Твърде често виждам хора да се оплакват как техният дневник на транзакциите е превзел техния твърд диск. Много пъти се оказва, че са извършвали голяма операция за изтриване, като изчистване или архивиране на данни, в една голяма транзакция.
Исках да изпълня някои тестове, за да покажа въздействието, както върху продължителността, така и върху регистъра на транзакциите, от извършването на една и съща операция с данни на парчета спрямо една транзакция. Създадох база данни и я попълних с голяма таблица SalesOrderDetailEnlarged ,
След като попълних таблицата, направих резервно копие на базата данни, архивирах дневника и изпълних DBCC SHRINKFILE (не ме стреляйте), за да може въздействието върху регистрационния файл да се установи от изходна линия (знаейки много добре, че тези операции *ще* причинят нарастване на регистрационния файл на транзакциите).
Нарочно използвах механичен диск, а не SSD. Въпреки че може да започнем да виждаме по-популярна тенденция за преминаване към SSD, това все още не се е случило в достатъчно голям мащаб; в много случаи все още е твърде скъпо да се направи това в големи устройства за съхранение.
Тестовете
Така че след това трябваше да определя какво искам да тествам за най-голямо въздействие. Тъй като вчера участвах в дискусия с колега относно изтриването на данни на парчета, избрах изтриване. И тъй като клъстерираният индекс на тази таблица е на SalesOrderID , не исках да използвам това – това би било твърде лесно (и много рядко би съвпадало с начина, по който се обработват изтриванията в реалния живот). Затова реших вместо това да проследя серия от ProductID стойности, което би гарантирало, че ще ударя голям брой страници и ще изисквам много записване. Определих кои продукти да изтрия чрез следната заявка:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Това доведе до следните резултати:
ProductID ProductCount --------- ------------ 870 187520 712 135280 873 134160
Това ще изтрие 456 960 реда (около 10% от таблицата), разпределени в много поръчки. Това не е реалистична модификация в този контекст, тъй като ще се обърка с предварително изчислените общи суми на поръчката и не можете наистина да премахнете продукт от поръчка, която вече е изпратена. Но използването на база данни, която всички познаваме и обичаме, е аналогично на, да речем, изтриване на потребител от форумен сайт, както и изтриване на всичките му съобщения – реален сценарий, който съм виждал в дивата природа.
Така че един тест би бил да извършите следното еднократно изтриване:
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
Знам, че това ще изисква масивно сканиране и ще доведе до огромна такса върху дневника на транзакциите. Това е някак въпросът. :-)
Докато това се изпълняваше, съставих различен скрипт, който ще извърши това изтриване на парчета:25 000, 50 000, 75 000 и 100 000 реда наведнъж. Всяка част ще бъде ангажирана в своя собствена транзакция (така че ако трябва да спрете скрипта, можете и всички предишни парчета вече ще бъдат ангажирани, вместо да трябва да започват отначало) и в зависимост от модела за възстановяване, ще бъдат следвани чрез CHECKPOINT или BACKUP LOG за да се сведе до минимум текущото въздействие върху регистъра на транзакциите. (Аз също ще тествам без тези операции.) Ще изглежда нещо подобно (няма да се занимавам с обработката на грешки и други тънкости за този тест, но не трябва да бъдете като кавалер):
SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END
Разбира се, след всеки тест бих възстановявал оригиналния архив на базата данни WITH REPLACE, RECOVERY , задайте съответно модела за възстановяване и стартирайте следващия тест.
Резултатите
Резултатът от първия тест изобщо не беше много изненадващ. За да извършите изтриването в едно изявление, отне 42 секунди в пълен обем и 43 секунди в просто. И в двата случая това увеличи дневника до 579 MB.
Следващият набор от тестове имаше няколко изненади за мен. Едната е, че докато тези методи за нарязване значително намаляват въздействието върху регистрационния файл, само няколко комбинации се доближиха по времетраене и нито една всъщност не беше по-бърза. Друго е, че като цяло разделянето на парчета при пълно възстановяване (без да се извършва архивиране на регистрационни файлове между стъпките) се представя по-добре от еквивалентните операции при просто възстановяване. Ето резултатите за продължителността и въздействието в регистъра:
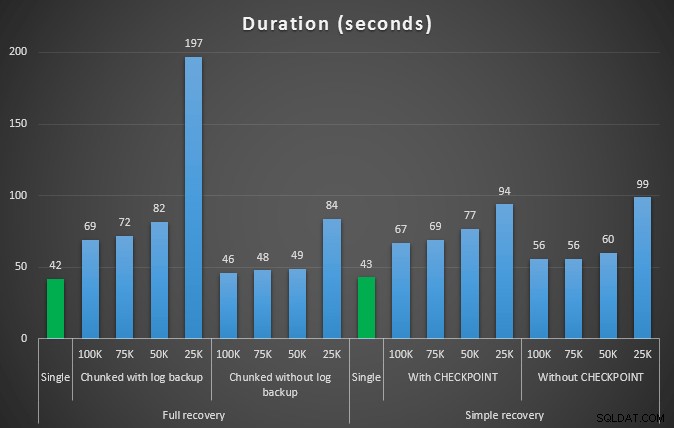
Продължителност в секунди на различни операции за изтриване, премахващи 457K реда
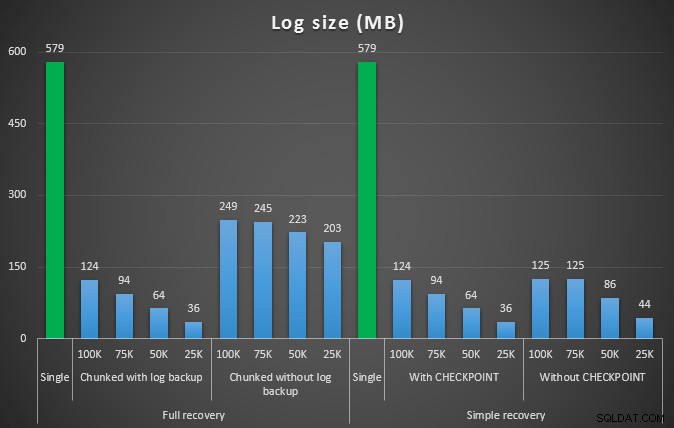
Размер на регистрационния файл, в MB, след различни операции за изтриване, премахващи 457K реда
Отново, като цяло, докато размерът на журнала е значително намален, продължителността се увеличава. Можете да използвате този тип скала, за да определите дали е по-важно да намалите въздействието върху дисковото пространство или да сведете до минимум прекараното време. За малък удар по продължителност (и в края на краищата повечето от тези процеси се изпълняват на заден план) можете да постигнете значителни спестявания (до 94%, в тези тестове) при използване на пространството в регистрационните файлове.
Имайте предвид, че не опитах нито един от тези тестове с активирана компресия (вероятно бъдещ тест!) и оставих настройките за автоматично нарастване на журнала на ужасните стойности по подразбиране (10%) – отчасти поради мързел и отчасти защото много среди там са запазили тази ужасна настройка.
Но какво ще стане, ако имам повече данни?
След това реших, че трябва да тествам това в малко по-голяма база данни. Така че направих друга база данни и създадох ново, по-голямо копие на dbo.SalesOrderDetailEnlarged . Приблизително десет пъти по-голям, всъщност. Този път вместо първичен ключ на SalesOrderID, SalesorderDetailID , току-що го направих клъстериран индекс (за да позволим дубликати) и го попълних по следния начин:
SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID); Поради ограничения на дисковото пространство, трябваше да се отдалеча от VM на моя лаптоп за този тест (и избрах 40-ядрена кутия, със 128 GB RAM, която просто седеше около квази неактивен :-)) и все още това не беше бърз процес по никакъв начин. Попълването на таблицата и създаването на индексите отне ~24 минути.
Таблицата има 48,5 милиона реда и заема 7,9 GB диск (4,9 GB данни и 2,9 GB индекс).
Този път моята заявка за определяне на добър набор от кандидат ProductID стойности за изтриване:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailReallyReallyEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Получиха следните резултати:
ProductID ProductCount --------- ------------ 870 1828320 712 1318980 873 1308060
Така че ще изтрием 4 455 360 реда, малко под 10% от таблицата. Следвайки подобен модел на горния тест, ще изтрием всичко наведнъж, след това на парчета от 500 000, 250 000 и 100 000 реда.
Резултати:
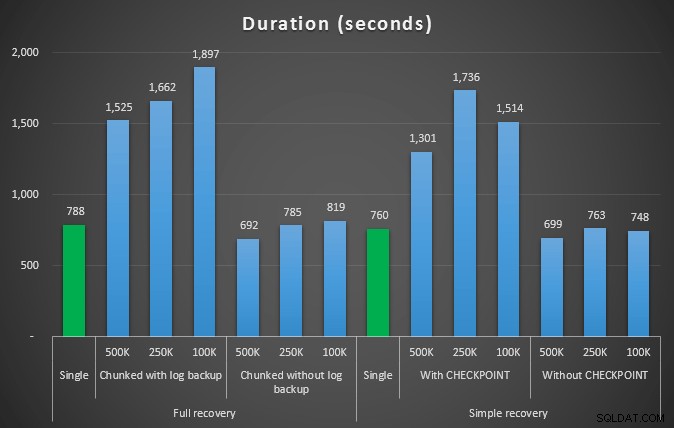 Продължителност в секунди на различни операции за изтриване, премахващи 4,5 мм редове
Продължителност в секунди на различни операции за изтриване, премахващи 4,5 мм редове
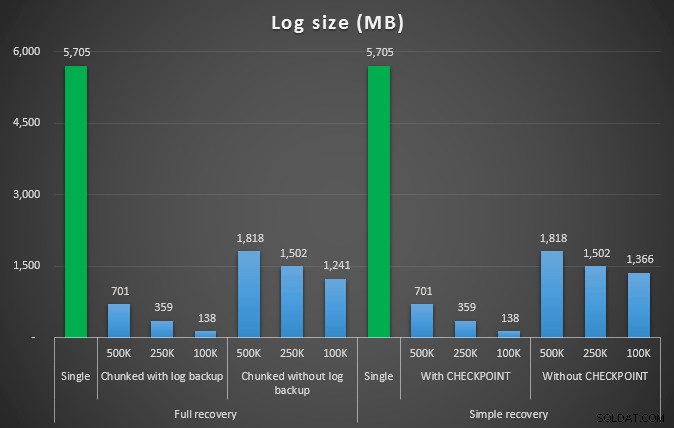 Размер на регистрационния файл, в MB, след различни операции за изтриване, премахващи 4,5 мм редове
Размер на регистрационния файл, в MB, след различни операции за изтриване, премахващи 4,5 мм редове
Така че отново виждаме значително намаляване на размера на регистрационния файл (над 97% в случаите с най-малкия размер на парчето от 100K); в този мащаб обаче виждаме няколко случая, в които също така извършваме изтриването за по-малко време, дори с всички събития за автоматично нарастване, които трябва да са се случили. Това ми звучи ужасно като печеливша!
