Едно от многото подобрения на планове за изпълнение в SQL Server 2012 беше добавянето на информация за резервиране на нишки и използване за планове за паралелно изпълнение. Тази публикация разглежда точно какво означават тези числа и предоставя допълнителна информация за разбирането на паралелното изпълнение.
Помислете за следната заявка, която се изпълнява срещу увеличена версия на базата данни AdventureWorks:
SELECT
BP.ProductID,
cnt = COUNT_BIG(*)
FROM dbo.bigProduct AS BP
JOIN dbo.bigTransactionHistory AS BTH
ON BTH.ProductID = BP.ProductID
GROUP BY BP.ProductID
ORDER BY BP.ProductID; Оптимизаторът на заявки избира паралелен план за изпълнение:
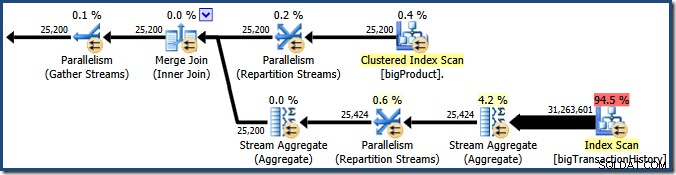
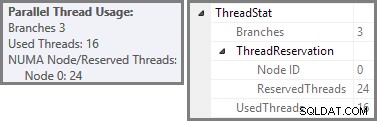
Plan Explorer показва подробности за използването на паралелни нишки в подсказката за основния възел. За да видите същата информация в SSMS, щракнете върху основния възел на плана, отворете прозореца Properties и разгънете ThreadStat възел. При използване на машина с осем логически процесора, налични за използване на SQL Server, информацията за използването на нишката от типично изпълнение на тази заявка е показана по-долу, Plan Explorer вляво, SSMS изглед вдясно:
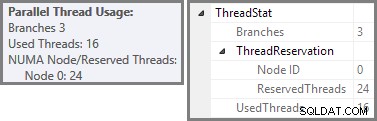
Екранната снимка показва, че машината за изпълнение е запазила 24 нишки за тази заявка и е приключила с използване на 16 от тях. Той също така показва, че планът на заявката има три клона , въпреки че не казва точно какво е клон. Ако сте прочели моята статия за Simple Talk за изпълнение на паралелни заявки, ще знаете, че клоновете са секции от план за паралелни заявки, ограничени от оператори за обмен. Диаграмата по-долу очертава границите и номерира клоните (щракнете, за да увеличите):

Втори клон (оранжев)
Нека първо разгледаме втория клон малко по-подробно:
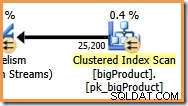
При степен на паралелизъм (DOP) от осем, има осем нишки, изпълняващи този клон на плана на заявката. Важно е да разберете, че това е целият план за изпълнение що се отнася до тези осем нишки – те нямат познания за по-широкия план.
В сериен план за изпълнение една нишка чете данни от източник на данни, обработва редовете чрез множество оператори на плана и връща резултати до местоназначението (което може да бъде прозорец с резултати от SSMS заявка или таблица на база данни, например).
В клон на план за паралелно изпълнение ситуацията е много подобна:всяка нишка чете данни от източник, обработва редовете чрез множество оператори на плана и връща резултати до местоназначението. Разликите са, че дестинацията е оператор за обмен (паралелизъм), а източникът на данни също може да бъде обмен.
В оранжевия клон източникът на данни е Clustered Index Scan, а местоназначението е от дясната страна на обмен на потоци за преразпределение. Дясната страна на борсата е известна като страна на производител , защото се свързва с клон, който добавя данни към обмена.
Осемте нишки в оранжевия клон си сътрудничат, за да сканират таблицата и да добавят редове към обмена. Обменът събира редове в пакети с размер на страница. След като пакетът е пълен, той се избутва през борсата към другата страна. Ако обменът има наличен друг празен пакет за попълване, процесът продължава, докато не бъдат обработени всички редове на източника на данни (или обменът свърши без празни пакети).
Можем да видим броя на редовете, обработени във всяка нишка, използвайки изгледа на Plan Tree в Plan Explorer:
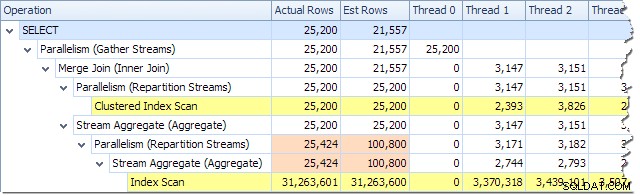
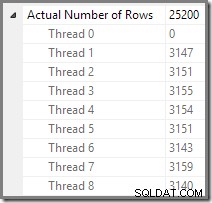
Plan Explorer улеснява да видите как редовете са разпределени между нишки за всички физическите операции в плана. В SSMS сте ограничени до виждане на разпределението на редове за един оператор на план. За да направите това, щракнете върху икона на оператор, отворете прозореца Свойства и след това разгънете възела Действителен брой редове. Графиката по-долу показва SSMS информация за възела Repartition Streams на границата между оранжевия и лилавия клон:
Клон три (зелен)
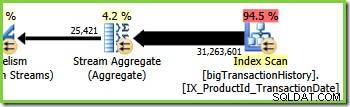
Клон три е подобен на клон две, но съдържа допълнителен оператор Stream Aggregate. Зеленият клон също има осем нишки, което прави общо шестнадесет видяни досега. Осемте зелени клонови нишки четат данни от сканиране на неклъстериран индекс, извършват някакъв вид агрегиране и предават резултатите на страната на производителя на друг обмен на потоци за преразпределение.
Подсказката на Plan Explorer за Stream Aggregate показва, че се групира по идентификатор на продукт и изчислява израз с етикет partialagg1005 :
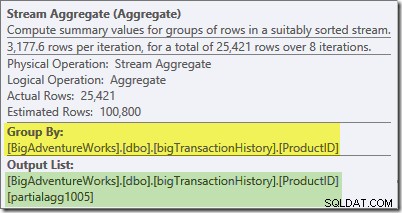
Разделът Изрази показва, че изразът е резултат от преброяването на редовете във всяка група:

Stream Aggregate изчислява частично (известен още като „локален“) агрегат. Частичният (или локален) квалификатор просто означава, че всяка нишка изчислява агрегата на редовете, които вижда. Редовете от индексното сканиране се разпределят между нишки с помощта на схема, базирана на търсенето:няма фиксирано разпределение на редовете преди време; нишките получават диапазон от редове от сканирането, когато ги поискат. Кои редове завършват с кои нишки са по същество произволни, защото зависи от проблемите с времето и други фактори.
Всяка нишка вижда различни редове от сканирането, но редове с същи идентификатор на продукт може да се види от повече от една нишка. Агрегатът е „частичен“, тъй като междинните суми за определена продуктова идентификационна група могат да се появят в повече от една нишка; той е "локален", защото всяка нишка изчислява резултата си въз основа само на редовете, които получава. Например, да речем, че в таблицата има 1000 реда за продукт №1. Една нишка може да види 432 от тези редове, докато друга може да види 568. И двете нишки ще имат частично Брой редове за идентификатор на продукт №1 (432 в едната нишка, 568 в другата).
Частичното агрегиране е оптимизация на производителността, тъй като намалява броя на редовете по-рано, отколкото иначе би било възможно. В зеления клон ранното агрегиране води до по-малко редове, които се събират в пакети и се прехвърлят през обмена на Repartition Stream.
Клон 1 (лилав)

Лилавият клон има още осем нишки, което прави двадесет и четири досега. Всяка нишка в този клон чете редове от двата обмена на потоци за преразпределение и записва редове в обмен на събиране на потоци. Този клон може да изглежда сложен и непознат, но той просто чете редове от източник на данни и изпраща резултати до местоназначение, както всеки друг план за заявка.
Дясната страна на плана показва данни, които се четат от другата страна на двата обмена на потоци за преразпределение, които се виждат в оранжевия и зеления клон. Тази (лява) страна на борсата е известна като потребител страна, тъй като прикачените тук нишки четат (консумират) редове. Осемте пурпурни нишки са потребители от данни при двата обмена на потока за преразпределение.
Лявата страна на лилавия клон показва редове, които се записват на производителя страна на обмен на Gather Streams. Същите осем нишки (които са потребители на борсите Repartition Streams) изпълняват производител роля тук.
Всяка нишка в лилавия клон изпълнява всеки оператор в клона, точно както една нишка изпълнява всяка операция в сериен план за изпълнение. Основната разлика е, че има осем нишки, работещи едновременно, като всяка работи на различен ред във всеки даден момент от време, използвайки различни екземпляри на операторите на плана на заявката.
Агрегатът на потока в този клон е глобален агрегат. Той комбинира частичните (локални) агрегати, изчислени в зеления клон (запомнете примера с 432 броя в едната нишка и 568 в другата), за да произведе комбинирана сума за всеки идентификатор на продукт. Подсказката на Plan Explorer показва глобалния резултатен израз, означен като Expr1004:
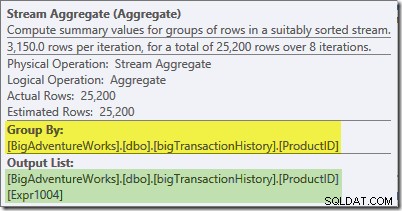
Правилният глобален резултат за идентификатор на продукт се изчислява чрез сумиране на частичните агрегати, както илюстрира разделът Expressions:
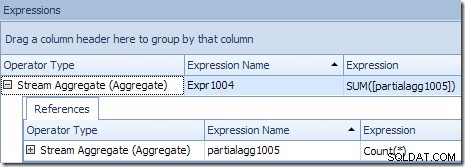
За да продължим нашия (въображаем) пример, правилният резултат от 1000 реда за продукт с идентификатор №1 се получава чрез сумиране на двете междинни суми от 432 и 568.
Всяка от осемте пурпурни клонови нишки чете данни от страната на потребителите на двата борса за събиране на потоци, изчислява глобалните агрегати, извършва Merge Join върху продуктов ID и добавя редове към обмена Gather Streams в най-лявата част на лилавия клон. Основният процес не се различава много от обикновения сериен план; разликите са в това откъде се четат редовете, къде се изпращат и как се разпределят редовете между нишките...
Разпределяне на редове за обмен
Предупредителният читател ще се чуди за няколко подробности в този момент. Как лилавият клон успява да изчисли правилните резултати по идентификатор на продукт но зеленият клон не може (резултатите за същия идентификационен номер на продукта бяха разпределени в много теми)? Освен това, ако има осем отделни обединявания за сливане (по едно на нишка), как SQL Server гарантира, че редовете, които ще се съединят, се озовават в същия екземпляр на присъединяването?
И на двата въпроса може да се отговори, като се погледне начина, по който двата потока за преразпределение обменят редове за маршрути от страната на производителя (в зеления и оранжевия клон) към страната на потребителя (в лилавия клон). Първо ще разгледаме обмена на Repartition Streams, граничещ с оранжевите и лилавите клони:
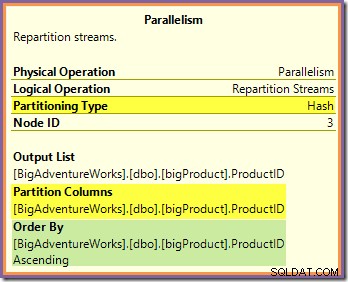
Този обмен насочва входящите редове (от оранжевия клон) с помощта на хеш функция, приложена към колоната с идентификатор на продукта. Ефектът е, че всички редове за определен идентификатор на продукт са гарантирани да се насочи към същата нишка с лилаво разклонение. Оранжевите и лилавите нишки не знаят нищо за това насочване; всичко това се обработва вътрешно от борсата.
Всичко, което оранжевите нишки знаят е, че връщат редове към родителския итератор, който ги е поискал (продуцентската страна на обмена). По същия начин всички пурпурни нишки „знаят“ е, че четат редове от източник на данни. Обменът определя в кой пакет ще влезе входящият ред с оранжева нишка и може да бъде всеки един от осемте кандидат пакета. По подобен начин обменът определя от кой пакет да прочете ред, за да удовлетвори заявка за четене от лилава нишка.
Внимавайте да не придобиете мисловен образ на конкретна оранжева (производителна) нишка, която е свързана директно с определена лилава (потребителска) нишка. Този план за заявка не работи по този начин. Производител на портокал може в крайна сметка изпращат редове до всички лилави потребители – маршрутизирането зависи изцяло от стойността на колоната с идентификатор на продукта във всеки ред, който обработва.
Също така имайте предвид, че пакет от редове на борсата се прехвърля само когато е пълен (или когато данните от страна на производителя свършат). Представете си, че обменът запълва пакети ред по ред, където редовете за конкретен пакет могат да идват от която и да е от (оранжевата) нишка от страна на производителя. След като пакетът е пълен, той се предава на страната на потребителя, където конкретен потребител (лилава) нишка може да започне да чете от него.
