Все още ли държите на дизайна родител/дете или бихте искали да опитате нещо ново, като SQL Server hierarchyID? Е, наистина е ново, защото hierarchyID е част от SQL Server от 2008 г. Разбира се, самата новост не е убедителен аргумент. Но имайте предвид, че Microsoft добави тази функция, за да представи връзките едно към много с множество нива по по-добър начин.
Може да се чудите каква е разликата и какви ползи получавате от използването на hierarchyID вместо обичайните връзки родител/дете. Ако никога не сте проучвали тази опция, може да е изненадващо за вас.
Истината е, че не проучвах тази опция, откакто беше пусната. Въпреки това, когато най-накрая го направих, го намерих за страхотна иновация. Това е по-добре изглеждащ код, но има много повече в него. В тази статия ще разберем за всички тези отлични възможности.
Въпреки това, преди да се потопим в особеностите на използването на SQL Server hierarchyID, нека изясним неговото значение и обхват.
Какво е SQL Server HierarchyID?
SQL Server hierarchyID е вграден тип данни, предназначен да представя дървета, които са най-често срещаният тип йерархични данни. Всеки елемент в дървото се нарича възел. Във формат на таблица това е ред с колона от тип данни за йерархия.
Обикновено ние демонстрираме йерархии с помощта на дизайн на таблица. Колоната с идентификатор представлява възел, а друга колона означава родител. С идентификатора на йерархията на SQL Server се нуждаем само от една колона с тип данни йерархичен идентификатор.
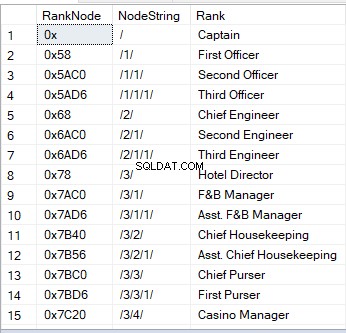
Когато отправяте заявка към таблица с колона за йерархия, виждате шестнадесетични стойности. Това е едно от визуалните изображения на възел. Друг начин е низ:
‘/’ означава основния възел;
„/1/“, „/2/“, „/3/“ или „/n/“ означават децата – преки потомци от 1 до n;
„/1/1/“ или „/1/2/“ са „децата на децата – „внуци“. Низът като „/1/2/“ означава, че първото дете от корена има две деца, които от своя страна са двама внуци на корена.
Ето пример за това как изглежда:
За разлика от други типове данни, колоните на hierarchyID могат да се възползват от вградените методи. Например, ако имате колона за йерархия с име RankNode , можете да имате следния синтаксис:
RankNode.<име на метод> .
Методи за идентификация на йерархията на SQL сървър
Един от наличните методи е IsDescendantOf . Връща 1, ако текущият възел е потомък на стойността на йерархия.
Можете да пишете код с този метод, подобен на този по-долу:
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1Други методи, използвани с hierarchyID, са следните:
- GetRoot – статичният метод, който връща корена на дървото.
- GetDescendant – връща дъщерен възел на родител.
- GetAncestor – връща идентификатор на йерархия, представляващ n-тия предшественик на даден възел.
- GetLevel – връща цяло число, което представлява дълбочината на възела.
- ToString – връща низа с логическото представяне на възел. ToString се извиква имплицитно, когато се осъществи преобразуването от йерархия в типа низ.
- GetReparentedValue – премества възел от стария родител към новия родител.
- Разбиране – действа като противоположност на ToString . Той преобразува изгледа на низове на йерархичен идентификатор стойност в шестнадесетична.
Стратегии за индексиране на Йерархия на SQL сървър
За да гарантирате, че заявките за таблици, използващи hierarchyID, се изпълняват възможно най-бързо, трябва да индексирате колоната. Има две стратегии за индексиране:
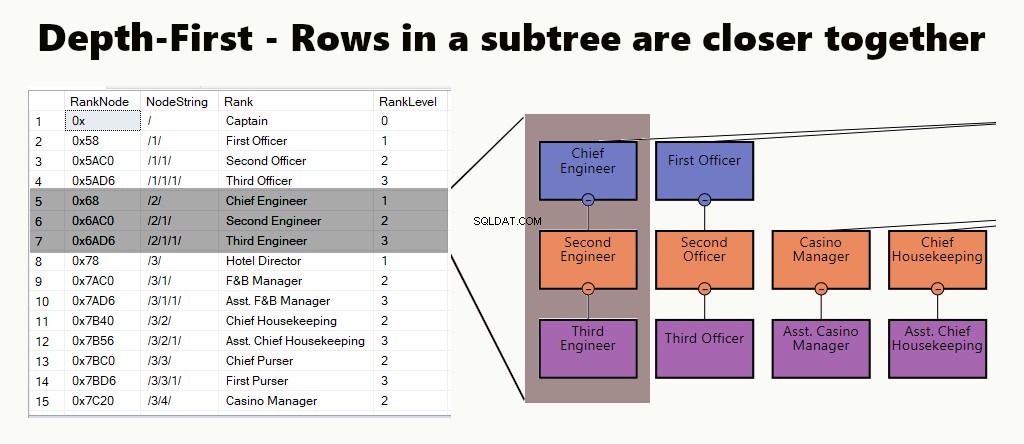
ДЪЛБОЧИНА-ПЪРВО
При индекс на първо място в дълбочина редовете на поддървото са по-близо един до друг. Подхожда на заявки като намиране на отдел, неговите подразделения и служители. Друг пример е мениджър и неговите служители, съхранявани по-близо един до друг.
В таблица можете да приложите индекс на първо място в дълбочина, като създадете клъстериран индекс за възлите. Освен това изпълняваме един от нашите примери, точно така.
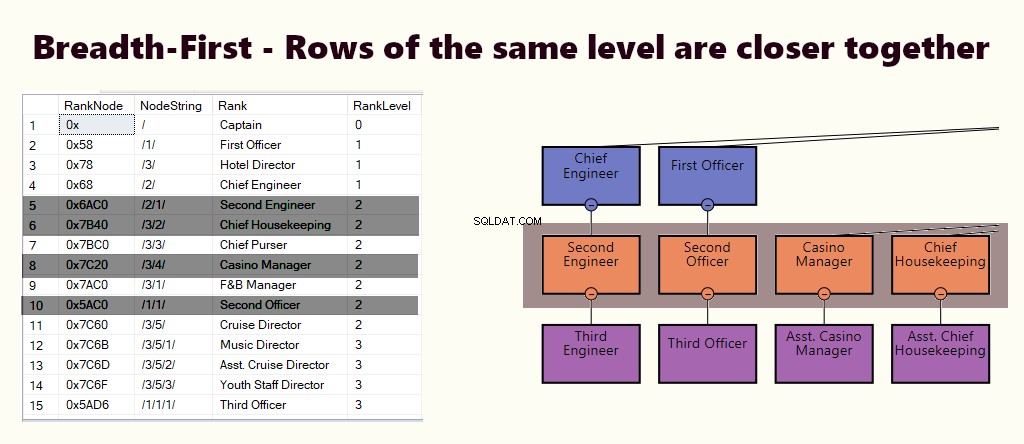
ПЪРВО В ШИРИНА
В индекса на първо място, редовете на едно и също ниво са по-близо един до друг. Подхожда на заявки като намиране на всички служители на мениджъра, които пряко подчиняват. Ако повечето от заявките са подобни на това, създайте клъстериран индекс въз основа на (1) ниво и (2) възел.
Зависи от вашите изисквания дали имате нужда от индекс на първо място в дълбочина, първо в ширина или и двете. Трябва да балансирате между важността на типа на заявките и DML изразите, които изпълнявате в таблицата.
Ограничения на идентификатора на йерархията на SQL сървър
За съжаление, използването на hierarchyID не може да разреши всички проблеми:
- SQL сървърът не може да познае какво е детето на родител. Трябва да дефинирате дървото в таблицата.
- Ако не използвате уникално ограничение, генерираната стойност на hierarchyID няма да е уникална. Справянето с този проблем е отговорност на разработчика.
- Връзките на родителски и дъщерни възли не се прилагат като връзка с външен ключ. Следователно, преди да изтриете възел, потърсете всички съществуващи наследници.
Визуализация на йерархии
Преди да продължим, помислете за още един въпрос. Разглеждайки резултантния набор с низове на възли, намирате ли, че йерархията се визуализира трудна за очите ви?
За мен това е голямо „да“, защото не ставам по-млад.
Поради тази причина ще използваме Power BI и йерархичната диаграма от Akvelon заедно с нашите таблици на база данни. Те ще помогнат да се покаже йерархията в организационна схема. Надявам се, че ще улесни работата.
Сега да се заемем с работата.
Използване на идентификатор на йерархия на SQL Server
Можете да използвате HierarchyID със следните бизнес сценарии:
- Организационна структура
- Папки, подпапки и файлове
- Задачи и подзадачи в проект
- Страници и подстраници на уебсайт
- Географски данни с държави, региони и градове
Дори ако вашият бизнес сценарий е подобен на горния и рядко правите заявки в секциите на йерархията, нямате нужда от hierarchyID.
Например вашата организация обработва ведомости за заплати за служители. Имате ли нужда от достъп до поддървото, за да обработите нечия заплата? Въобще не. Въпреки това, ако обработвате комисионни от хора в многостепенна маркетингова система, може да е различно.
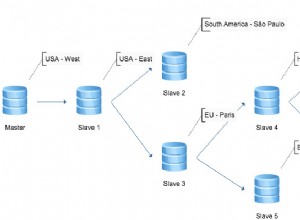
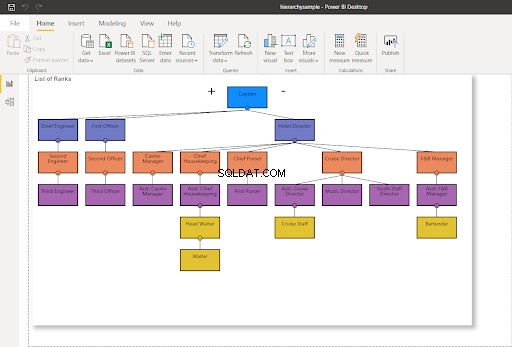
В тази публикация използваме частта от организационната структура и командната верига на круизен кораб. Структурата е адаптирана от организационната схема от тук. Разгледайте го на фигура 4 по-долу:

Сега можете да визуализирате въпросната йерархия. В тази публикация използваме таблиците по-долу:
- Корабове – е таблицата за списъка на круизните кораби.
- Рангове – е таблицата с ранговете на екипажа. Там установяваме йерархии, използвайки идентификатора на йерархията.
- Екипаж – е списъкът на екипажа на всеки кораб и техните звания.
Структурата на таблицата на всеки случай е както следва:
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GOВмъкване на данни от таблица с идентификатор на йерархия на SQL Server
Първата задача при пълното използване на hierarchyID е да добавите записи в таблицата сhierarchyID колона. Има два начина да го направите.
Използване на низове
Най-бързият начин за вмъкване на данни с ierarchyID е да използвате низове. За да видите това в действие, нека добавим някои записи към Ранговете таблица.
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Captain', '/',0)
,('First Officer','/1/',1)
,('Chief Engineer','/2/',1)
,('Hotel Director','/3/',1)
,('Second Officer','/1/1/',2)
,('Second Engineer','/2/1/',2)
,('F&B Manager','/3/1/',2)
,('Chief Housekeeping','/3/2/',2)
,('Chief Purser','/3/3/',2)
,('Casino Manager','/3/4/',2)
,('Cruise Director','/3/5/',2)
,('Third Officer','/1/1/1/',3)
,('Third Engineer','/2/1/1/',3)
,('Asst. F&B Manager','/3/1/1/',3)
,('Asst. Chief Housekeeping','/3/2/1/',3)
,('First Purser','/3/3/1/',3)
,('Asst. Casino Manager','/3/4/1/',3)
,('Music Director','/3/5/1/',3)
,('Asst. Cruise Director','/3/5/2/',3)
,('Youth Staff Director','/3/5/3/',3)Горният код добавя 20 записа към таблицата с ранговете.