Този път с по-голям дневник
Сега ми беше любопитно как тези различни изтривания ще се сравнят с регистрационен файл, предварително оразмерен, за да се приспособи за такива големи операции. Придържайки се към нашата по-голяма база данни, предварително разширих регистрационния файл до 6 GB, направих му резервно копие, след което стартирах тестовете отново:
ALTER DATABASE delete_test MODIFY FILE (NAME=delete_test_log, SIZE=6000MB);
Резултати, сравняващи продължителността с фиксиран регистрационен файл със случая, когато файлът трябваше да нараства автоматично:
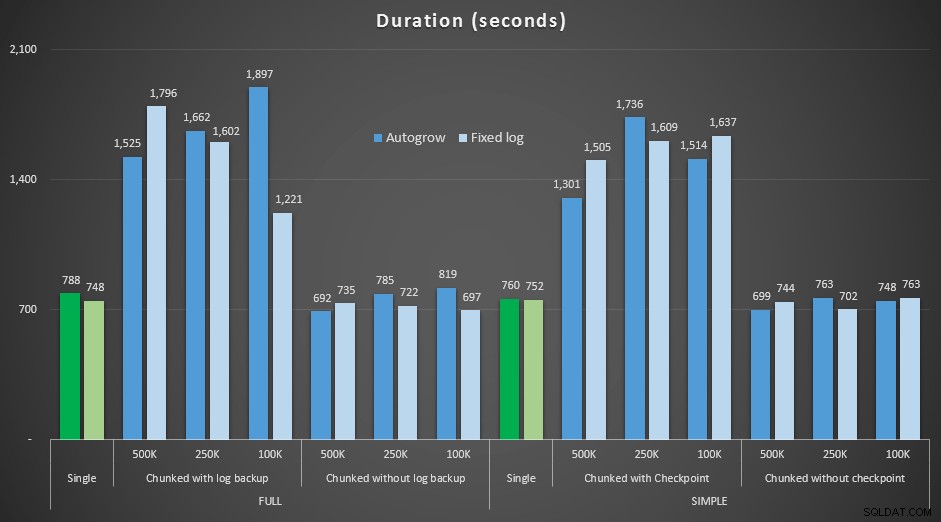
Продължителност в секунди на различни операции за изтриване, премахващи 4,5 мм редове , сравнявайки фиксирания размер на журнала и автоматичното нарастване
Отново виждаме, че методите, които изтриват парчета в пакети и *не* извършват архивиране на регистрационни файлове или контролна точка след всяка стъпка, съперничат на еквивалентната единична операция по отношение на продължителност. Всъщност вижте, че повечето действително се представят за по-малко общо време, с допълнителния бонус, че други транзакции ще могат да влизат и излизат между стъпките. Което е добре, освен ако не искате тази операция за изтриване да блокира всички несвързани транзакции.
Заключение
Ясно е, че няма единен, правилен отговор на този проблем – има много присъщи „зависи“ променливи. Може да отнеме известно експериментиране, за да намерите вашето магическо число, тъй като ще има баланс между режийните разходи, необходими за архивиране на дневника и колко работа и време спестявате при различни размери на парчета. Но ако планирате да изтриете или архивирате голям брой редове, много вероятно е, че като цяло ще ви е по-добре да извършвате промените на парчета, а не в една масивна транзакция – въпреки че числата за продължителност изглежда правят че по-малко привлекателна операция. Не всичко е свързано с продължителността – ако нямате достатъчно предварително разпределен регистрационен файл и нямате място, за да поберете такава масивна транзакция, вероятно е много по-добре да сведете до минимум нарастването на регистрационните файлове за сметка на продължителността, в този случай ще искате да игнорирате графиките за продължителност по-горе и да обърнете внимание на графиките за размера на регистрационния файл.
Ако можете да си позволите пространството, все пак може или не може да искате да оразмерите предварително своя регистър на транзакциите. В зависимост от сценария, понякога използването на настройките за автоматично нарастване по подразбиране се оказа малко по-бързо в моите тестове, отколкото използването на фиксиран регистрационен файл с много място. Освен това може да е трудно да отгатнете точно колко ще ви трябва, за да поберете голяма транзакция, която все още не сте изпълнили. Ако не можете да тествате реалистичен сценарий, опитайте се да си представите най-лошия сценарий – тогава за безопасност го удвоете. Кимбърли Трип (блог | @KimberlyLTripp) има страхотни съвети в тази публикация:8 стъпки за по-добра пропускателна способност на дневника на транзакциите – в този контекст, по-конкретно, погледнете точка №6. Независимо от начина, по който решите да изчислите вашите изисквания за пространство в регистрационните файлове, ако в крайна сметка ще имате нужда от пространството, по-добре да го вземете по контролиран начин предварително, отколкото да спрете бизнес процесите си, докато чакат автоматично нарастване ( няма значение няколко!).
Друг много важен аспект на това, който не измерих изрично, е въздействието върху едновременността – куп по-кратки транзакции на теория ще имат по-малко въздействие върху едновременните операции. Докато едно изтриване отнема малко по-малко време от по-дългите групови операции, то задържа всичките си ключалки за цялата тази продължителност, докато операциите на парчета ще позволят на други транзакции на опашка да се промъкнат между всяка транзакция. В една бъдеща публикация ще се опитам да разгледам по-отблизо това въздействие (и имам планове за друг по-задълбочен анализ).