Обменът на Repartition Streams, граничещ със зелените и лилавите клони, работи по много подобен начин:
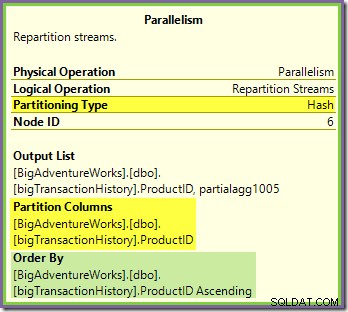
Редовете се насочват към пакети в този обмен с помощта на същата хеш функция на същата колона за разделяне що се отнася до оранжево-лилавия обмен, видян по-рано. Това означава, че и двете Repartition Streams обменя редове с маршрут със същия продуктов идентификатор към една и съща нишка с лилаво клон.
Това обяснява как Stream Aggregate в лилавия клон е в състояние да изчисли глобални агрегати – ако един ред с определен идентификационен номер на продукт се види в конкретна нишка с лилаво клон, тази нишка гарантирано ще види всички редове за този идентификационен номер на продукта (и не друга нишка ще).
Общата колона за разделяне на обмен също е ключът за присъединяване за обединяването за сливане, така че всички редове, които евентуално могат да се съединят, гарантирано ще бъдат обработени от една и съща (лилава) нишка.
Последно нещо, което трябва да се отбележи, е, че и двата борса запазват реда (известен още като „сливане“) обмени, както е показано в атрибута Order By в подсказките. Това отговаря на изискването за обединяване при сливане, че входните редове да бъдат сортирани на клавишите за свързване. Имайте предвид, че борсите никога не сортират редовете сами, те могат просто да бъдат конфигурирани да запазят съществуваща поръчка.
Нулева нишка
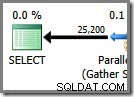
Последната част от плана за изпълнение се намира вляво от обмена на Gather Streams. Той винаги работи на една нишка - същата, използвана за изпълнение на целия редовен сериен план. Тази нишка винаги е обозначена като „Нишка 0“ в плановете за изпълнение и понякога се нарича нишка „координатор“ (означение, което не намирам за особено полезно).
Нишка нула чете редове от потребителската (лявата) страна на обмена за събиране на потоци и ги връща на клиента. В този пример няма итератори с нулева нишка освен обмена, но ако имаше, всички те биха работили в една и съща нишка. Обърнете внимание, че събирането на потоци също е обмен на сливане (има атрибут Order By):

По-сложните паралелни планове могат да включват зони за серийно изпълнение, различни от тази вляво от крайния обмен на потоци на събиране. Тези серийни зони не се изпълняват в нулева нишка, но това е детайл, който трябва да разгледате друг път.
Запазени и използвани нишки са преразгледани отново
Видяхме, че този паралелен план съдържа три клона. Това обяснява защо SQL Server резервиран 24 нишки (три клона при DOP 8). Въпросът е защо само 16 нишки са отчетени като „използвани“ на екранната снимка по-горе.
Отговорът има две части. Първата част не се отнася за този план, но все пак е важно да знаете за него. Броят на отчетените клонове е максималният брой, който може да се изпълнява едновременно .
Както може би знаете, някои планови оператори са „блокиращи“ – което означава, че трябва да консумират всичките си входни редове, преди да могат да произведат първия изходен ред. Най-ясният пример за блокиращ (известен също като спиране и тръгване) оператор е Sort. Сортирането не може да върне първия ред в сортирана последователност, преди да е видяло всеки входен ред, защото последният входен ред може да се сортира първи.
Операторите с множество входове (обединения и обединения, например) могат да бъдат блокиращи по отношение на един вход, но неблокиращи („конвейерни“) по отношение на другия. Пример за това е хеш присъединяването – входът за изграждане е блокиран, но входът на сондата е конвейер. Входът за изграждане е блокиран, защото създава хеш таблицата, спрямо която се тестват редовете на сондата.
Наличието на блокиращи оператори означава, че един или повече паралелни клонове могат гарантирано завършване преди другите да могат да започнат. Когато това се случи, SQL Server може да използва повторно нишките, използвани за обработка на завършен клон за по-късен клон в последователността. SQL Server е много консервативен по отношение на резервирането на нишки, така че само клонове, които са гарантирани за да завършите, преди да започне друго, използвайте тази оптимизация за резервиране на нишки. Нашият план за заявка не съдържа блокиращи оператори, така че отчетеният брой клонове е само общият брой клонове.
Втората част от отговора е, че нишките все още могат да бъдат използвани повторно, ако се случат за да завършите, преди да стартира нишка в друг клон. В този случай пълният брой нишки все още е запазен, но действителното използване може да е по-малко. Колко нишки действително използва паралелен план зависи от проблемите с времето, наред с други неща, и може да варира между изпълнението.
Всички паралелни нишки не започват да се изпълняват едновременно, но отново подробностите за това ще трябва да изчакат за друг повод. Нека отново да разгледаме плана на заявката, за да видим как нишките могат да бъдат използвани повторно, въпреки липсата на блокиращи оператори:
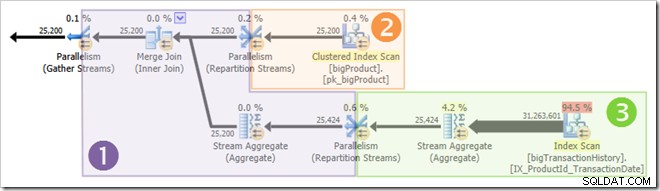
Ясно е, че нишките в клон един не могат да бъдат завършени преди стартиране на нишки в клонове два или три, така че няма шанс за повторна употреба на нишка там. Клон три също е малко вероятно за завършване преди стартирането на клон едно или второ, защото има толкова много работа (почти 32 милиона реда за агрегиране).
Втори клон е различен въпрос. Сравнително малкият размер на таблицата с продукти означава, че има приличен шанс клонът да завърши работата си преди клон три стартира. Ако четенето на таблицата на продуктите не доведе до никакъв физически I/O, няма да отнеме много време осем нишки да прочетат 25 200 реда и да ги предадат на обмена на потоци за преразпределение на оранжево-лилава граница.
Точно това се случи при тестовете, използвани за екранните снимки, виждани досега в тази публикация:осемте оранжеви нишки на клона завършиха достатъчно бързо, за да могат да бъдат използвани повторно за зеления клон. Използвани са общо шестнадесет уникални нишки, така че това отчита планът за изпълнение.
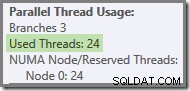
Ако заявката се изпълни отново със студен кеш, забавянето, въведено от физическия I/O, е достатъчно, за да се гарантира, че зелените нишки на клон се стартират, преди да са завършили нишките с оранжев клон. Никакви нишки не се използват повторно, така че планът за изпълнение съобщава, че всичките 24 запазени нишки всъщност са били използвани:
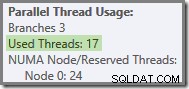
По-общо, възможен е произволен брой „използвани нишки“ между двете крайности (16 и 24 за този план за заявка):
И накрая, имайте предвид, че нишката, която изпълнява серийната част на плана вляво от крайните потоци за събиране, не се брои в общите суми на паралелната нишка. Това не е допълнителна нишка, добавена за приспособяване на паралелно изпълнение.
Последни мисли
Красотата на модела на обмен, използван от SQL Server за прилагане на паралелно изпълнение, е, че цялата сложност на буферирането и преместването на редове между нишките е скрита в операторите за обмен (паралелизъм). Останалата част от плана е разделена на спретнати „клонове“, ограничени от обмени. В рамките на клон всеки оператор се държи по същия начин, както в сериен план – в почти всички случаи операторите на клон не знаят, че по-широкият план изобщо използва паралелно изпълнение.
Ключът към разбирането на паралелното изпълнение е (умствено) да се раздели паралелният план на границите на обмена и да се представи всеки клон като DOP отделен сериен планове, като всички изпълняват паралелност на отделно подмножество от редове. Не забравяйте по-специално, че всеки такъв сериен план изпълнява всички оператори в този клон – SQL Server не стартирайте всеки оператор в отделна нишка!
Разбирането на най-подробното поведение изисква малко мисъл, особено по отношение на това как се пренасочват редовете в рамките на обмен и как механизмът гарантира правилни резултати, но тогава повечето неща, които си струва да се знаят, изискват малко мисъл, нали?