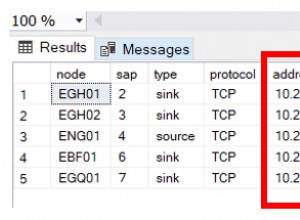
Демонстрация на възможно обяснение.
Създаване на скрипт за таблица
SELECT *
INTO #T
FROM master.dbo.spt_values
CREATE NONCLUSTERED INDEX [IX_T] ON #T ([name] DESC,[number] DESC);
Първа заявка (Връща 35 резултата)
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Втора заявка (Същата като преди, но добавянето на c2.[тип] към списъка за избор води до връщане на 0 резултата);
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type] ,c2.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Защо?
row_number() за дублиращи се ИМЕНА не е посочено, така че просто избира това, което се вписва в най-добрия план за изпълнение за необходимите изходни колони. Във втората заявка това е същото и за двете извиквания на cte, при първата тя избира различен път за достъп с произтичащо различно номериране на редове.
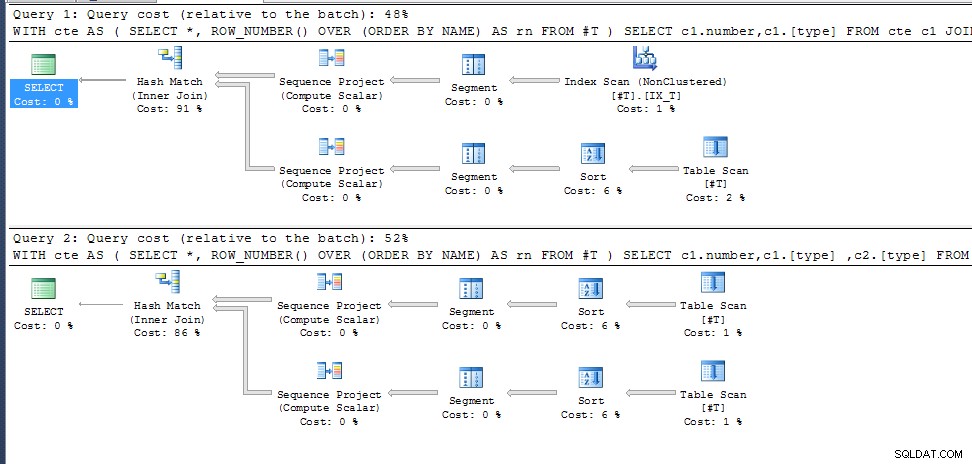
Предложено решение
Вие се присъединявате към CTE на ROW_NUMBER() over (order by t.[Date])
Противно на това, което може да се очаква, CTE вероятно ще не се материализира
което би осигурило съгласуваност за самостоятелното присъединяване и по този начин приемате корелация между ROW_NUMBER() от двете страни, които може и да не съществуват за записи, където дубликат [Date] съществува в данните.
Какво ще стане, ако опитате ROW_NUMBER() over (order by t.[Date], t.[id]) за да се гарантира, че в случай на обвързани дати номерирането на редове е в гарантиран последователен ред. (Или някаква друга колона/комбинация от колони, която може да разграничава записите, ако id не го прави)