Разходите за поддърво трябва да се приемат с голяма доза сол (и особено когато имате огромни кардинални грешки). SET STATISTICS IO ON; SET STATISTICS TIME ON; продукцията е по-добър показател за действителната производителност.
Сортирането с нулев ред не отнема 87% от ресурсите. Този проблем във вашия план е един от статистическите оценки. Разходите, показани в действителния план, все още са прогнозни разходи. Не ги настройва, за да отчитат какво всъщност се е случило.
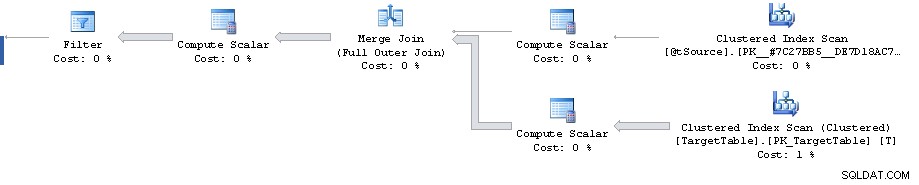
Има точка в плана, където филтър намалява 1 911 721 реда до 0, но приблизителните редове занапред са 1 860 310. След това всички разходи са фалшиви, като кулминацията е 87% оценка на разходите за сортиране на 3 348 560 реда.
Грешката при оценката на кардиналността може да бъде възпроизведена извън Merge изявление, като разгледате прогнозния план за Full Outer Join с еквивалентни предикати (дава същите оценки за 1 860 310 реда).
SELECT *
FROM TargetTable T
FULL OUTER JOIN @tSource S
ON S.Key1 = T.Key1 and S.Key2 = T.Key2
WHERE
CASE WHEN S.Key1 IS NOT NULL
/*Matched by Source*/
THEN CASE WHEN T.Key1 IS NOT NULL
/*Matched by Target*/
THEN CASE WHEN [T].[Data1]<>S.[Data1] OR
[T].[Data2]<>S.[Data2] OR
[T].[Data3]<>S.[Data3]
THEN (1)
END
/*Not Matched by Target*/
ELSE (4)
END
/*Not Matched by Source*/
ELSE CASE WHEN [T].[Key1]example@sqldat.com
THEN (3)
END
END IS NOT NULL
Въпреки това обаче планът до самия филтър изглежда доста под оптимален. Той прави пълно сканиране на клъстерен индекс, когато може би искате план с търсене на 2 диапазона на клъстерен индекс. Единият за извличане на единичния ред, съответстващ на първичния ключ от присъединяването към източника, а другият за извличане на T.Key1 = @id диапазон (въпреки че може би това е, за да се избегне необходимостта от сортиране в ред на клъстерирани ключове по-късно?)
Може би бихте могли да опитате това пренаписване и да видите дали работи по-добре или по-зле
;WITH FilteredTarget AS
(
SELECT T.*
FROM TargetTable AS T WITH (FORCESEEK)
JOIN @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
OR T.Key1 = @id
)
MERGE FilteredTarget AS T
USING @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
-- Only update if the Data columns do not match
WHEN MATCHED AND S.Key1 = T.Key1 AND S.Key2 = T.Key2 AND
(T.Data1 <> S.Data1 OR
T.Data2 <> S.Data2 OR
T.Data3 <> S.Data3) THEN
UPDATE SET T.Data1 = S.Data1,
T.Data2 = S.Data2,
T.Data3 = S.Data3
-- Note from original poster: This extra "safety clause" turned out not to
-- affect the behavior or the execution plan, so I removed it and it works
-- just as well without, but if you find yourself in a similar situation
-- you might want to give it a try.
-- WHEN MATCHED AND (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 = @id THEN
-- DELETE
-- Insert when missing in the target
WHEN NOT MATCHED BY TARGET THEN
INSERT (Key1, Key2, Data1, Data2, Data3)
VALUES (Key1, Key2, Data1, Data2, Data3)
WHEN NOT MATCHED BY SOURCE AND T.Key1 = @id THEN
DELETE;