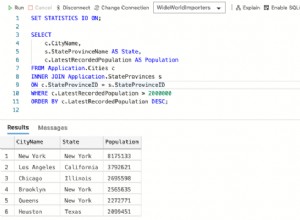
Това не е правилно.
Имам две възможности:
1) Статистиката в таблиците е остаряла. Възстановете индексите и актуализирайте статистиките.
2) Както казахте, записите на географската таблица са големи, обхващащи много страници (не че един запис обхваща няколко страници, тъй като не може, но записът е близо до марката 8K). В този случай, достатъчно смешно, създаването на друг неклъстъриран индекс върху клъстерирания индекс може да помогне.
АКТУАЛИЗАЦИЯ
Доволен съм, че проработи. Сега малко обяснение.
На първо място, ако нещо наистина не е наред и планът за изпълнение изглежда странно, винаги разглежда статистиките и възстановява индексите.
Създаването на неклъстъриран индекс за клъстерирания индекс обикновено не би трябвало да предоставя никаква полза, но когато таблицата има много записи и записът е близо до лимита си от 8K, това е полезно. Както знаете, когато SQL отиде на диска, за да зареди запис, той зарежда 8K страница. По подобен начин отивайки към индекси, той ще зареди 8K страница. Сега, когато индексът е 4-байтово цяло число, това означава зареждане на ID за 2000 записа, докато ще зареди няколко записа, ако използва клъстериран индекс (имайте предвид, че всичко, от което се нуждаем, е ID за бита JOIN). Тъй като това е двоично търсене, не очаквам да помогне много малко. Така че може би нещо друго не е съвсем правилно, но е трудно да се отгатне, без да сте виждали системата.