Оптимизаторът на SQL Server съдържа логика за премахване на излишни присъединявания, но има ограничения и присъединяванията трябва да бъдат доказуемо излишен . За да обобщим, присъединяването може да има четири ефекта:
- Може да добавя допълнителни колони (от обединената таблица)
- Може да добавя допълнителни редове (съединената таблица може да съответства на изходен ред повече от веднъж)
- Може да премахва редове (съединената таблица може да няма съвпадение)
- Може да въведе
NULLs (заRIGHTилиFULL JOIN)
За да премахнете успешно излишно присъединяване, заявката (или изгледът) трябва да отчете и четирите възможности. Когато това е направено правилно, ефектът може да бъде удивителен. Например:
USE AdventureWorks2012;
GO
CREATE VIEW dbo.ComplexView
AS
SELECT
pc.ProductCategoryID, pc.Name AS CatName,
ps.ProductSubcategoryID, ps.Name AS SubCatName,
p.ProductID, p.Name AS ProductName,
p.Color, p.ListPrice, p.ReorderPoint,
pm.Name AS ModelName, pm.ModifiedDate
FROM Production.ProductCategory AS pc
FULL JOIN Production.ProductSubcategory AS ps ON
ps.ProductCategoryID = pc.ProductCategoryID
FULL JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
FULL JOIN Production.ProductModel AS pm ON
pm.ProductModelID = p.ProductModelID
Оптимизаторът може успешно да опрости следната заявка:
SELECT
c.ProductID,
c.ProductName
FROM dbo.ComplexView AS c
WHERE
c.ProductName LIKE N'G%';
До:

Роб Фарли пише подробно за тези идеи в оригиналната книга за MVP Deep Dives и има запис на негово представяне по темата в SQLBits.
Основните ограничения са, че връзките с външен ключ трябва да се базира на един ключ за да допринесе за процеса на опростяване и времето за компилиране на заявките срещу такъв изглед може да стане доста дълго, особено когато броят на присъединяванията се увеличава. Може да бъде доста предизвикателство да напишете изглед от 100 таблици, който получава цялата семантика точно правилна. Бих бил склонен да намеря алтернативно решение, може би използвайки динамичен SQL .
Въпреки това, специфичните качества на вашата денормализирана таблица може да означават, че изгледът е доста лесен за сглобяване, изисквайки само наложени FOREIGN KEYs не-NULL колони с възможност за рефериране и подходящ UNIQUE ограничения, за да може това решение да работи така, както бихте се надявали, без допълнителни разходи от 100 физически оператора за присъединяване в плана.
Пример
Използване на десет таблици вместо сто:
-- Referenced tables
CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
Дефиницията на родителската таблица (с компресиране на страници):
CREATE TABLE dbo.Normalized
(
pk integer IDENTITY NOT NULL,
col01 tinyint NOT NULL REFERENCES dbo.Ref01,
col02 tinyint NOT NULL REFERENCES dbo.Ref02,
col03 tinyint NOT NULL REFERENCES dbo.Ref03,
col04 tinyint NOT NULL REFERENCES dbo.Ref04,
col05 tinyint NOT NULL REFERENCES dbo.Ref05,
col06 tinyint NOT NULL REFERENCES dbo.Ref06,
col07 tinyint NOT NULL REFERENCES dbo.Ref07,
col08 tinyint NOT NULL REFERENCES dbo.Ref08,
col09 tinyint NOT NULL REFERENCES dbo.Ref09,
col10 tinyint NOT NULL REFERENCES dbo.Ref10,
CONSTRAINT PK_Normalized
PRIMARY KEY CLUSTERED (pk)
WITH (DATA_COMPRESSION = PAGE)
);
Изгледът:
CREATE VIEW dbo.Denormalized
WITH SCHEMABINDING AS
SELECT
item01 = r01.item,
item02 = r02.item,
item03 = r03.item,
item04 = r04.item,
item05 = r05.item,
item06 = r06.item,
item07 = r07.item,
item08 = r08.item,
item09 = r09.item,
item10 = r10.item
FROM dbo.Normalized AS n
JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01
JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02
JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03
JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04
JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05
JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06
JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07
JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08
JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09
JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;
Хакнете статистиката, за да накарате оптимизатора да мисли, че таблицата е много голяма:
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;
Примерна потребителска заявка:
SELECT
d.item06,
d.item07
FROM dbo.Denormalized AS d
WHERE
d.item08 = 'Banana'
AND d.item01 = 'Green';
Дава ни този план за изпълнение:
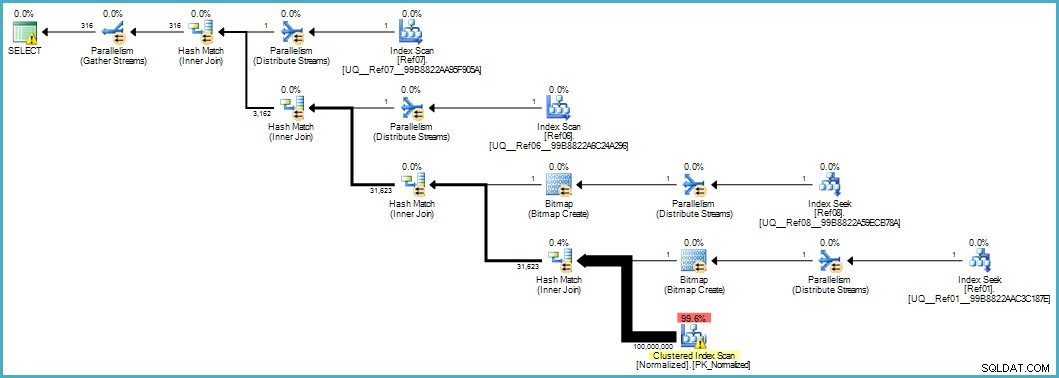
Сканирането на нормализираната таблица изглежда зле, но и двата растерни изображения на Bloom-filter се прилагат по време на сканирането от машината за съхранение (така че редовете, които не могат да съвпадат, дори не се появяват до процесора за заявки). Това може да е достатъчно, за да даде приемлива производителност във вашия случай и със сигурност по-добре от сканирането на оригиналната таблица с нейните препълнени колони.
