Въведение
Таблицата е логическа структура. Когато създавате таблица, обикновено не ви пука на кои устройства се намира в слоя за съхранение. Въпреки това, ако сте администратор на база данни, това знание може да стане от съществено значение, ако трябва да преместите определени части от базата данни в алтернативно хранилище или обем. След това може да искате определени таблици да са на конкретен том или набор от дискове.
Файловите групи в SQL Server предлагат този слой на абстракция, който ни позволява да контролираме физическото местоположение на нашите логически структури – таблици, индекси и т.н.
Файлови групи
Файловата група е логическа структура за групиране на файлове с данни в SQL Server. Ако създадем файлова група и я свържем с набор от файлове с данни, всеки логически обект, създаден в тази файлова група, ще бъде физически разположен в този набор от физически файлове.
Основната цел на такова физическо групиране на файлове е разпределението на данни и разполагането на данни. Например, ние искаме нашите транзакционни данни да се съхраняват на един набор от бързи дискове. Едновременно с това се нуждаем от исторически данни, съхранявани на друг набор от по-евтини дискове. В такъв сценарий ще създадем Tran таблица във файловата група TXN и TranHist таблица в друга файлова група HIST. По-нататък в тази статия ще видим как това означава разполагане на данни на различни дискове.
Създаване на файлови групи
Синтаксисът за създаване на файлови групи е показан в Списък 1 . Забележка :Контекстът на базата данни е главен база данни. При издаването на изразите ние променяме DB2 базата данни, като добавяме нови файлови групи към нея. По същество тези файлови групи са просто логически конструкции в този момент. Те не съдържат никакви данни.
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
Добавяне на файлове към файлови групи
Следващата стъпка е да добавите файл към всяка от файловите групи. Можем да добавим повече от един файл, но го поддържаме прост за демонстрационни цели. Забележете, че всеки файл е изцяло на различно устройство и синтаксисът ни позволява да посочим желаната файлова група.
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
Създаване на таблици към файлови групи
Тук гарантираме, че таблиците са на желаните дискове. Синтаксисът за създаване на таблици ни позволява да посочим желаната файлова група.
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
Правейки крачка назад, отбелязваме, че вече постигнахме следното:
- Създадени две файлови групи.
- Определя файловете с данни (и дисковете), свързани с всяка файлова група.
- Определи таблиците, свързани с всяка файлова група.
По същество файловата група е абстракционният слой .
Проверка на кои файлови групи се намират нашите таблици
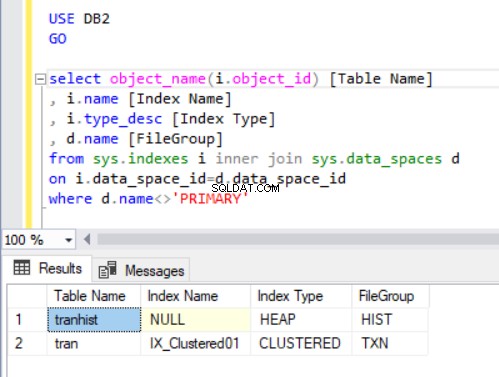
За да проверим към коя файлова група принадлежи всяка таблица, ще изпълним кода в листинг 4. Използваме два основни изгледа на системен каталог:sys.indexes и sys.data_spaces . sys.data_spaces каталожният изглед съдържа информация за файлови групи и дялове, както и основните логически структури, където се съхраняват таблици и индекси.
Забележка:Не използвахме sys.tables . SQL Server свързва индекси в таблица с пространства за данни, а не с таблици, както може интуитивно да мислим.
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
Резултатът от заявката в листинг 4 показва две таблици, които току-що създадохме. Забележете, че транхист таблицата няма индекс. Все пак се показва в набора от резултати, идентифициран като хийп .
Купа е таблица, която няма клъстериран индекс, определящ данните за поръчката, физически съхранявани в таблица. Може да има само един клъстериран индекс в таблица.
Попълване на таблицата Tran
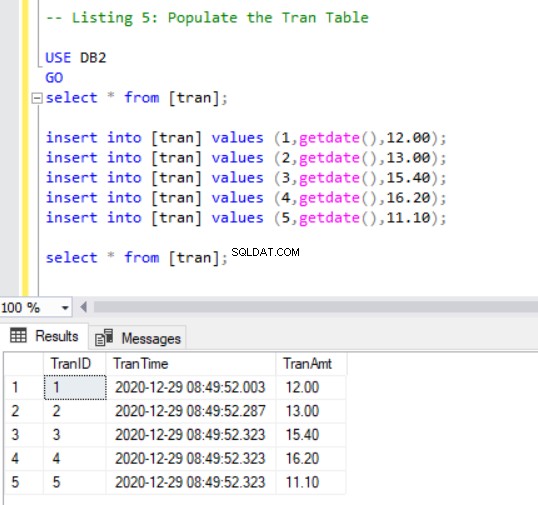
Сега трябва да добавим няколко записа към tran таблица, използвайки следния код:
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
Преместване на таблица в друга файлова група
За да преместите тран таблица към друга файлова група, трябва само да престроим клъстерирания индекс и посочете новата файлова група, докато правите това повторно изграждане. Списък 5 показва този подход.
Изпълняваме две стъпки:първо пускаме индекса, след това го създаваме отново. Междувременно проверяваме дали данните и местоположението на двете таблици, които създадохме по-рано, остават непокътнати.
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
При премахване на клъстерирания индекс от tran таблица, ние я преобразувахме в heap :
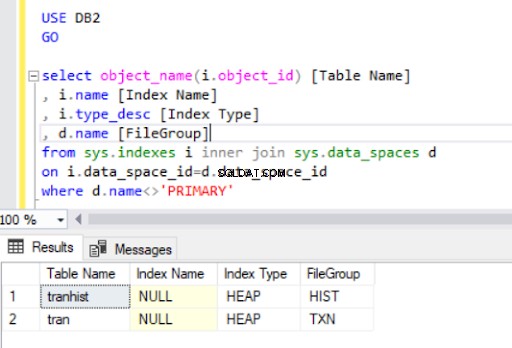
Когато пресъздадем клъстерирания индекс, той също се посочва в изхода на листинг 4.
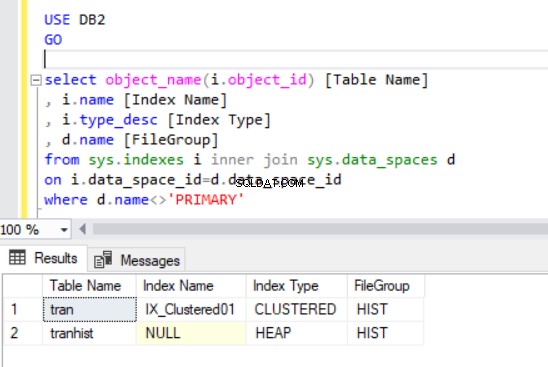
Сега имаме тран таблица във файловата група HIST.
Заключение
Тази статия демонстрира връзката между таблици, индекси, файлове и файлови групи по отношение на нашето съхранение на данни в SQL Server. Ние също така обяснихме преместването на таблица от една файлова група в друга чрез пресъздаване на клъстерирания индекс.
Това умение ще бъде полезно, когато трябва да мигрирате данни към ново хранилище (по-бързи дискове или по-бавни дискове за архивиране). В по-разширени сценарии можете да използвате файлови групи за управление на жизнения цикъл на данните чрез внедряване на дялове на таблици.
Препратки
- Файлове и файлови групи от бази данни
- Изключване на дялове на таблицата – ръководство