Както можете да видите, дървовидната структура е дефинирана в INSERT изявление по-горе. Лесно се забелязва, когато използваме низове. Освен това SQL Server го преобразува в съответните шестнадесетични стойности.
Използване на Max(), GetAncestor() и GetDescendant()
Използването на низове отговаря на задачата за попълване на първоначалните данни. В дългосрочен план имате нужда от кода, за да управлявате вмъкването, без да предоставяте низове.
За да изпълните тази задача, вземете последния възел, използван от родител или предшественик. Постигаме го с помощта на функциите MAX() и GetAncestor() . Вижте примерния код по-долу:
-- add a bartender rank reporting to the Asst. F&B Manager
DECLARE @MaxNode HIERARCHYID
DECLARE @ImmediateSuperior HIERARCHYID = 0x7AD6
SELECT @MaxNode = MAX(RankNode) FROM dbo.Ranks r
WHERE r.RankNode.GetAncestor(1) = @ImmediateSuperior
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Bartender', @ImmediateSuperior.GetDescendant(@MaxNode,NULL),
@ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel())По-долу са точките, взети от горния код:
- Първо, имате нужда от променлива за последния възел и непосредствено началник.
- Последният възел може да бъде получен с помощта на MAX() срещу RankNode за посочения родител или пряк началник. В нашия случай това е асистентът F&B мениджър със стойност на възел 0x7AD6.
- След това, за да сте сигурни, че няма да се появи дублирано дъще, използвайте @ImmediateSuperior.GetDescendant(@MaxNode, NULL) . Стойността в @MaxNode е последното дете. Ако не е NULL , GetDescendant() връща следващата възможна стойност на възел.
- Накрая, GetLevel() връща нивото на създадения нов възел.
Запитване на данни
След като добавим записи към нашата таблица, е време да я запитаме. Налични са 2 начина за запитване на данни:
Заявката за преки потомци
Когато търсим служителите, които се отчитат директно на мениджъра, трябва да знаем две неща:
- Стойността на възела на мениджъра или родителя
- Нивото на служителя под мениджър
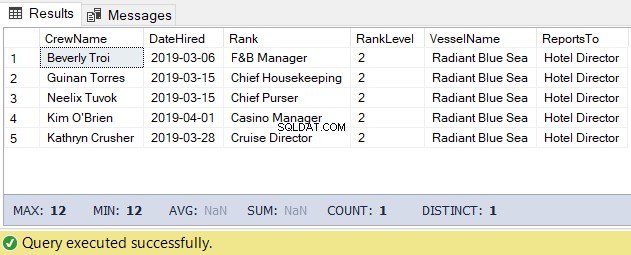
За тази задача можем да използваме кода по-долу. Резултатът е списъкът на екипажа под директора на хотела.
-- Get the list of crew directly reporting to the Hotel Director
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
DECLARE @Level SMALLINT = @Node.GetLevel()
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1
AND b.RankLevel = @Level + 1 -- add 1 for the level of the crew under the
-- Hotel DirectorРезултатът от горния код е както следва на фигура 5:
Заявка за поддървета
Понякога трябва също да изброите децата и децата на децата до дъното. За да направите това, трябва да имате идентификатора на йерархията на родителя.
Заявката ще бъде подобна на предишния код, но без да е необходимо да се получава нивото. Вижте примера с код:
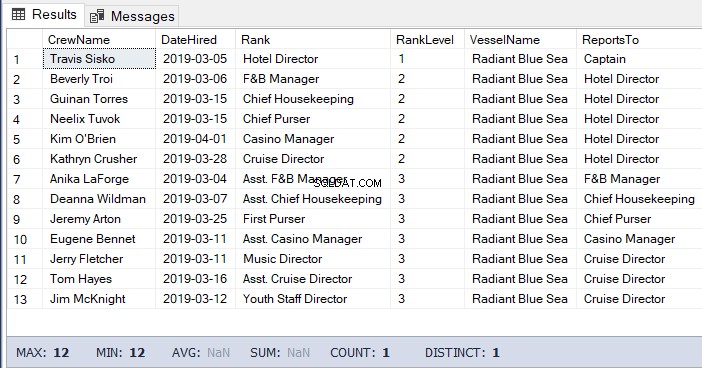
-- Get the list of the crew under the Hotel Director down to the lowest level
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1Резултатът от горния код:
Преместване на възли с идентификатор на йерархия на SQL Server
Друга стандартна операция с йерархични данни е преместването на дете или цяло поддърво към друг родител. Въпреки това, преди да продължим, моля, обърнете внимание на един потенциален проблем:
Потенциален проблем
- Първо, движещите се възли включват I/O. Колко често местите възли може да бъде решаващ фактор, ако използвате идентификатор на йерархия или обичайния родител/дете.
- Второ, преместването на възел в родителски/дъщерен дизайн актуализира един ред. В същото време, когато преместите възел с ierarchyID, той актуализира един или повече редове. Броят на засегнатите редове зависи от дълбочината на нивото на йерархия. Това може да се превърне в значителен проблем с производителността.
Решение
Можете да се справите с този проблем с дизайна на вашата база данни.
Нека разгледаме дизайна, който използвахме тук.
Вместо да дефинирате йерархията наЕкипаж таблица, ние я дефинирахме вРангове маса. Този подход се различава от Служителя таблица в AdventureWorks примерна база данни и предлага следните предимства:
- Членовете на екипажа се движат по-често от редиците на кораб. Този дизайн ще намали движенията на възлите в йерархията. В резултат на това минимизира проблема, дефиниран по-горе.
- Дефиниране на повече от една йерархия в Екипаж таблицата е по-сложна, тъй като два кораба се нуждаят от двама капитани. Резултатът е два коренни възела.
- Ако трябва да покажете всички звания със съответния член на екипажа, можете да използвате ЛЯВО ПРИСЪЕДИНЕНИЕ. Ако никой не е на борда за този ранг, той показва празно място за позицията.
Сега нека да преминем към целта на този раздел. Добавете дъщерни възли под грешните родители.
За да си представите какво ще правим, представете си йерархия като тази по-долу. Обърнете внимание на жълтите възли.

Преместване на възел без деца
Преместването на дъщерен възел изисква следното:
- Дефинирайте идентификатора на йерархията на дъщерния възел, който да преместите.
- Дефинирайте идентификатора на йерархията на стария родител.
- Дефинирайте идентификатора на йерархията на новия родител.
- Използвайте АКТУАЛИЗИРАНЕ с GetReparentedValue() за да преместите възела физически.
Започнете с преместване на възел без деца. В примера по-долу преместваме персонала на круиза от директора на круиза към асистент. Директор на круиза.
-- Moving a node with no child node
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 24 -- the cruise staff
SELECT @OldParent = @NodeToMove.GetAncestor(1)
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 19 -- the assistant cruise director
UPDATE dbo.Ranks
SET RankNode = @NodeToMove.GetReparentedValue(@OldParent,@NewParent)
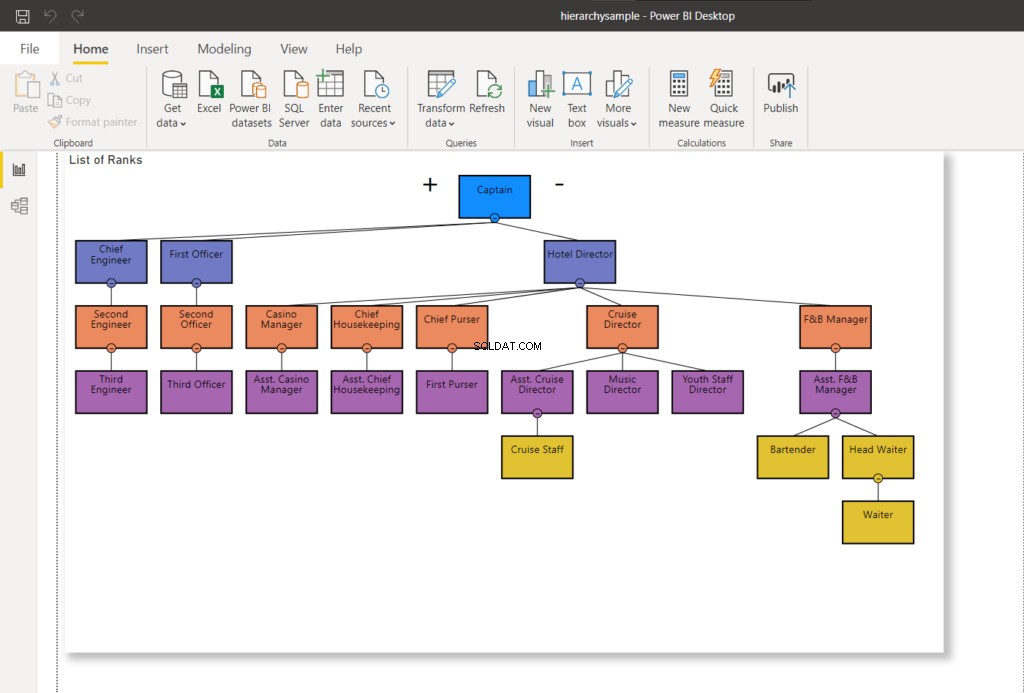
WHERE RankNode = @NodeToMoveСлед като възелът се актуализира, за него ще се използва нова шестнадесетична стойност. Обновяване на моята Power BI връзка към SQL Server – това ще промени йерархичната диаграма, както е показано по-долу:
На фигура 8 персоналът на круиза вече не се отчита на директора на круиза – той е променен, за да докладва на помощник директора на круиза. Сравнете го с фигура 7 по-горе.
Сега нека да преминем към следващия етап и да преместим главния сервитьор към асистент мениджъра за хранене и заведения.
Преместване на възел с деца
В тази част има предизвикателство.
Работата е там, че предишният код няма да работи с възел дори с едно дете. Не забравяйте, че преместването на възел изисква актуализиране на един или повече дъщерни възли.
Освен това не свършва дотук. Ако новият родител има съществуващо дете, може да се сблъскаме с дублиращи се стойности на възел.
В този пример трябва да се сблъскаме с този проблем:ас. Мениджърът на F&B има дъщерен възел Bartender.
Готов? Ето кода:
-- Move a node with at least one child
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- the head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- head waiter's old parent
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- the assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- ensure
--to get a new id in case there's a
--sibling
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error <> 0 GOTO START -- On error, retry
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
DEALLOCATE children_cursor;В горния пример с код итерацията започва като необходимост от прехвърляне на възела надолу към детето на последното ниво.
След като го стартирате, вранга таблицата ще бъде актуализирана. И отново, ако искате да видите промените визуално, опреснете отчета на Power BI. Ще видите промените, подобни на тази по-долу:
Предимства от използването на SQL Server HierarchyID спрямо родител/дете
За да убедим някого да използва функция, трябва да знаем предимствата.
По този начин в този раздел ще сравним изрази, използвайки същите таблици като тези от началото. Единият ще използва hierarchyID, а другият ще използва подхода родител/дете. Резултатът ще бъде еднакъв и за двата подхода. Очакваме го за това упражнение като това от Фигура 6 по-горе.
Сега, когато изискванията са точни, нека разгледаме обстойно ползите.
По-лесно за кодиране
Вижте кода по-долу:
-- List down all the crew under the Hotel Director using hierarchyID
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.RANK AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON d.RankNode = b.RankNode.GetAncestor(1)
WHERE a.VesselId = 1
AND b.RankNode.IsDescendantOf(0x78)=1Тази извадка се нуждае само от стойност на hierarchyID. Можете да промените стойността по желание, без да променяте заявката.
Сега сравнете изявлението за подхода родител/дете, което води до същия набор от резултати:
-- List down all the crew under the Hotel Director using parent/child
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.Rank AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON b.RankParentId = d.RankId
WHERE a.VesselId = 1
AND (b.RankID = 4) OR (b.RankParentID = 4 OR b.RankParentId >= 7)Какво мислиш? Пробните кодове са почти еднакви, с изключение на една точка.
КЪДЕ Клаузата във втората заявка няма да бъде гъвкава за адаптиране, ако се изисква различно поддърво.
Направете втората заявка достатъчно обща и кодът ще бъде по-дълъг. Браво!
По-бързо изпълнение
Според Microsoft „заявките за поддървото са значително по-бързи с йерархия“ в сравнение с родител/дете. Да видим дали е вярно.
Използваме същите заявки, както по-рано. Един важен показател, който трябва да се използва за производителност, е логическите показания от ЗАДАВАНЕ НА СТАТИСТИКА IO . Той казва колко страници от 8KB ще са необходими на SQL Server, за да получи желания набор от резултати. Колкото по-висока е стойността, толкова по-голям е броят на страниците, които SQL Server има достъп и чете, и толкова по-бавно се изпълнява заявката. Изпълнете SET STATISTICS IO ON и изпълнете отново двете заявки по-горе. По-ниската стойност на логическите показания ще бъде победител.
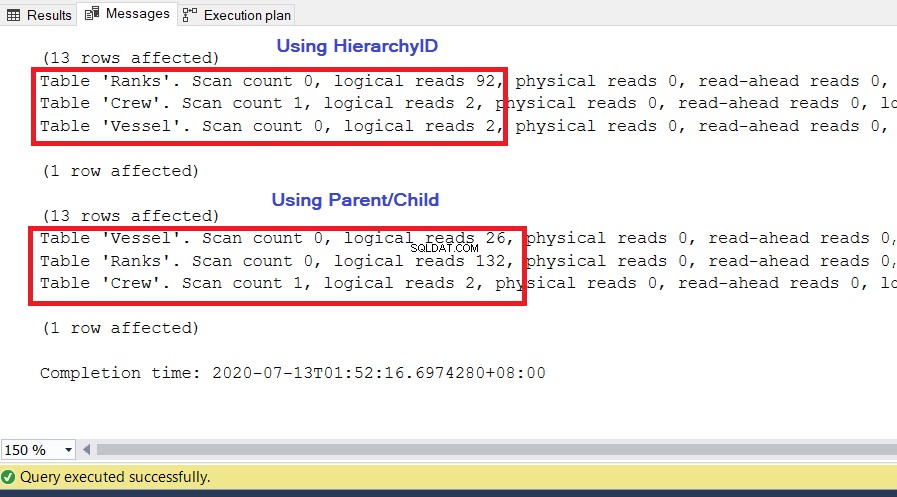
АНАЛИЗ
Както можете да видите на Фигура 10, I/O статистическите данни за заявката с hierarchyID имат по-ниски логически показания от техните родителски/дъщерни колеги. Обърнете внимание на следните точки в този резултат:
- Корабът таблицата е най-забележителната от трите таблици. Използването на hierarchyID изисква само 2 * 8KB =16KB страници, които да бъдат прочетени от SQL Server от кеша (паметта). Междувременно използването на родител/дете изисква 26 * 8KB =208KB страници – значително по-високо от използването на йерархичен идентификатор.
- Ранговете таблица, която включва нашата дефиниция за йерархии, изисква 92 * 8KB =736KB. От друга страна, използването на родител/дете изисква 132 * 8KB =1056KB.
- Екипаж таблицата се нуждае от 2 * 8KB =16KB, което е същото и за двата подхода.
Килобайтовете страници може да са малка стойност засега, но имаме само няколко записа. Това обаче ни дава представа за това колко облагане ще бъде нашата заявка на всеки сървър. За да подобрите производителността, можете да направите едно или повече от следните действия:
- Добавете подходящ(и) индекс(и)
- Преструктурирайте заявката
- Актуализиране на статистическите данни
Ако сте направили горното и логическите показания намалеят без добавяне на повече записи, производителността ще се увеличи. Докато направите логическите показания по-ниски, отколкото за този, използващ hierarchyID, това ще бъде добра новина.
Но защо се позовава на логически четения вместо на изминало време?
Проверка на изминалото време и за двете заявки чрез ЗАДАВАНЕ НА ВРЕМЕТО НА СТАТИСТИКАТА ON разкрива малък брой милисекунди разлики за нашия малък набор от данни. Освен това вашият сървър за разработка може да има различна хардуерна конфигурация, настройки на SQL Server и работно натоварване. Изминало време по-малко от милисекунда може да ви заблуди, ако заявката ви работи толкова бързо, колкото очаквате или не.
КОПАЕМ ПО-ДОБЪЧЕ
ВКЛЮЧВАНЕ НА СТАТИСТИКАТА IO не разкрива нещата, които се случват „зад кулисите“. В този раздел ще разберем защо SQL Server пристига с тези числа, като разгледаме плана за изпълнение.
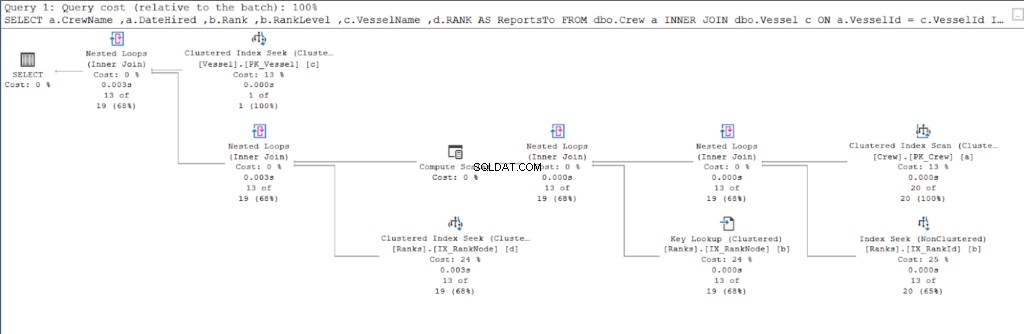
Нека започнем с плана за изпълнение на първата заявка.
Сега вижте плана за изпълнение на втората заявка.
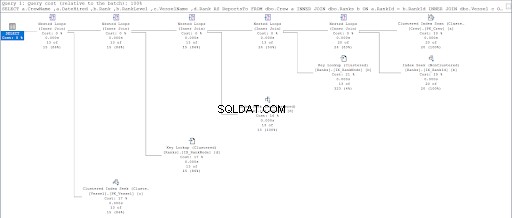
Сравнявайки фигури 11 и 12, виждаме, че SQL Server се нуждае от допълнителни усилия, за да произведе набора от резултати, ако използвате подхода родител/дете. КЪДЕ клауза е отговорна за това усложнение.
Въпреки това, грешката може да е и в дизайна на масата. Използвахме една и съща таблица и за двата подхода:Ранговете маса. Така че се опитах да дублирам Ранговете таблица, но използват различни клъстерирани индекси, подходящи за всяка процедура.
В резултат на това, използването на hierarchyID все още имаше по-малко логически четения в сравнение с партньора родител/дете. Накрая доказахме, че Microsoft е бил прав, като го твърди.
Заключение
Тук централният aha момент за hierarchyID са:
- HierarchyID е вграден тип данни, предназначен за по-оптимизирано представяне на дървета, които са най-често срещаният тип йерархични данни.
- Всеки елемент в дървото е възел и стойностите на hierarchyID могат да бъдат в шестнадесетичен или низов формат.
- HierarchyID е приложим за данни от организационни структури, проектни задачи, географски данни и други подобни.
- Има методи за преминаване и манипулиране на йерархични данни, като GetAncestor (), GetDescendant (). GetLevel (), GetReparentedValue () и още.
- Конвенционалният начин за запитване на йерархични данни е да се получат преките потомци на възел или поддърветата под възел.
- Използването на hierarchyID за запитване на поддървета не само е по-лесно за кодиране. Освен това се представя по-добре от родител/дете.
Дизайнът на родител/дете изобщо не е лош и тази публикация не е за да го омаловажи. Въпреки това, разширяването на опциите и въвеждането на нови идеи винаги е голяма полза за разработчика.
Можете сами да опитате примерите, които предложихме тук. Получете ефектите и вижте как можете да го приложите за следващия си проект, включващ йерархии.
Ако харесвате публикацията и нейните идеи, можете да разпространите думата, като щракнете върху бутоните за споделяне за предпочитаните социални медии.