Ако можете да надстроите до SQL Server 2012 Enterprise на някакъв етап, имате друга опция:създаване на индекс за съхранение на колони в нормализираната таблица:
CREATE NONCLUSTERED COLUMNSTORE INDEX cs
ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);
Планът за изпълнение е:
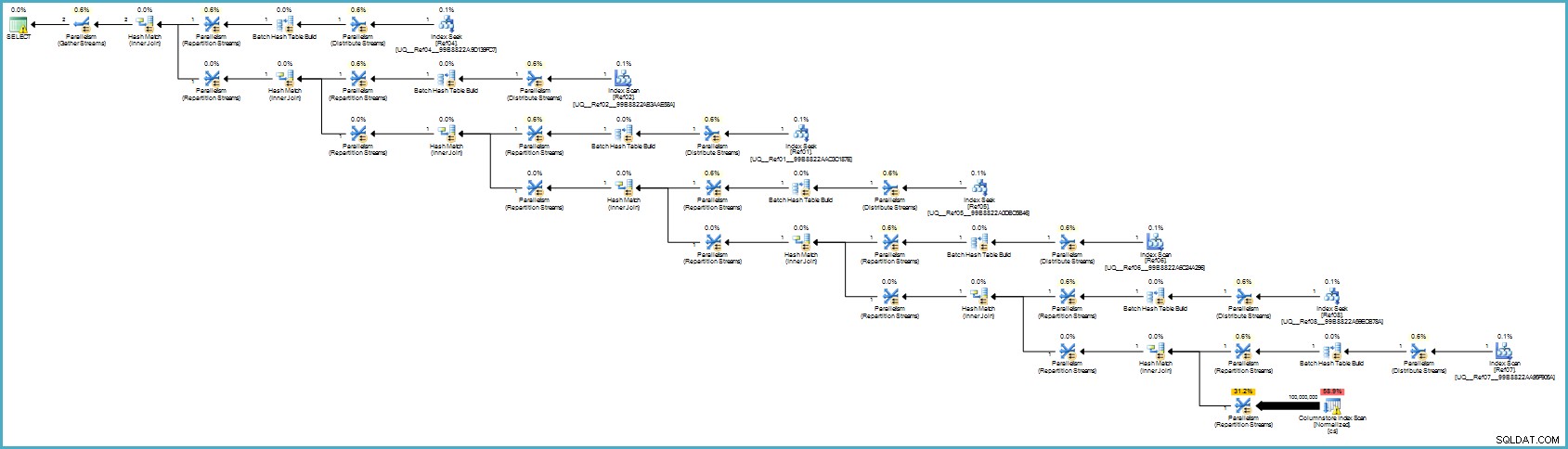
Това вероятно изглежда по-лошо за вас, но съхранението на колони осигурява изключително компресиране и целият план за изпълнение работи в пакетен режим с филтри за всички допринасящи колони. Ако сървърът разполага с подходящи нишки и налична памет, тази алтернатива наистина може да работи.
В крайна сметка не съм сигурен, че това нормализиране е правилният подход, имайки предвид броя на таблиците и шансовете за получаване на лош план за изпълнение или изискване на прекомерно време за компилиране. Вероятно първо бих коригирал схемата на денормализираната таблица (подходящи типове данни и т.н.), евентуално бих приложил компресиране на данни...обичайните неща.
Ако данните наистина принадлежат към звездна схема, вероятно се нуждаят от повече работа по проектиране, отколкото просто разделяне на повтарящи се елементи от данни в отделни таблици.