В тази статия ще обсъдим няколко проблема, с които може да се сблъскате, докато създавате, конфигурирате или поддържате сайт на групата за винаги на разположение.
Преди да преминете през тази статия, препоръчително е да прочетете предишната статия, Настройка и конфигуриране на групата за винаги наличност в SQL Server, за да се запознаете с концепцията за групата за винаги на разположение и съветниците за нова група за наличност, показани в тази статия.
Винаги включена група за наличност не е активирана
Да приемем, че докато се опитвате да създадете нова Always on Availability Group, от възела Always On High Availability, под Object Explorer на SQL Server Management Studio, сте се сблъскали със съобщението за грешка по-долу:
Функцията Always On Availability Groups трябва да бъде активирана за сървърния екземпляр „SQL1“, преди да можете да създадете група за наличност на този екземпляр. За да активирате тази функция, отворете SQL Server Configuration Manager, изберете SQL Server Services, щракнете с десния бутон върху името на услугата на SQL Server, изберете Properties и използвайте раздела Always On Availability Groups в диалоговия прозорец Свойства на сървъра. Активирането на Always On Availability Groups може да изисква сървърният екземпляр да се хоства от възел на Windows Server Failover Cluster (WSFC). (Microsoft.SqlServer.Management.HadrTasks)

От съобщението за грешка става ясно, че функцията AlwaysOn Availability Groups трябва да бъде активирана на всеки екземпляр на SQL Server, който участва в сайта Always on Availability Group, преди да създадете този сайт.
Можете лесно да активирате функцията Always on Availability Group, като отворите конзолата на SQL Server Configuration Manager, прегледайте раздела SQL Server Services, след което щракнете с десния бутон върху услугата SQL Server Database Engine и изберете опцията Properties.
От отворения прозорец със свойства на SQL Server преминете към раздела Always on High Availability и поставете отметка в квадратчето до Enable Always on Availability Group , като се има предвид, че тази промяна изисква рестартиране на услугата SQL Server, за да влезе в сила, както е показано по-долу:

Проблем с проверката на предварителните условия на базата данни
В по-ранните стъпки на съветника за нова група за наличност ще бъдете помолени да посочите базата данни(и), които ще участват в групата за винаги наличност. Преди да добавите базата данни, тя трябва да премине проверката за валидиране на предварителни условия. В противен случай базата данни не може да бъде избрана от списъците с бази данни, както е показано в съобщението за грешка по-долу:
За да бъде добавена към група за наличност, тази база данни трябва да бъде настроена на модела за пълно възстановяване. Задайте свойството на базата данни модел за възстановяване на Пълно и извършете пълно или диференциално архивиране на базата данни на базата данни. След това ще трябва да планирате архивиране на регистрационни файлове в базата данни.

Посланието е ясно. Когато базата данни трябва да бъде конфигурирана с модел за пълно възстановяване и пълно или диференциално архивиране трябва да се извърши на тази база данни.
Освен това съветникът ви предупреждава да планирате архивиране на регистрационния файл на транзакциите за тази база данни, след като промените модела за възстановяване на Пълен, за да съкратите автоматично регистрационния файл на транзакциите и да предотвратите стартирането на този регистрационен файл на транзакциите без свободно пространство.
За да коригирате този проблем, променете модела за възстановяване на базата данни от Simple на Full, от раздела Options на прозореца със свойства на базата данни, след което направете пълно архивиране от тази база данни, както е показано по-долу:

При опресняване на прозореца Избор на бази данни състоянието на базата данни ще бъде променено на Изпълнение на предпоставките, както е показано по-долу:

Проблем с разрешението за местоположение в споделена мрежа
Докато се опитвате да конфигурирате сайт за група за винаги на разположение, стъпката за валидиране на съветника за нова група наличност се провали със съобщението за грешка по-долу:
Основният сървър „SQL1“ не може да пише в „\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak“. (Microsoft.SqlServer.Management.HadrModel)
Архивирането на сървъра „SQL1“ не бе успешно. (Microsoft.SqlServer.SmoExtended)
Не може да се отвори резервното устройство „\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak“. Грешка в операционната система 5 (Достъпът е отказан.).
BACKUP DATABASE завършва необичайно. (.Net SqlClient доставчик на данни)
В метода за първоначално синхронизиране на Пълно архивиране на база данни и регистрационни файлове се изисква споделена папка, за да се съхраняват временно пълните архивни файлове и файловете за архивиране на регистрационни файлове на транзакции, за да се възстанови във всички вторични реплики. Ако основната реплика не може да запише архивните файлове в нея или вторичните реплики не могат да прочетат архивните файлове от нея, процесът на валидиране на новата група за наличност ще се провали, както следва:

