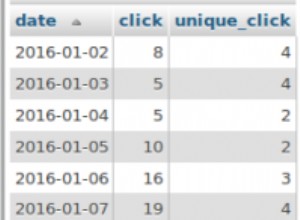
При сравняване на unicode текст тиретата се третират специално. Сравнението на Unicode използва "ред на речника", който игнорира тирета. Това не е случаят със сравнението на текст без Unicode.
Сравняване на -X и iX , е като сравняване на X и iX , така че -X , лявата страна, е по-голяма. Когато сравнявате "-" и "i", е като да сравнявате "" и "i", така че "i", дясната страна е по-голяма.
От MSDN,
SELCT body From MSDN_Articles WHERE url IN ("https://support.microsoft.com/kb/322112
“)