T-SQL Tuesday #78 се хоства от Уенди Пастрик и предизвикателството този месец е просто да „научите нещо ново и да блогвате за това“. Нейната реклама е насочена към нови функции в SQL Server 2016, но тъй като съм писал в блог и съм представял за много от тях, реших да проуча нещо друго от първа ръка, за което винаги съм бил истински любопитен.
Виждал съм много хора да заявяват, че купчина може да бъде по-добра от клъстериран индекс за определени сценарии. Не мога да не се съглася с това. Една от интересните причини, които видях, е посочена обаче, че търсенето на RID е по-бързо от търсенето на ключ. Аз съм голям фен на клъстерираните индекси и не съм голям фен на купчини, така че почувствах, че това се нуждае от малко тестване.
И така, нека го тестваме!
Мислех, че би било добре да създам база данни с две таблици, еднакви, с изключение на това, че едната имаше клъстериран първичен ключ, а другата имаше неклъстериран първичен ключ. Щях да заредя някои редове в таблицата, да актуализирам куп редове в цикъл и да избера от индекс (принудително търсене на ключ или RID).
Системни спецификации
Този въпрос често възниква, така че за да изясня важните подробности за тази система, аз съм на 8-ядрена VM с 32 GB RAM, подкрепена от PCIe съхранение. Версията на SQL Server е 2014 SP1 CU6, без специални промени в конфигурацията или работещи флагове за проследяване:
Microsoft SQL Server 2014 (SP1-CU6) (KB3144524) – 12.0.4449.0 (X64)13 април 2016 г. 12:41:07
Авторски права (c) Microsoft Corporation
Издание за разработчици (64- бит) на Windows NT 6.3
База данни
Създадох база данни с много свободно място както в данните, така и в регистрационния файл, за да предотвратя намесата на всякакви събития за автоматично нарастване на тестовете. Също така настроих базата данни на просто възстановяване, за да минимизирам въздействието върху регистъра на транзакциите.
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
Таблиците
Както казах, две таблици, като единствената разлика е дали първичният ключ е групиран.
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
Таблица за заснемане на време на изпълнение
Мога да наблюдавам процесора и всичко това, но всъщност любопитството почти винаги е около времето за изпълнение. Затова създадох таблица за регистриране, за да заснема времето на изпълнение на всеки тест:
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
Тестът за вмъкване
И така, колко време отнема вмъкването на 2000 реда, 100 пъти? Взимам някои доста основни данни от sys.all_objects и изтегляне на дефиницията за всякакви процедури, функции и т.н.:
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Тестът за актуализиране
За теста за актуализиране просто исках да тествам скоростта на запис в клъстериран индекс спрямо купчина по много ред по ред. Така че изхвърлих 200 произволни реда в таблица #temp, след което изградих курсор около нея (таблицата #temp просто гарантира, че същите 200 реда се актуализират и в двете версии на таблицата, което вероятно е излишно).
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Изборният тест
И така, по-горе видяхте, че създадох индекс с Name като ключова колона във всяка таблица; за да оценя разходите за извършване на справки за значително количество редове, написах заявка, която присвоява изхода на променлива (елиминира мрежовия I/O и времето за изобразяване на клиента), но принуждава използването на индекса:
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; За това исках да покажа някои интересни аспекти на плановете, преди да съпоставя резултатите от теста. Провеждането им поотделно лице до лице осигурява следните сравнителни показатели:

Продължителността е незначителна за едно изявление, но вижте тези показания. Ако използвате бавно съхранение, това е голяма разлика, която няма да видите в по-малък мащаб и/или на вашия локален SSD за разработка.
И след това плановете, показващи двете различни справки, използвайки SQL Sentry Plan Explorer:

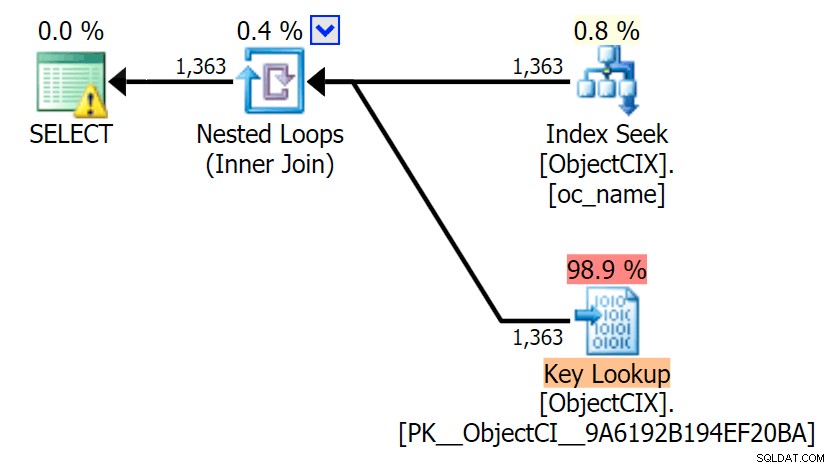
Плановете изглеждат почти идентични и може да не забележите разликата в четенията в SSMS, освен ако не сте улавяли статистически I/O. Дори приблизителните разходи за I/O за двете търсения бяха сходни – 1,69 за Key Lookup и 1,59 за RID търсене. (Иконата за предупреждение и в двата плана е за липсващ покривен индекс.)
Интересно е да се отбележи, че ако не принудим търсене и позволим на SQL Server да реши какво да прави, той избира стандартно сканиране и в двата случая – без предупреждение за липсващ индекс и вижте колко по-близо са четенията:

Оптимизаторът знае, че сканирането ще бъде много по-евтино от търсенето + търсене в този случай. Избрах LOB колона за присвояване на променлива само за ефект, но резултатите бяха подобни и при използване на колона, която не е LOB.
Резултатите от теста
С таблицата за времената на място успях лесно да стартирам тестовете няколко пъти (извърших дузина теста) и след това да дойда със средни стойности за тестовете със следната заявка:
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
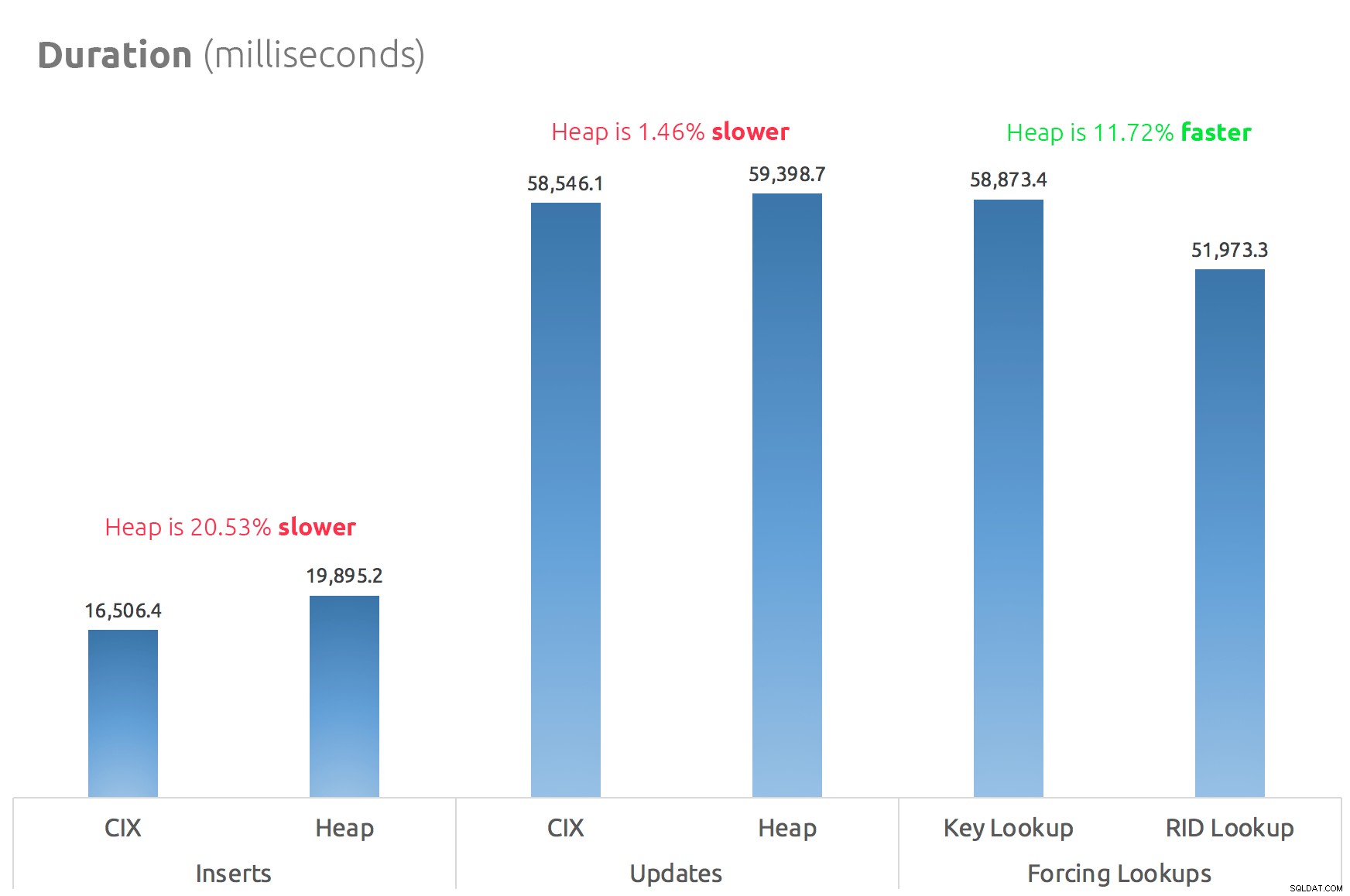
Проста лента диаграма показва как се сравняват:
Заключение
И така, слуховете са верни:поне в този случай търсенето на RID е значително по-бързо от търсенето на ключ. Преминаването директно към file:page:slot очевидно е по-ефективно по отношение на I/O, отколкото следването на b-дървото (и ако не сте на модерно хранилище, делтата може да бъде много по-забележима).
Дали искате да се възползвате от това и да вземете със себе си всички други аспекти на хепа, ще зависи от вашето работно натоварване – хийпът е малко по-скъп за операции по запис. Но това не окончателен – това може да варира значително в зависимост от структурата на таблицата, индексите и моделите на достъп.
Тествах много прости неща тук и ако сте на ограда за това, силно препоръчвам да тествате действителното си работно натоварване на собствения си хардуер и да сравните за себе си (и не забравяйте да тествате същото натоварване, където присъстват покриващи индекси; вероятно ще получите много по-добра цялостна производителност, ако можете просто да премахнете търсенията напълно). Не забравяйте да измерите всички показатели, които са важни за вас; само защото се фокусирам върху продължителността, не означава, че това е този, за който трябва да се грижите най-много. :-)