Дано съм го разбрал правилно. Така че ще повторя.
- Имате 1 таблица с много записи
- Имате този списък от Excel, където търсите „колона за търсене“
- В случай на съвпадение, заменете цялата стойност с „замяна на колона“
Ако това е така, тогава това може да е решението:
declare @data table (Column1 nvarchar(50))
insert into @data
(Column1)
values (N'RbC investment for Seniors 65+'),
(N'RBC inv for juniors')
declare @replace table
(
OriginalValue nvarchar(50),
NewValue nvarchar(50),
[priority] int
)
insert into @replace
(OriginalValue, NewValue, [priority])
values (N'rbc inv', N'RBC dominion securities', 2),
(N'rbc dom', N'RBC dominion securities', 2),
(N'RBC', N'RBC Bank', 3)
update @data
set Column1 = coalesce((
select top 1
NewValue
from @replace
where Column1 like '%' + OriginalValue + '%'
order by [priority]
), Column1)
select *
from @data
Таблицата „данни“ ще бъде тази, в която извършвате замяната.
Може да има доста странични ефекти при използване на това (напр. заместващи символи като % в "search_column", може би множество съвпадения - в момента се взема "произволно" едно, производителността може да не е най-добрата, ...) Но предполагам, че за по-точен отговор, ще ми трябва по-добър въпрос.
Редактиране:
Благодарение на Ралф... Добавих приоритет към таблицата "замяна", за да мога да обработвам дублирани съвпадения.
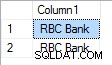
В случай, че "RBC" има приоритет 3, резултатът е:
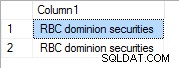
С приоритет 1 е: