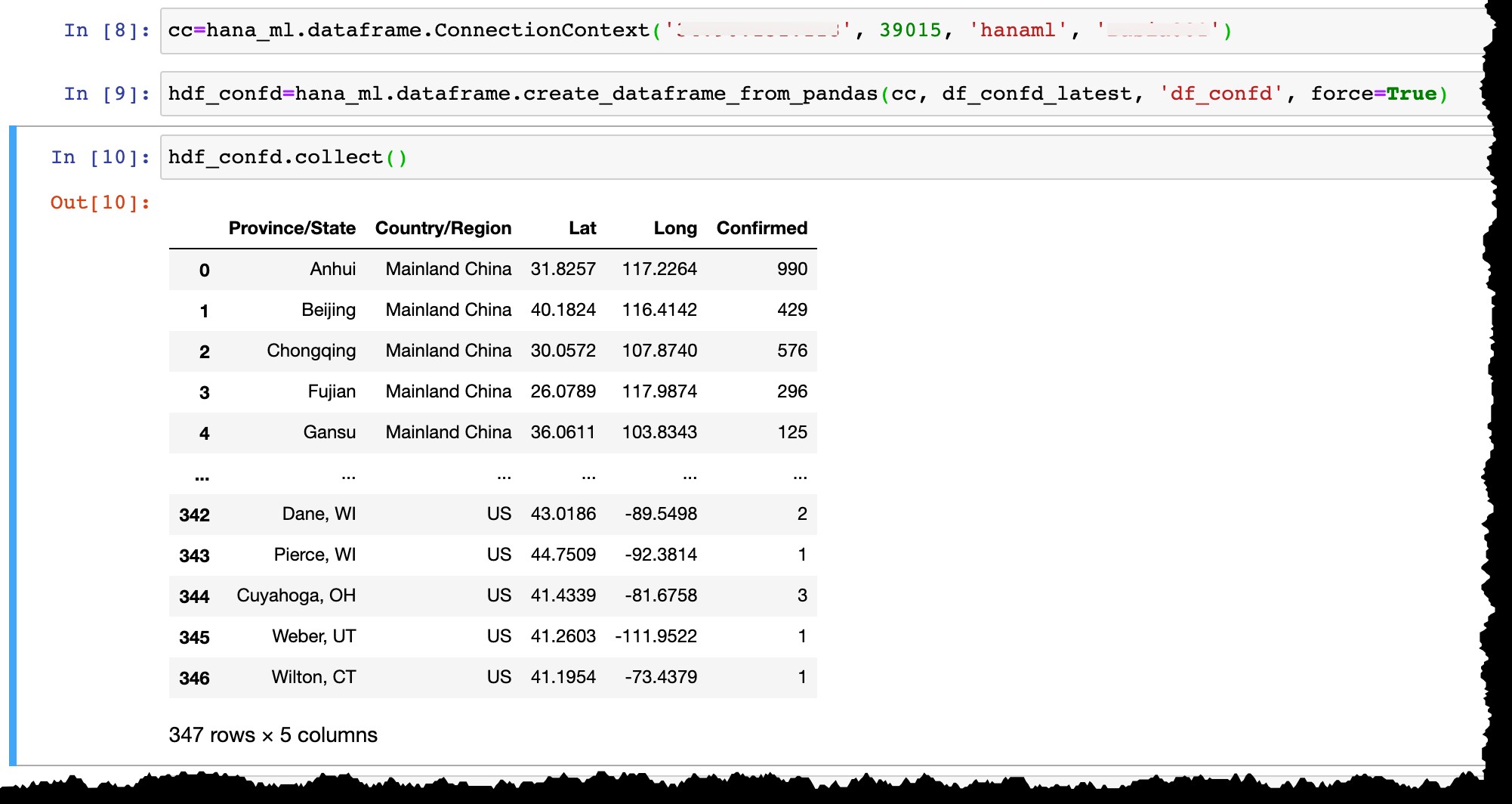
hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
След като рамката с данни HANA е създадена:
- Физическа таблица с колони се създава в HANA и там се вмъкват данни от рамката с данни на Pandas,
- HANA рамка с данни
hdf_confdв Python не съхранява никакви данни във вашия лаптоп, а само сочи към таблицаHANAML.df_confdв паметта на сървъра на SAP HANA и всички операции на Python върху рамката с данни HANA се изпълняват физически в HANA db без преместване на данни между сървъра и клиента, - За да покажем резултата от всякакви операции, трябва да приложим
collect()метод за преобразуване на рамката с данни HANA в Pandas (и в резултат на това за пренасяне на данни от HANA db сървър на локалния клиент).
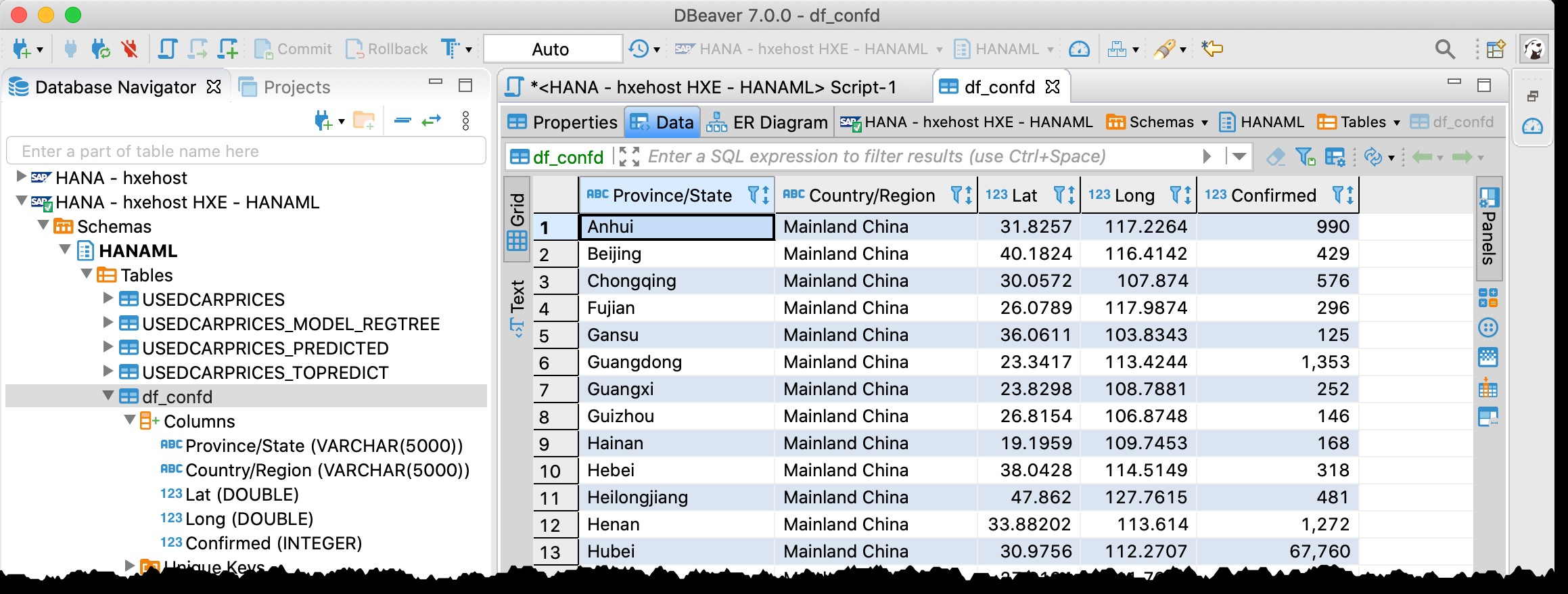
Използвайте DBeaver, за да проверите данните в SAP HANA…
Може би си спомняте, че вече използвах DBeaver — безплатният инструмент за база данни, поддържащ SAP HANA — в предишната ми публикация „GeoArt с SAP HANA и DBeaver“.
Сега го използвам отново и наистина мога да намеря таблицата df_confd в схемата HANAML с всички данни от изходната рамка с данни на Pandas.
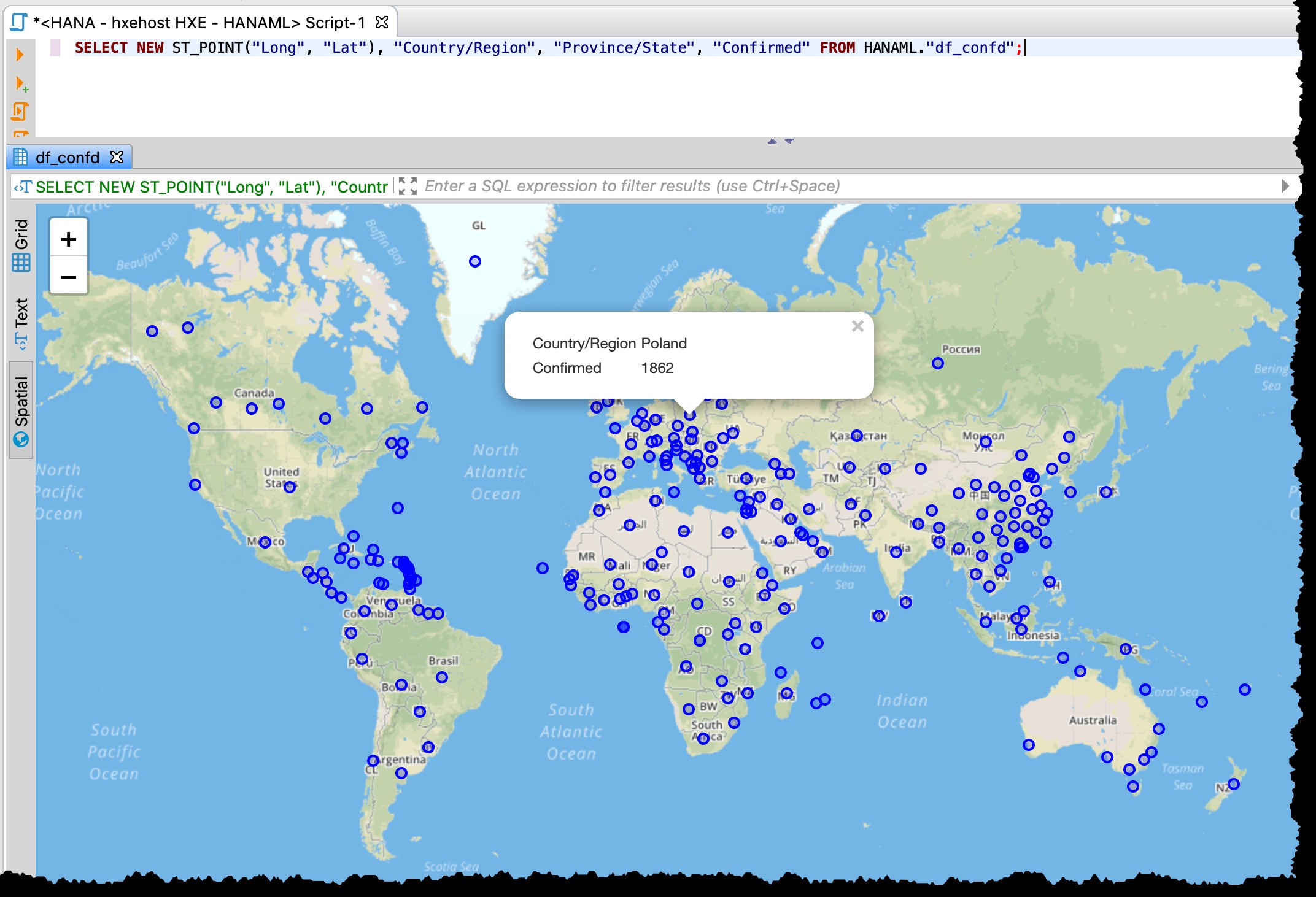
...и направете пространствена визуализация
Тъй като таблицата съдържа колони за географска ширина и дължина, мога да визуализирам засегнатите държави/щати направо от DBeaver със следния SQL, използвайки визуализация на пространствени данни.
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";
Трябваше да променя проекцията на картата на EPSG:4326 за да получите тези точки на картата. И DBeaver ми показва останалите данни за запис, когато щракна върху която и да е точка.
[По-долу е старата екранна снимка от 2020-03-11, която също така демонстрира различната детайлност на напр. Използвани по това време данни в САЩ]
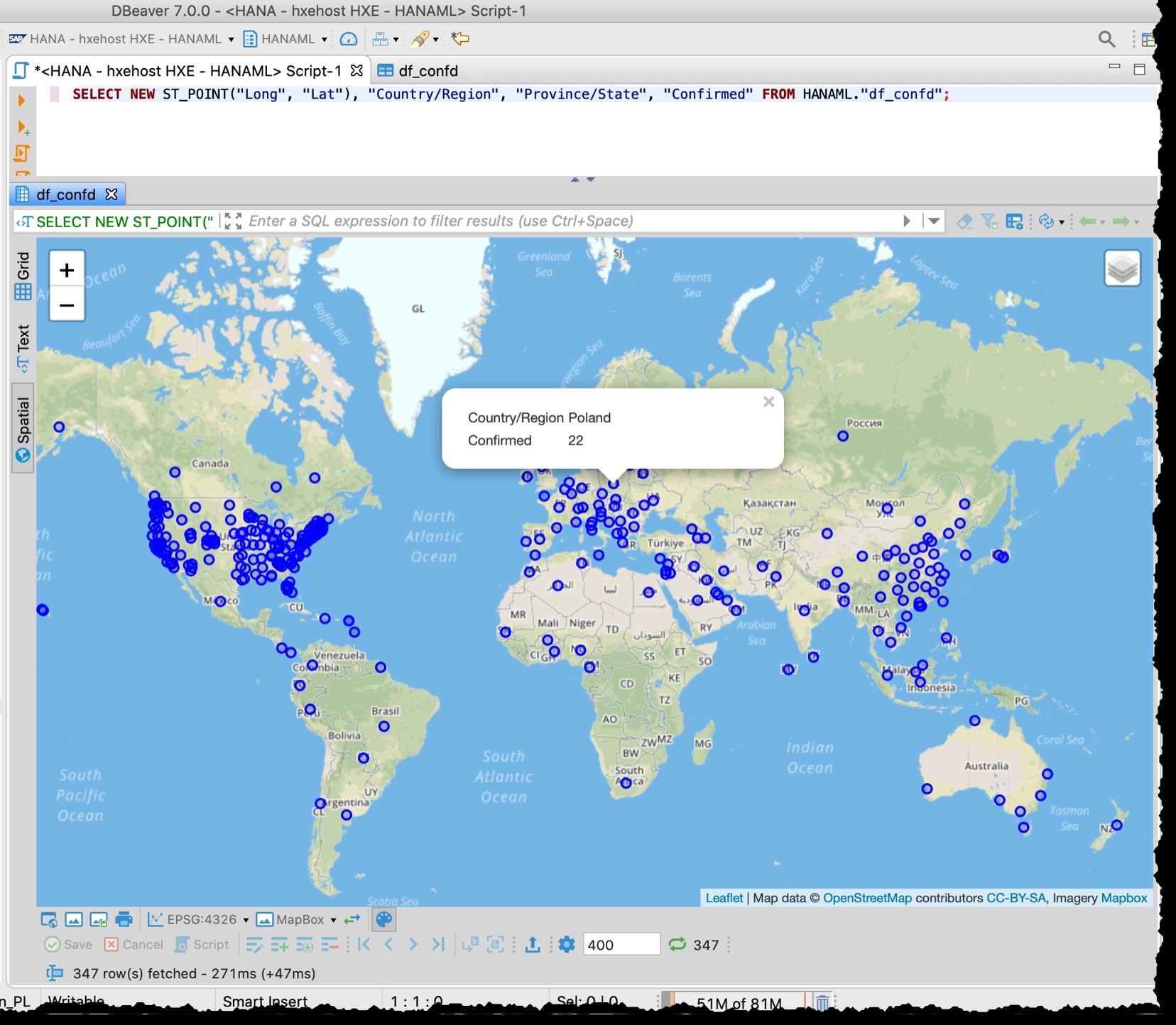
DBeaver пространствен преглед не е пълноценен инструмент за визуално геопространствено изследване. И все пак е достатъчно добър, за да видите засегнатите държави/региони (в зависимост от детайлността на изходните файлове).
Ако се интересувате да научите повече за hana_ml …
... тогава определено бих препоръчал да проверите Ръководство за практически:Машинно обучение надолу към SAP HANA с Python от Андреас Форстър.
HANA ML е част от новата тема „Разширени анализи със SAP HANA“ за събития на CodeJam. За съжаление поради ситуацията с коронавируса се наложи да отменим първия, организиран от Якоб Фламан в Берн този месец. Друг е организиран от Ewelina Pękała на 27 май в Катовице:https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417. Надяваме се, че дотогава ситуацията се нормализира и няма да е необходимо да отменяме и този.