За да коригираме този проблем, трябва да предоставим на акаунта за услугата на SQL Server на първичните и вторичните реплики разрешение за четене и запис в споделената папка, показана в съобщението за грешка, след което да стартираме отново процеса на валидиране, за да се уверим, че всички проверки са успешни , както е показано по-долу:

Проблем с клъстер при отказ на Windows
Да приемем, че проверявате състоянието на съществуващ сайт на групата за винаги на разположение и вижте, че:
- Основната роля се премества от SQL1 екземпляр към SQL2.
- В SQL2 базите данни са в синхронизирано състояние.
- В SQL1 базите данни не са синхронизирани.
- SQL1 е в състояние на разрешаване.
Както можете да видите ясно от SSMS Object Explorer по-долу:

Проверявайки регистрационните файлове за грешки на SQL Server в проблемния възел, можем да видим, че репликата на групата за наличност става офлайн и групата за наличност спря да работи поради проблем в клъстера за отказване на Windows Server, както е показано в грешките по-долу:
- Винаги включени групи за наличност:Възелът на локалния клъстер при отказ на Windows Server вече не е онлайн . Това е само информационно съобщение. Не се изисква действие от потребителя.
- Винаги включен:Мениджърът на реплика за наличност излиза офлайн, тъй като локалният възел на Windows Server Failover Clustering (WSFC) е загубил кворум. Това е само информационно съобщение. Не се изисква действие от потребителя.
- Винаги включено:Локалната реплика на групата за наличност „DemoGroup“ спира. Това е само информационно съобщение. Не се изисква действие от потребителя.

Същото нещо може да бъде открито от Windows Server Event Viewer, което показва постепенно как репликата променя състоянието си на състояние на разрешаване, както е посочено по-долу:
- Винаги включено:Локалната реплика на групата за наличност „DemoGroup“ се готви да премине към ролята на разрешаване . Това е само информационно съобщение. Не се изисква действие от потребителя.
- Групата за наличност „DemoGroup“ е помолена да спре подновяването на лизинга, защото групата за наличност излиза офлайн . Това е само информационно съобщение. Не се изисква действие от потребителя.
- Състоянието на локалната реплика за наличност в групата за наличност „DemoGroup“ се промени от „PRIMARY_NORMAL“ на „RESOLVING_NORMAL“. Състоянието се промени, защото групата за достъпност е офлайн. Репликата излиза офлайн, защото асоциираната група за наличност е била изтрита или потребителят е прехвърлил свързаната група за наличност офлайн в конзолата за управление на отказоустойчив клъстер на Windows (WSFC), или групата за наличност се прехвърля към друг екземпляр на SQL Server. За повече информация вижте дневника за грешки на SQL Server или регистъра на клъстера. Ако това е група за наличност на отказоустойчив клъстер на Windows Server (WSFC), можете да видите и конзолата за управление на WSFC.

За да проверим състоянието на сайта на клъстера на Windows, ще използваме мениджъра на клъстер за отказване, за да видим коя част от клъстера на Windows е неуспешна.
Но мениджърът на клъстер при отказ показва, че целият клъстер не работи, както е показано по-долу:

Първото нещо, което трябва да потвърдите тук от страна на Windows Failover Cluster, е услугата на клъстера, която може да се провери от конзолата на услугите на Windows, както е по-долу:

От конзолата на услугите става ясно, че услугата на клъстера не работи. За да отстраните този проблем, стартирайте услугата от тази конзола, след което опреснете конзолата Failover Cluster Manager, за да се уверите, че сайтът на Windows Cluster работи и работи, както е показано по-долу:

Проверявайки отново групата Always on Availability Group, ще видите, че базите данни са отново синхронизирани и сайтът Always on Availability Group отново е в здравословно състояние, както е показано по-долу:

Регистрационният файл на транзакциите е пълен на основната страна
Да приемем, че получавате следното съобщение за грешка, когато се опитвате да изпълните нова заявка в една от базите данни на Always on Availability Group:

Проверявайки какво блокира регистрационния файл на транзакциите и предотвратява съкращаването му, ще видите, че регистрационният файл на транзакциите на тази база данни чака операция за архивиране на регистрационни файлове, която да бъде съкратена, както е показано по-долу:

