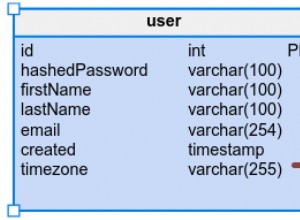
Искам само да предупредя:моля много внимателно изберете вашия групиран индекс! Всяка „обикновена“ таблица с данни трябва да има клъстериран индекс, тъй като наличието на клъстериран индекс наистина ускорява много операции – да, ускорява , дори вмъква и изтрива! Но само ако изберете добър клъстерен индекс.
Това енай-често копираният структура на данните във вашата база данни на SQL Server. Ключът за клъстериране също ще бъде част от всеки един неклъстериран индекс на вашата таблица.
Трябва да бъдете изключително внимателни, когато избирате ключ за клъстериране - той трябва да бъде:
-
тясно (идеални 4 байта)
-
уникален (в края на краищата това е „указателят на реда“. Ако не го направите уникален, SQL Server ще го направи вместо вас на заден план, като ви струва няколко байта за всеки запис, умножен по броя на редовете и броя на неклъстерираните индекси, които имате - това може да струва много скъпо!)
-
статичен (никога не променяйте - ако е възможно)
-
в идеалния случай постоянно нарастващ така че няма да се окажете с ужасна фрагментация на индекса (GUID е пълната противоположност на добрия ключ за клъстериране - поради тази конкретна причина)
-
трябва да е ненулев и в идеалния случай също с фиксирана ширина -
varchar(250)прави много лош ключ за клъстериране
Всичко останало наистина трябва да е второ и трето ниво на важност зад тези точки....
Вижте някои от Кимбърли Трип (Кралицата на индексирането ) публикации в блогове по темата - всичко, което е написала в блога си, е абсолютно безценно - прочетете го, осмислете го - живейте според него!
- GUID като ОСНОВНИ КЛЮЧОВЕ и/или ключ за клъстериране
- Дебатът за клъстерния индекс продължава...
- Непрекъснато нарастващ ключ за клъстериране - дебатът за клъстерирания индекс..........отново!
- Дисковото пространство е евтино - това е не точката!