На върха на главата ми, имам 50% решение за вас.
Проблемът
SSIS наистина се грижи за метаданните, така че вариациите в тях обикновено водят до изключения. DTS беше много по-прощаващ в този смисъл. Тази силна нужда от последователни метаданни прави използването на плоския файлов източник проблемно.
Решение, базирано на заявка
Ако проблемът е в компонента, нека не го използваме. Това, което харесвам в този подход, е, че концептуално е същото като заявка за таблица – редът на колоните няма значение, нито наличието на допълнителни колони.
Променливи
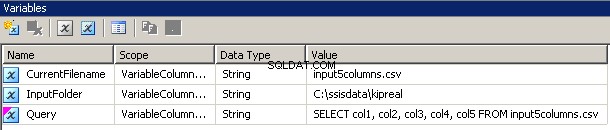
Създадох 3 променливи, всички от тип низ:CurrentFileName, InputFolder и Query.
- InputFolder е твърдо свързан към изходната папка. В моя пример това е
C:\ssisdata\Kipreal - CurrentFileName е името на файл. По време на проектирането беше
input5columns.csvно това ще се промени по време на изпълнение. - Заявката е израз
"SELECT col1, col2, col3, col4, col5 FROM " + @[User::CurrentFilename]
Мениджър на връзки
Настройте връзка с входния файл с помощта на драйвера JET OLEDB. След като го създадох, както е описано в свързаната статия, го преименувах на FileOLEDB и зададох израз в ConnectionManager на "Data Source=" + @[User::InputFolder] + ";Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=\"text;HDR=Yes;FMT=CSVDelimited;\";"
Контролен поток
Моят контролен поток изглежда като задача за поток от данни, вложена в преброител на файлове Foreach
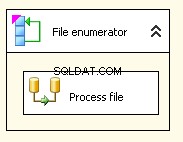
Преброител за всеки файл
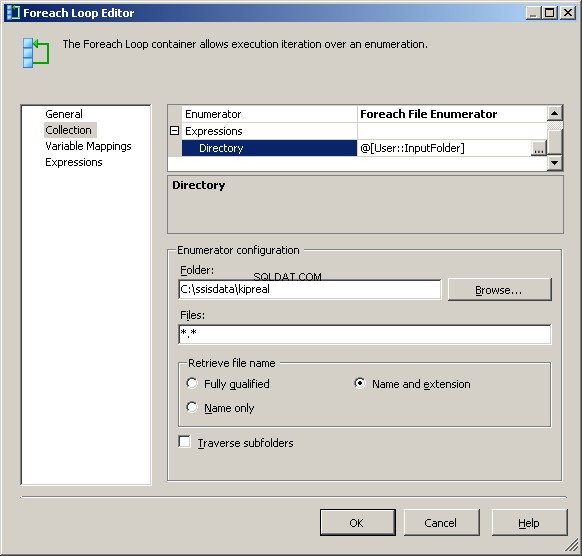
Моят преброител на файлове Foreach е конфигуриран да работи с файлове. Поставих израз в директорията за @[User::InputFolder] Забележете, че в този момент, ако стойността на тази папка трябва да се промени, тя ще бъде правилно актуализирана както в диспечера на връзките, така и в преброителя на файлове. В „Извличане на име на файл“ вместо „Напълно квалифициран“ по подразбиране изберете „Име и разширение“
В раздела Съпоставяне на променливи задайте стойността на нашия @[User::CurrentFileName] променлива
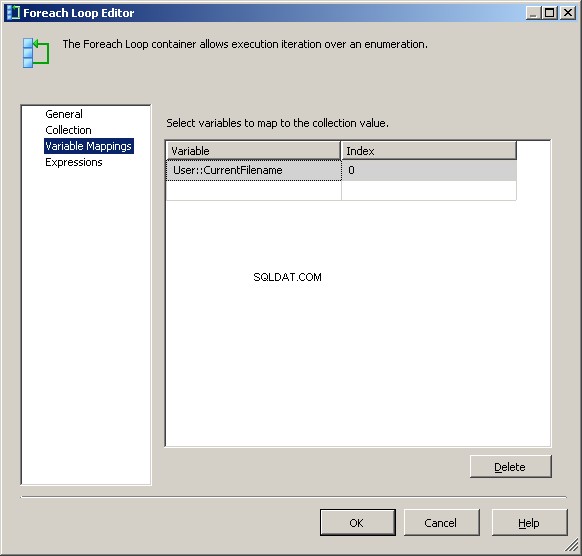
В този момент всяка итерация на цикъла ще промени стойността на @[User::Query за да отразява текущото име на файла.
Поток на данни
Това всъщност е най-лесното парче. Използвайте източник на OLE DB и го свържете, както е посочено.
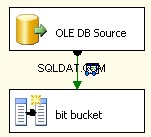
Използвайте мениджъра на връзки FileOLEDB и променете режима за достъп до данни на „SQL команда от променлива“. Използвайте @[User::Query] променлива там, щракнете върху OK и сте готови за работа. 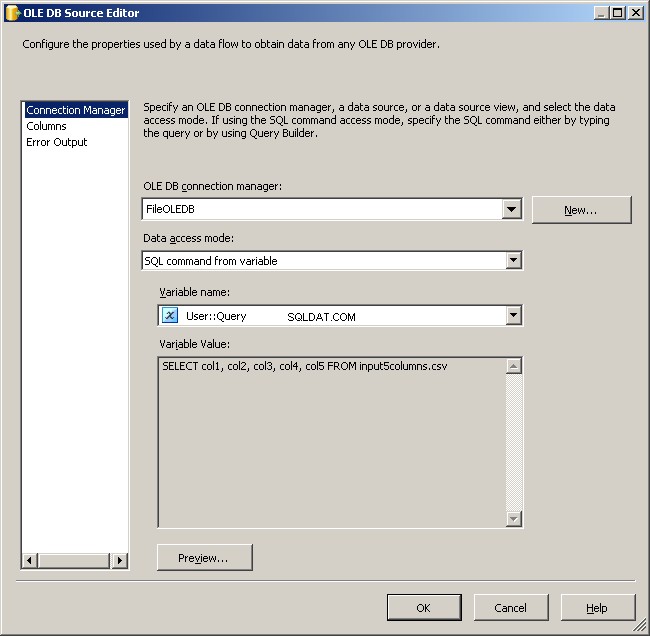
Примерни данни
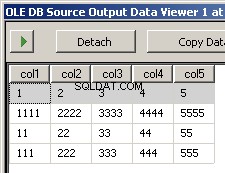
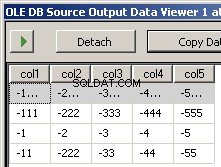
Създадох два примерни файла input5columns.csv и input7columns.csv Всички колони от 5 са в 7, но 7 ги има в различен ред (col2 е редна позиция 2 и 6). Отричах всички стойности в 7, за да стане ясно кой файл се оперира.
col1,col3,col2,col5,col4
1,3,2,5,4
1111,3333,2222,5555,4444
11,33,22,55,44
111,333,222,555,444
и
col1,col3,col7,col5,col4,col6,col2
-1111,-3333,-7777,-5555,-4444,-6666,-2222
-111,-333,-777,-555,-444,-666,-222
-1,-3,-7,-5,-4,-6,-2
-11,-33,-77,-55,-44,-666,-222
Изпълнението на пакета води до тези две екранни снимки
Какво липсва
Не знам начин да кажа на базирания на заявка подход, че е добре, ако колона не съществува. Ако има уникален ключ, предполагам, че бихте могли да дефинирате заявката си така, че да съдържа само колоните, които трябва бъдете там и след това извършете справки във файла, за да опитате да получите колоните, които трябва да бъде там и да не провали търсенето, ако колоната не съществува. Доста тъпо обаче.