Изготвяне на резервно копие на регистрационния файл на транзакциите за тази база данни, в случай че забравите да планирате задание за архивиране на регистрационния файл на транзакции, както следва:

И проверете отново какво блокира регистъра на транзакциите на тази база данни, показва в моя сценарий, че чака Availability_Replica. Което означава, че регистрационните файлове чакат да бъдат записани във вторичната реплика, но не могат да изпратят тези регистрационни файлове на транзакциите към вторичните реплики поради проблем в сайта Always on Availability Group, както е по-долу:

Най-доброто място за проверка и отстраняване на неизправности на сайта Always on Availability Group е Always on Dashboard, което може да се отвори, като щракнете с десния бутон върху името на групата за наличност и изберете опцията Покажи таблото за управление.
От таблото за управление можете да видите, че вторичната реплика SQL2 не е синхронизирана с основната реплика поради проблем със свързаността, както е показано по-долу:

Проверете вторичната реплика и се уверете, че услугата на SQL Server работи и работи на вторичната страна, както следва:

След това, като обновите отново таблото на групата за наличност, ще видите, че сайтът на Always on Availability Group отново е здрав. Проверявайки дали файлът с регистрационни файлове на транзакциите е блокиран от някаква операция, ще видим, че е в изчакване OLDEST_PAGE, което показва, че най-старата страница на базата данни е по-стара от контролната точка LSN. Този проблем може да бъде отстранен лесно, като направите друго резервно копие на регистрационния файл на транзакциите и регистрационният файл на транзакциите няма да бъде блокиран от нищо, както е показано ясно по-долу:

Винаги включена грешка при отказ на групата за наличност
Да приемем, че основната реплика става офлайн поради непланиран проблем. Както се очаква, системата няма да бъде засегната, тъй като ще бъде извършена операция за автоматично преминаване при отказ и вторичната реплика ще действа като нова първична реплика.
Но в нашия случай този щастлив сценарий не е валиден, където вторичната реплика се промени в състояние на разрешаване и системата не работи!

Проверявайки регистъра за грешки на вторичната реплика и вижте защо тя не действа като новия първичен, както се очаква, ще видите, че не работи поради проблем със синхронизирането на ролите, както е показано по-долу:
Базата данни на групата за наличност „AdventureWorks2017“ сменя ролите от „SECONDARY“ на „RESOLVING“, защото огледалната сесия или групата за наличност не успяха поради синхронизиране на ролите. Това е само информационно съобщение. Не се изисква действие от потребителя.

Това означава, че има проблем с режима на синхронизация, който се използва в тази група за наличност. Използваният режим на синхронизация може да се провери от страницата със свойства на групата за винаги наличност.
От страницата със свойства по-долу става ясно, че режимът на отказ в тази група за наличност е конфигуриран да се изпълнява само ръчно. В този случай трябва ръчно да извършите операция за преодоляване на срив, преди да рестартирате или изключите сървъра:

Това може да бъде поправено лесно, като промените режима на отказ на автоматичен, където ще се извърши автоматична операция за превключване при отказ в случай на непланирано изключване или рестартиране:

Същият проблем може да се сблъска, когато кворумът на Windows Failover Cluster е конфигуриран с Node Majority за четен брой реплики, при което всяка повреда на един от сървърите ще доведе до офлайн сайта на Windows Failover Cluster. За повече информация проверете режимите на кворума на клъстер при отказ на Windows в Групи за винаги наличност на SQL Server:

Отказ при загуба на данни
Да приемем, че се опитвате да извършите ръчно преодоляване на отказ между първичната и една от вторичните реплики, но в прозореца Избор на нова първична реплика виждате предупредително съобщение, че операцията по отказ може да завърши със загуба на данни като първичната и избраната Вторичните реплика не са синхронизирани, както е показано по-долу:

За да идентифицираме причината за този проблем, ще прегледаме събитията Always on Health, като използваме таблото за управление на Always on Availability Group, което показва, че основната реплика не може да отвори връзка с вторичната реплика, както е показано по-долу:

След като коригирате проблема с връзката между първичния и вторичния, опреснете списъка с реплики и ще видите, че проблемът със загубата на данни е отстранен, както е показано по-долу. За повече информация относно отстраняването на проблеми със свързаността проверете Отстраняване на неизправности при свързването към SQL Server Database Engine.

