Вероятно вече сте намерили отговор на въпроса си. Този отговор е да помогне на други, които може да се натъкнат на този въпрос. Ето една възможна опция, която може да се използва за разрешаване на прехвърлянето на данни с помощта на SSIS. Предположих, че все още можете да създавате низове за връзка, сочещи към вашите сървъри A и B от пакета SSIS. Ако това предположение е грешно, моля, уведомете ме, за да мога да изтрия този отговор. В този пример използвам SQL Server 2008 R2 като back-end. Тъй като нямам два сървъра, създадох две еднакви таблици в различни Schemas Сървър A и ServerB .
Процес стъпка по стъпка:
-
В
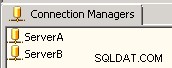
Connection managerраздел на SSIS, създайте две OLE DB връзки, а именно ServerA и ServerB . Този пример сочи към един и същ сървър, но във вашия сценарий връзките ще трябва да сочат към вашите два различни сървъра. Вижте екранна снимка #1 . -
Създайте две схеми
ServerAиServerB. Създайте таблицатаdbo.ItemInfoи в двете схеми. Скриптове за създаване на тези таблици са дадени под Скриптове раздел. Отново, тези обекти са само за този пример. -
Попълних и двете таблици с примерни данни. Таблица
ServerA.ItemInfoсъдържа2,222 rowsи таблицаServerB.ItemInfoсъдържа10,000 rows. Според въпроса липсващите 7778 редовете трябва да бъдат прехвърлени отServerBкъмServerA. Вижте екранна снимка #2 . -
В раздела за контролен поток на пакета SSIS поставете задача за поток от данни, както е показано на екранна снимка #3 .
-
Щракнете двукратно върху задачата за поток от данни, за да отидете до раздела за поток от данни и конфигурирайте задачата за поток от данни, както е описано по-долу. Сървър Б е
OLE DB Source; Намерете запис в сървър A еLookup transformation taskи Сървър А еOLE DB Destination. -
Конфигурирайте
OLE DB SourceСървър Б както е показано на екранни снимки #4 и #5 . -
Конфигурирайте
Lookup transformation taskНамерете запис в сървър A както е показано на екранни снимки #6 - #8 . В този пример ItemId е уникалният ключ. Следователно това е колоната, използвана за търсене на липсващи записи между двете таблици. Тъй като имаме нужда само от редовете, които не съществуват в Сървър А , трябва да изберем опциятаRedirect rows to no match output. -
Поставете
OLE DB Destinationвърху задачата за поток от данни. Когато свържете задачата за преобразуване на справка с OLE DB дестинация, ще бъдете подканени сInput Output Selectionдиалогов прозорец. ИзберетеLookup No Match Outputот диалоговия прозорец, както е показано на екранна снимка #9 . КонфигурирайтеOLE DB DestinationСървър A както е показано на екранни снимки #10 и #11 . -
След като задачата за поток от данни бъде конфигурирана, тя трябва да изглежда както е показано на екранна снимка #12 .
-
Примерно изпълнение на пакета е показано на екранна снимка #13 . Както можете да забележите, липсващите
7,778 rowsса прехвърлени отServer BкъмServer A. Вижте екранна снимка #14 за да видите броя на записите в таблицата след изпълнението на пакета. -
Тъй като изискването беше просто да се вмъкнат липсващите записи, беше използван този подход. Ако искате да актуализирате съществуващи записи и да изтриете записи, които вече не са валидни, моля, вижте примера, който предоставих в този връзка. SQL Integration Services за зареждане на файл с разделители? Примерът във връзката показва как да прехвърлите плосък файл в SQL, но той актуализира съществуващите записи и изтрива невалидните записи. Освен това примерът е фино настроен да обработва голям брой редове.
Надявам се, че това помага.
Скриптове
.
CREATE SCHEMA [ServerA] AUTHORIZATION [dbo]
GO
CREATE SCHEMA [ServerB] AUTHORIZATION [dbo]
GO
CREATE TABLE [ServerA].[ItemInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemId] [varchar](255) NOT NULL,
[ItemName] [varchar](255) NOT NULL,
[ItemType] [varchar](255) NOT NULL,
CONSTRAINT [PK_ItemInfo] PRIMARY KEY CLUSTERED ([Id] ASC),
CONSTRAINT [UK_ItemInfo_ItemId] UNIQUE NONCLUSTERED ([ItemId] ASC)
) ON [PRIMARY]
GO
CREATE TABLE [ServerB].[ItemInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemId] [varchar](255) NOT NULL,
[ItemName] [varchar](255) NOT NULL,
[ItemType] [varchar](255) NOT NULL,
CONSTRAINT [PK_ItemInfo] PRIMARY KEY CLUSTERED ([Id] ASC),
CONSTRAINT [UK_ItemInfo_ItemId] UNIQUE NONCLUSTERED ([ItemId] ASC)
) ON [PRIMARY]
GO
Екранна снимка №1:
Екранна снимка №2:

Екранна снимка #3:

Екранна снимка #4:

Екранна снимка №5:

Екранна снимка №6:

Екранна снимка №7:

Екранна снимка #8:

Екранна снимка #9:

Екранна снимка #10:

Екранна снимка #11:

Екранна снимка #12:
Екранна снимка #13:

Екранна снимка #14: