Групираната конкатенация е често срещан проблем в SQL Server, без директни и умишлени функции, които да го поддържат (като XMLAGG в Oracle, STRING_AGG или ARRAY_TO_STRING(ARRAY_AGG()) в PostgreSQL и GROUP_CONCAT в MySQL). Беше поискано, но все още не е успешно, както се вижда в тези елементи на Connect:
- Свързване #247118 :SQL се нуждае от версия на функцията MySQL group_Concat (Отложено)
- Свързване #728969 :Подреден набор функции – клауза ВЪВ ГРУПА (Затворено, тъй като няма да се поправи)
** АКТУАЛИЗАЦИЯ януари 2017 г. ** :STRING_AGG() ще бъде в SQL Server 2017; прочетете за това тук, тук и тук.
Какво е групирана конкатенация?
За непосветените, групираната конкатенация е, когато искате да вземете няколко реда данни и да ги компресирате в един низ (обикновено с разделители като запетаи, табулатори или интервали). Някои биха могли да нарекат това "хоризонтално присъединяване". Бърз визуален пример, демонстриращ как бихме компресирали списък с домашни любимци, принадлежащи на всеки член на семейството, от нормализирания източник до "сплескания" изход:
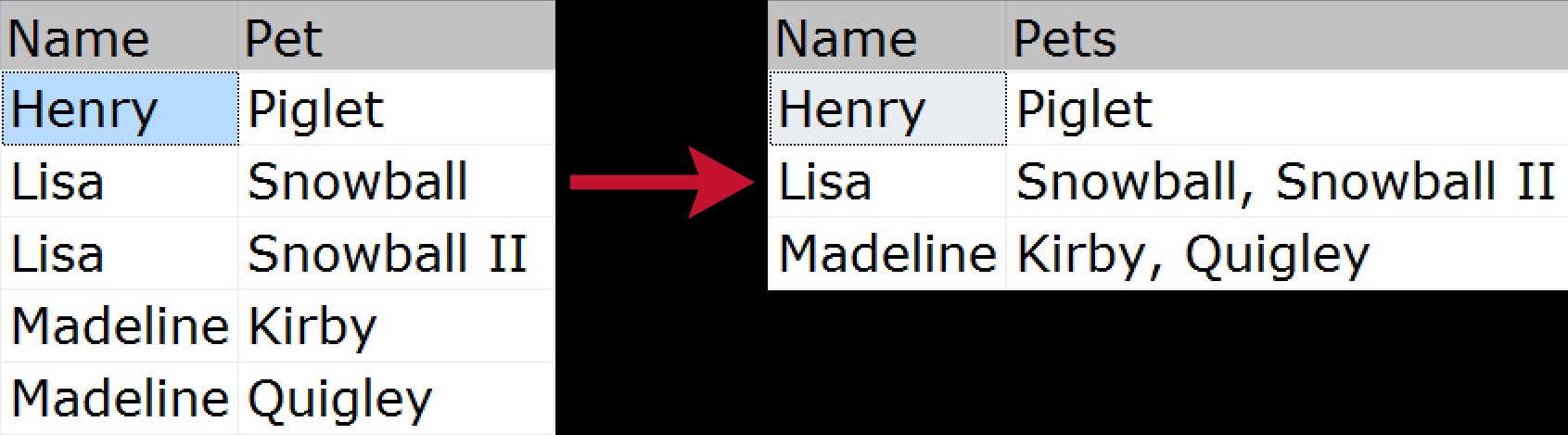
През годините имаше много начини за решаване на този проблем; ето само няколко, базирани на следните примерни данни:
CREATE TABLE dbo.FamilyMemberPets ( Name SYSNAME, Pet SYSNAME, PRIMARY KEY(Name,Pet) ); INSERT dbo.FamilyMemberPets(Name,Pet) VALUES (N'Madeline',N'Kirby'), (N'Madeline',N'Quigley'), (N'Henry', N'Piglet'), (N'Lisa', N'Snowball'), (N'Lisa', N'Snowball II');
Няма да демонстрирам изчерпателен списък на всеки подход за групирана конкатенация, замислен някога, тъй като искам да се съсредоточа върху няколко аспекта на препоръчания от мен подход, но искам да посоча някои от по-често срещаните:
Скаларен UDF
CREATE FUNCTION dbo.ConcatFunction
(
@Name SYSNAME
)
RETURNS NVARCHAR(MAX)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @s NVARCHAR(MAX);
SELECT @s = COALESCE(@s + N', ', N'') + Pet
FROM dbo.FamilyMemberPets
WHERE Name = @Name
ORDER BY Pet;
RETURN (@s);
END
GO
SELECT Name, Pets = dbo.ConcatFunction(Name)
FROM dbo.FamilyMemberPets
GROUP BY Name
ORDER BY Name; Забележка:има причина да не правим това:
SELECT DISTINCT Name, Pets = dbo.ConcatFunction(Name) FROM dbo.FamilyMemberPets ORDER BY Name;
С DISTINCT , функцията се изпълнява за всеки отделен ред, след което дубликатите се премахват; с GROUP BY , дубликатите се премахват първо.
Общоезично време за изпълнение (CLR)
Това използва GROUP_CONCAT_S функция, намерена на https://groupconcat.codeplex.com/:
SELECT Name, Pets = dbo.GROUP_CONCAT_S(Pet, 1) FROM dbo.FamilyMemberPets GROUP BY Name ORDER BY Name;
Рекурсивен CTE
Има няколко варианта на тази рекурсия; този извлича набор от различни имена като котва:
;WITH x as
(
SELECT Name, Pet = CONVERT(NVARCHAR(MAX), Pet),
r1 = ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Pet)
FROM dbo.FamilyMemberPets
),
a AS
(
SELECT Name, Pet, r1 FROM x WHERE r1 = 1
),
r AS
(
SELECT Name, Pet, r1 FROM a WHERE r1 = 1
UNION ALL
SELECT x.Name, r.Pet + N', ' + x.Pet, x.r1
FROM x INNER JOIN r
ON r.Name = x.Name
AND x.r1 = r.r1 + 1
)
SELECT Name, Pets = MAX(Pet)
FROM r
GROUP BY Name
ORDER BY Name
OPTION (MAXRECURSION 0); Курсор
Тук няма много за казване; курсорите обикновено не са оптималният подход, но това може да е единственият ви избор, ако сте останали на SQL Server 2000:
DECLARE @t TABLE(Name SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name));
INSERT @t(Name, Pets)
SELECT Name, N''
FROM dbo.FamilyMemberPets GROUP BY Name;
DECLARE @name SYSNAME, @pet SYSNAME, @pets NVARCHAR(MAX);
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR SELECT Name, Pet
FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
OPEN c;
FETCH c INTO @name, @pet;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @t SET Pets += N', ' + @pet
WHERE Name = @name;
FETCH c INTO @name, @pet;
END
CLOSE c; DEALLOCATE c;
SELECT Name, Pets = STUFF(Pets, 1, 1, N'')
FROM @t
ORDER BY Name;
GO Странна актуализация
Някои хора *обичат* този подход; Изобщо не разбирам привличането.
DECLARE @Name SYSNAME, @Pets NVARCHAR(MAX);
DECLARE @t TABLE(Name SYSNAME, Pet SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name, Pet));
INSERT @t(Name, Pet)
SELECT Name, Pet FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
UPDATE @t SET @Pets = Pets = COALESCE(
CASE COALESCE(@Name, N'')
WHEN Name THEN @Pets + N', ' + Pet
ELSE Pet END, N''),
@Name = Name;
SELECT Name, Pets = MAX(Pets)
FROM @t
GROUP BY Name
ORDER BY Name; ЗА XML ПЪТ
Доста лесно предпочитаният от мен метод, поне отчасти, защото това е единственият начин за *гаранция* поръчка без използване на курсор или CLR. Въпреки това, това е много сурова версия, която не успява да се справи с няколко други присъщи проблема, които ще обсъдя по-нататък:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N'')), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Виждал съм много хора погрешно да приемат, че новият CONCAT() функцията, въведена в SQL Server 2012, беше отговорът на тези заявки за функции. Тази функция е предназначена да работи само срещу колони или променливи в един ред; не може да се използва за конкатенация на стойности в редове.
Още за FOR XML PATH
FOR XML PATH('') сам по себе си не е достатъчно добър – има известни проблеми с XML ентитуализацията. Например, ако актуализирате едно от имената на домашни любимци, за да включва HTML скоба или амперсанд:
UPDATE dbo.FamilyMemberPets SET Pet = N'Qui>gle&y' WHERE Pet = N'Quigley';
Те се превеждат в XML-безопасни обекти някъде по пътя:
Qui>gle&y
Затова винаги използвам PATH, TYPE).value() , както следва:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Също така винаги използвам NVARCHAR , защото никога не се знае кога някоя основна колона ще съдържа Unicode (или по-късно ще бъде променена за това).
Може да видите следните разновидности вътре в .value() , или дори други:
... TYPE).value(N'.', ... ... TYPE).value(N'(./text())[1]', ...
Те са взаимозаменяеми, всички в крайна сметка представляват един и същ низ; разликите в производителността между тях (повече по-долу) бяха незначителни и вероятно напълно недетерминирани.
Друг проблем, който може да срещнете, са определени ASCII знаци, които не са възможни за представяне в XML; например, ако низът съдържа знака 0x001A (CHAR(26)). ), ще получите това съобщение за грешка:
FOR XML не можа да сериализира данните за възел 'NoName', защото съдържа символ (0x001A), който не е разрешен в XML. За да извлечете тези данни с помощта на FOR XML, преобразувайте ги в двоичен, варбиниран или графичен тип данни и използвайте директивата BINARY BASE64.
Това ми изглежда доста сложно, но се надявам, че не е нужно да се притеснявате за това, защото не съхранявате данни като този или поне не се опитвате да ги използвате в групирана конкатенация. Ако сте, може да се наложи да се върнете към някой от другите подходи.
Ефективност
Горните примерни данни улесняват доказването, че всички тези методи правят това, което очакваме, но е трудно да ги сравним смислено. Така че попълних таблицата с много по-голям набор:
TRUNCATE TABLE dbo.FamilyMemberPets; INSERT dbo.FamilyMemberPets(Name,Pet) SELECT o.name, c.name FROM sys.all_objects AS o INNER JOIN sys.all_columns AS c ON o.[object_id] = c.[object_id] ORDER BY o.name, c.name;
За мен това бяха 575 обекта, с общо 7080 реда; най-широкият обект имаше 142 колони. Сега отново, да си призная, не си поставих за цел да сравнявам всеки един подход, замислен в историята на SQL Server; само няколкото акцента, които публикувах по-горе. Ето резултатите:
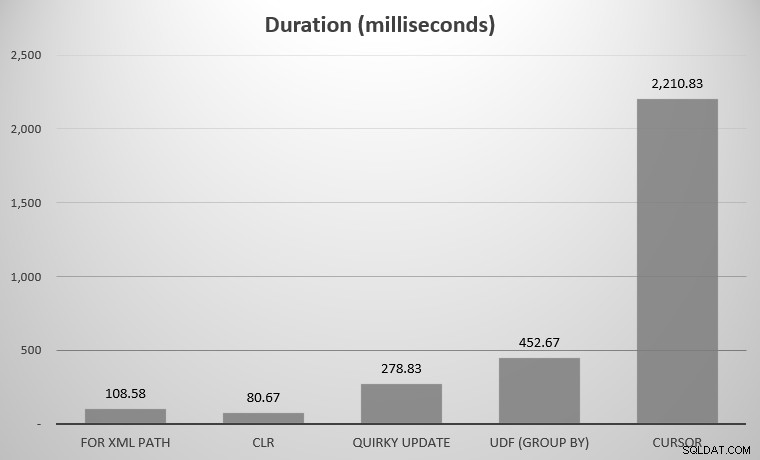
Може да забележите, че липсват няколко претендента; UDF с помощта на DISTINCT и рекурсивният CTE бяха толкова извън класациите, че биха изкривили скалата. Ето резултатите от всичките седем подхода в табличен вид:
| Подход | Продължителност (милисекунди) |
|---|---|
| ЗА XML ПЪТ | 108,58 |
| CLR | 80,67 |
| Странна актуализация | 278,83 |
| UDF (GROUP BY) | 452,67 |
| UDF (различимо) | 5 893,67 |
| Курсор | 2210,83 |
| Рекурсивен CTE | 70 240,58 |
Средна продължителност, в милисекунди, за всички подходи
Също така имайте предвид, че вариациите на FOR XML PATH бяха тествани независимо, но показаха много малки разлики, така че просто ги комбинирах за средното. Ако наистина искате да знаете, .[1] нотацията работи най-бързо в моите тестове; YMMV.
Заключение
Ако не сте в магазин, където CLR е пречка по някакъв начин, и особено ако не се занимавате само с прости имена или други низове, определено трябва да помислите за проекта CodePlex. Не се опитвайте да изобретявате колелото, не опитвайте неинтуитивни трикове и хакове, за да направите CROSS APPLY или други конструкции работят само малко по-бързо от не-CLR подходите по-горе. Просто вземете това, което работи и го включете. И, по дяволите, тъй като получавате и изходния код, можете да го подобрите или да го разширите, ако желаете.
Ако CLR е проблем, тогава FOR XML PATH вероятно е най-добрият ви вариант, но все пак ще трябва да внимавате за трудни герои. Ако сте заседнали в SQL Server 2000, единствената ви възможна опция е UDF (или подобен код, който не е обвит в UDF).
Следващия път
Няколко неща, които искам да проуча в последваща публикация:премахване на дубликати от списъка, подреждане на списъка по нещо различно от самата стойност, случаи, при които поставянето на някой от тези подходи в UDF може да бъде болезнено, и практически случаи на употреба за тази функционалност.