Наблюдение на латентността на групата за наличност винаги при наличност
Таблото за управление на Availability Group може да бъде променено, за да включва допълнителни колони, които предоставят информация за забавянето на синхронизиране между първични и вторични реплики, включително Commit LSN, Sent LSN и затвърдете LSN стойности, без да показва защо има забавяне, както е показано по-долу:
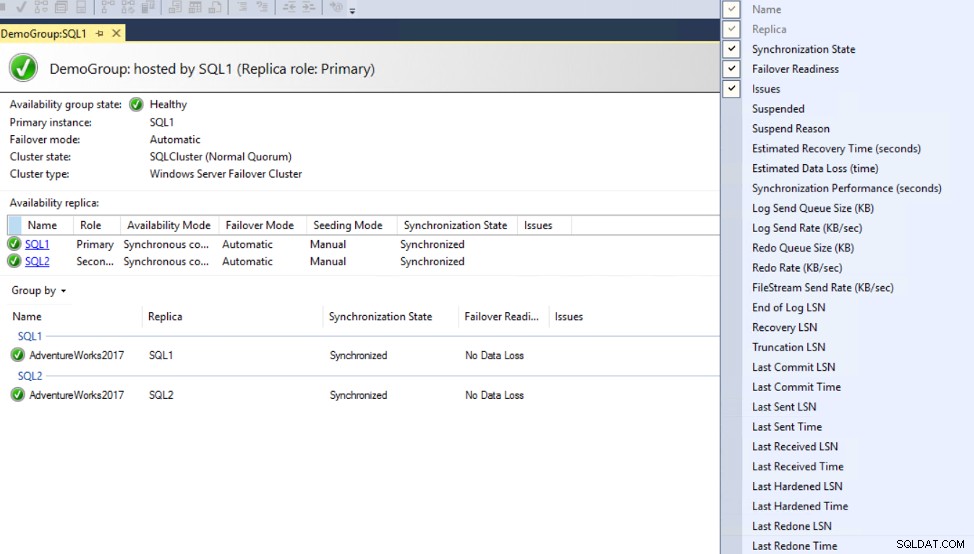
За повече информация относно измерването на латентността проверете Измерване на изоставането при синхронизиране на групата за наличност.
Започвайки от SSMS 17.4, таблото за управление на Always on Availability Group е подобрено, за да включва две нови опции, които се използват за изчисляване, анализ и отчитане на информацията за забавяне, което помага при идентифицирането на тесните места в потока на регистрационните файлове на транзакциите между първичните и вторичните реплики и стеснява причината за това забавяне.
За повече информация относно новата функционалност и отчети, поставете отметка за Използване на таблото за управление на групата за винаги наличност.
За да задействате използването на тази нова опция, кликнете върху Събиране на данни за забавяне опция от таблото за управление Always on Availability Group, която ще създаде ново задание на SQL агент на първичните и вторичните реплики за събиране на данните за забавяне, както е показано по-долу:

Когато създаденото изпълнение на задание завърши за всички реплики на групата за наличност, ще можете да видите статистическите данни за закъсненията от отчетите за закъсненията, като щракнете с десния бутон върху името на групата наличност и изберете отчета за забавяне на първичната реплика или закъснението на вторичната реплика, въз основа на ролята на реплика в групата за наличност.
След предоставяне на информация за репликите на групата наличност, отчетът за закъснението ще покаже графичен изглед на времето за извършване на регистрационния файл на транзакциите за първичната реплика и отдалеченото време за втвърдяване за вторичните реплики, обобщени като средни стойности. Освен това отчетът предоставя статистически стойности за регистрационните файлове на транзакциите, изпращани, получаване, записване, компресиране, декомпресиране и други числови стойности въз основа на ролята на реплика в групата за наличност.
За повече информация относно отчета за закъснението, проверете Ново в SSMS – Отчетите за закъсненията на групата за винаги наличност.
Отчетът по-долу е пример за отчетите за забавяне, генерирани от вторичната реплика, показващи нормални операции за транспортиране на регистрационни файлове:

Също така, Закъснение на регистрационния блок отчетът показва времето, в ms, през което регистърът на транзакциите на първичната реплика изчаква вторични реплики да извършат тази транзакция. След като го активирате от таблото за управление на групата наличност, можете да го прегледате от SSMS, подобно на предишните отчети за забавяне. Вземете под внимание, че голямото време на латентност показва, че първичната реплика чака дълго време вторичните реплики да извършат изпратените транзакции, както е показано по-долу: