Въведение
В тази статия ще говорим за използването на nvarchar тип данни. Ще проучим как SQL Server съхранява този тип данни на диска и как се обработва в RAM паметта. Ще разгледаме също как размерът на nvarchar може да повлияе на производителността.
Действителен размер на данните:nchar срещу nvarchar
Използваме nvarchar когато размерът на въведените данни в колона вероятно ще варира значително. Размерът на паметта (в байтове) е два пъти по-голям от действителната дължина на въведените данни + 2 байта. Това ни позволява да спестим съхранение на диск в сравнение с използването на nchar тип данни. Нека разгледаме следния пример. Създаваме две таблици. Една таблица съдържа колона nvarchar, друга таблица съдържа колони nchar. Размерът на колоната е 2000 знака (4000 байта).
CREATE TABLE dbo.testnvarchar (
col1 NVARCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnvarchar (col1)
SELECT
REPLICATE('&', 10)
GO
CREATE TABLE dbo.testnchar (
col1 NCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnchar (col1)
SELECT
REPLICATE('&', 10)
GO
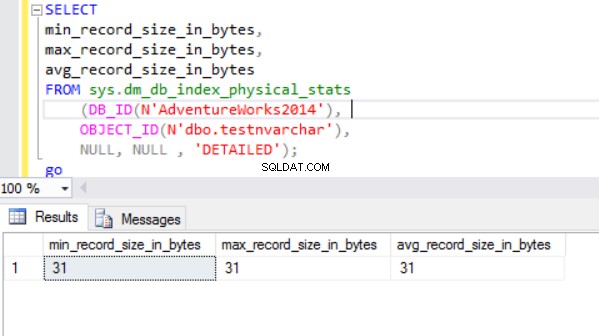
Действителният размер на реда е:
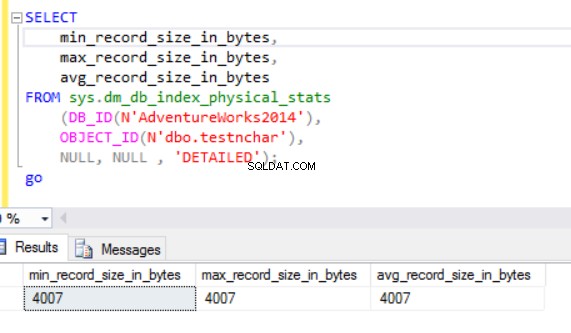
Както виждаме, действителният размер на реда на типа данни nvarchar е много по-малък от този на nchar. В случая на типа данни nchar, ние използваме ~4000 байта за съхраняване на низ от 10 символа. Използваме ~20 байта, за да съхраняваме един и същ символен низ в случай на типа данни nvarchar.
Двигателят на SQL Server обработва данни в RAM (буферен пул). Какво ще кажете за размера на реда в паметта?
Действителен размер на данните:HDD срещу RAM
Нека изпълним следната заявка:
SELECT col1 FROM dbo.testnchar;

Няма разлика между използването на диск и RAM в случай на символен низ с фиксирана дължина.
SELECT col1 FROM dbo.testnvarchar;

Можем да видим, че SQL Server Engine е поискал паметта само за половината от декларирания размер на реда (2000 байта вместо действителните 20 байта) и няколко байта за допълнителна информация. От една страна намаляваме използването на дисково пространство, но от друга можем да надуем исканата RAM памет. Това е страничен ефект от използването на различни типове данни за знаци. Този страничен ефект може силно да повлияе на ресурсите в някои случаи.
FORMAT():Заявена RAM спрямо използвана RAM
Използваме функцията FORMAT, която връща форматирана стойност с посочения формат и незадължителна култура. Връщаната стойност е nvarchar или нула. Дължината на връщаната стойност се определя от формата . FORMAT(getdate(), ‘yyyyMMdd’,’en-US’) ще доведе до ‘20170412’. Нуждаем се от 16 байта, за да съхраняваме този резултат в колоната на диска (резултатът ще бъде nvarchar(8)). Какъв е размерът на данните в RAM за конкретните данни?
Нека изпълним следната заявка. Използваме следната среда:
- AdventureWorks2014
- Издание за разработка на MS SQL 2016
- dbo.Customer (19'820'000 записа) съдържа данни от Sales.Customer (19'820 записа са били качени 1000 пъти)):
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,FORMAT([modifieddate], 'yyyyMMdd', 'en-US') AS md
,' ' AS code INTO #tmp
FROM rs
Планът за изпълнение на заявката е доста прост:

Първата операция е “Clustered index scan” в таблицата dbo.Customer. Прочетени са ~19 000 000 записа. Прогнозният размер на данните е 435 Mb.
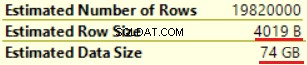
Следващата операция е „Изчисли скаларен“ (изчисляване на функцията FORMAT()). Резултатът е доста неочакван, тъй като форматираме низ от 16 байта. Размерът на реда се увеличи драстично от 23 байта на 4019 байта. Същото е и с приблизителния размер на данните — от 435 MB до 74 GB. Можем да видим, че FORMAT() връща NVARCHAR(4000).
MS SQL Server 2016 има страхотната способност да показва прекомерно предоставяне на памет. Можем да видим предупреждението в последната операция (T-SQL SELECT INTO):
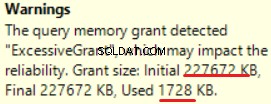
Това е „преразпределено“ на паметта:повече от 90% от предоставената памет не се използва.
Статистиката за времето на заявка е:
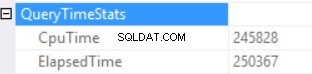
Дългото време за изпълнение зависи от неефективно изпълнение на скаларна функция и обратния страничен ефект на прекомерна памет – съвпадение на хеш (дясно външно присъединяване). Имаме кумулативен ефект от две различни причини:изпълнение на множество скаларни функции и прекомерно предоставяне на памет.
Машината на SQL Server може да предостави не повече от 25% от разрешената памет на заявка. Можем да променим тази сума в корпоративното издание на MS SQL Server с помощта на управителя на ресурсите. Предоставената памет се състои от две части:задължителна и допълнителна. Необходима памет се използва за вътрешни нужди – за операции за сортиране и хеш присъединяване. Допълнителната памет се базира на приблизителния размер на данните. Ако както необходимата, така и допълнителната памет надхвърлят границата от 25%, SQL Server двигателят предоставя още 25% от наличната памет. Прочетете публикацията за предоставяне на памет на SQL Server за подробности.
Нека изпълним същата заявка без функцията FORMAT().
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,' ' AS code INTO #tmp
FROM rs
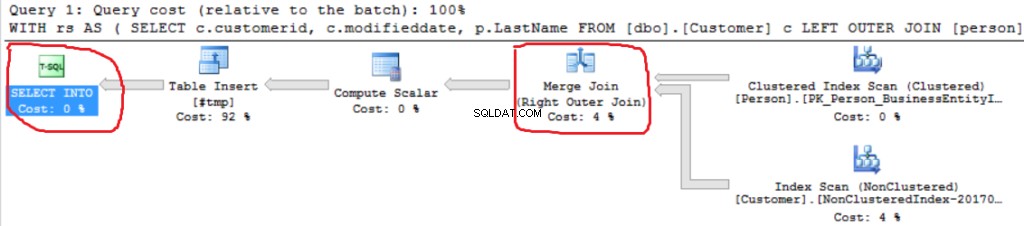
Можем да видим друга реализация на Right Outer Join (Merge Join вместо Hash Join).
Информацията за предоставяне на памет е (ако няма сортиране и хеш присъединяване на SQL Server не може да предостави памет):
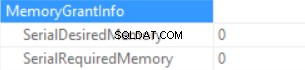
Статистиката за времето на заявка е (времето намалява предвидимо:няма изпълнение на скаларна функция, приблизителният размер на данните е по-малък, отколкото в предишната извадка):

Така че ние увеличаваме „предоставената памет“ до 222 MB (и използваме по-малко от 2 MB от нея) с помощта на функцията FORMAT(). Обемът на данните в примера е малък.
Заявка за продължително изпълнение
Помислете за истинската SQL заявка от производствена среда. Тази заявка е изпълнена по време на процес на пакетно зареждане (не е класически транзакционен сценарий). Ние използваме MS SQL Server, стартиран на Amazon Web Services (AWS, Amazon Relational Database Service). Характеристиките на DB екземпляр са 160 GB RAM (на заявка могат да бъдат предоставени не повече от ~30 GB RAM) и 40 vCPU. SQL заявката беше почти същата като примера по-горе (разликата е в количеството таблици и размера на данните):CTE включва присъединяване между 6 таблици. „Главната таблица“ (таблица в клаузата FROM) съдържа ~175 000 000 записа и размерът на данните е 20 GB. Таблиците за търсене (дясната таблица в клаузата JOIN) са малки (в сравнение с основната таблица). SQL заявката съдържа две извиквания на функцията FORMAT() (две колони от таблицата „главна таблица“ са параметърът на тази функция).
Заявката за производство изглежда така:
;WITH rs AS ( SELECT <in column list>, c.modifieddate, c.createddate FROM [Master table] c LEFT OUTER JOIN [table1 ] p1 ON … LEFT OUTER JOIN [table2 ] p2 ON … LEFT OUTER JOIN [table3 ] p3 ON … LEFT OUTER JOIN [table4 ] p4 ON … LEFT OUTER JOIN [table5 ] p5 ON … ) SELECT DISTINT <out column list>, FORMAT([modifieddate], 'yyyyMMdd','en-US') AS md, FORMAT([createddate], 'yyyyMMdd','en-US') AS cd INTO #tmp FROM rs
„Картината“ на плана за изпълнение е по-долу (планът за изпълнение е прост:последователни обединявания и сортиране (различни ключови думи) в горната част):

Нека разгледаме подробно информацията.
Първата операция е „Сканиране на таблицата“ (всичко е правилно, без изненади):

Операцията „Скаларно изчисление“ увеличава драстично оценения размер на ред, както и приблизителния размер на реда (от 19 GB до 1,3 TB). Две извиквания на функцията FORMAT() добавиха около 8000 байта към приблизителния размер на реда (но действителният размер на данните е по-малък).

Една от операциите JOIN (Hash Match, Right Outer Join) използва неуникални колони от дясната таблица. Няма значение в случай на няколко записа. Това не е нашият случай. В резултат на това прогнозният размер на данните се увеличава до ~2,4TB.

Има и предупреждение (няма достатъчно RAM за обработка на тази операция):
SQL заявката съдържа операция „Distinct Sort“ в горната част, която изглежда като череша на върха на торта. Там можем да видим същото предупреждение.
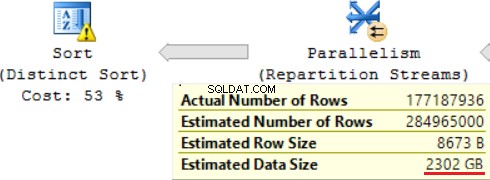
Резултатът от използването на скаларна функция е дълго време за изпълнение на заявката:24 часа. Една от причините за този проблем е неправилна оценка на искания размер на данни въз основа на „Прогнозен размер на данните“. Без да използва функцията FORMAT(), MS SQL Server изпълнява тази заявка за 2 часа.
Заключение
Разработчиците трябва да бъдат внимателни, когато използват типове данни nvarchar и varchar. Избирането на излишни типове данни за колони може да доведе до надуване на необходимата памет. В резултат на това RAM паметта ще бъде разхищена, производителността на базата данни ще бъде влошена.