Исках да се присъединя към опцията за решаване на вашата задача с чист BigQuery (стандартен SQL)
Предварителни условия/предположения :изходните данни са в sandbox.temp.id1_id2_pairs
Трябва да замените това със свой собствен или ако искате да тествате с фиктивни данни от въпроса си - можете да създадете тази таблица, както е по-долу (разбира се заменете sandbox.temp с вашия собствен project.dataset )
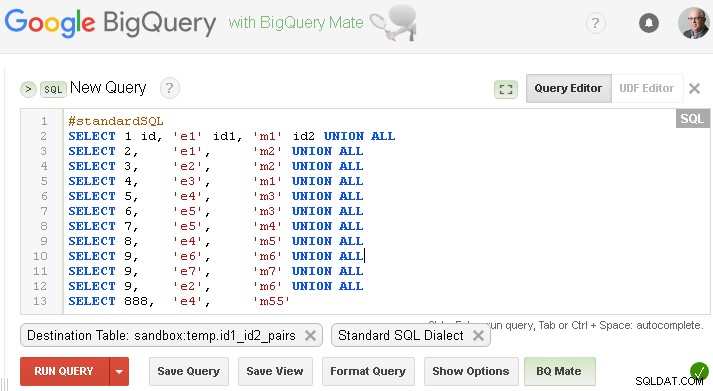
Уверете се, че сте задали съответната таблица на местоназначението
Забележка :можете да намерите всички съответни Запитвания (като текст) в долната част на този отговор, но засега илюстрирам отговора си с екранни снимки - така че всичко е представено - заявка, резултат и използвани опции
И така, ще има три стъпки:
Стъпка 1 - Инициализация
Тук просто правим първоначално групиране на id1 въз основа на връзки с id2:
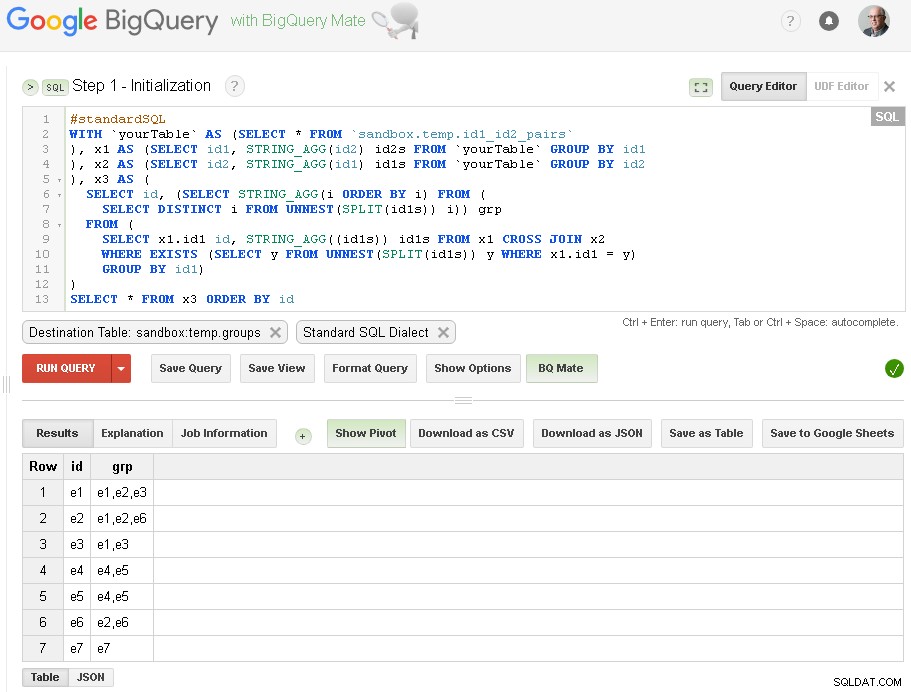
Както можете да видите тук - създадохме списък с всички стойности на id1 със съответните връзки на базата на проста връзка на едно ниво през id2
Изходната таблица е sandbox.temp.groups
Стъпка 2 - Групиране на итерации
Във всяка итерация ще обогатяваме групирането въз основа на вече създадени групи.
Източникът на заявката е изходната таблица от предишната стъпка (sandbox.temp.groups ) и Дестинация е една и съща таблица (sandbox.temp.groups ) с презаписване
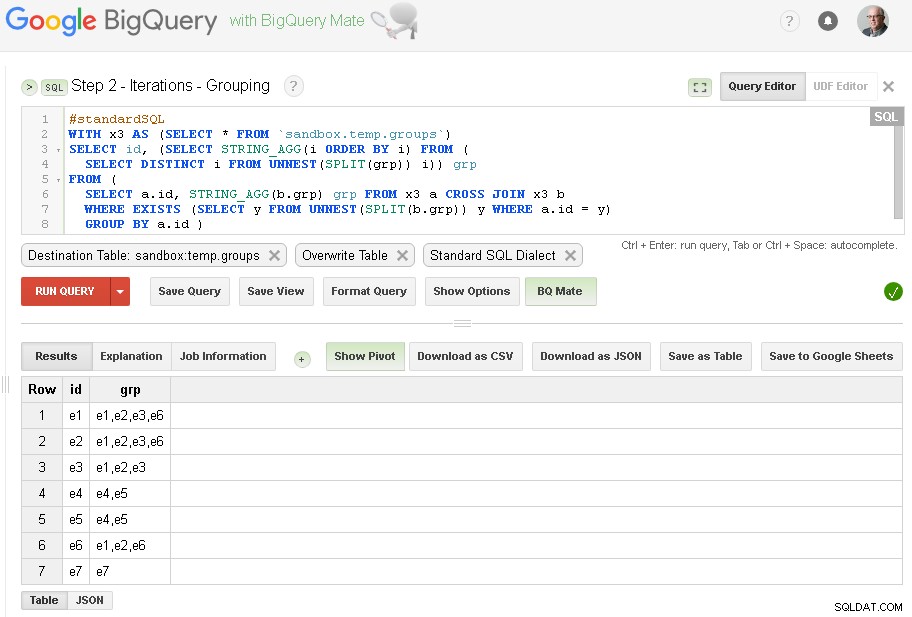
Ще продължим итерациите, докато броят на намерените групи ще бъде същият като в предишната итерация
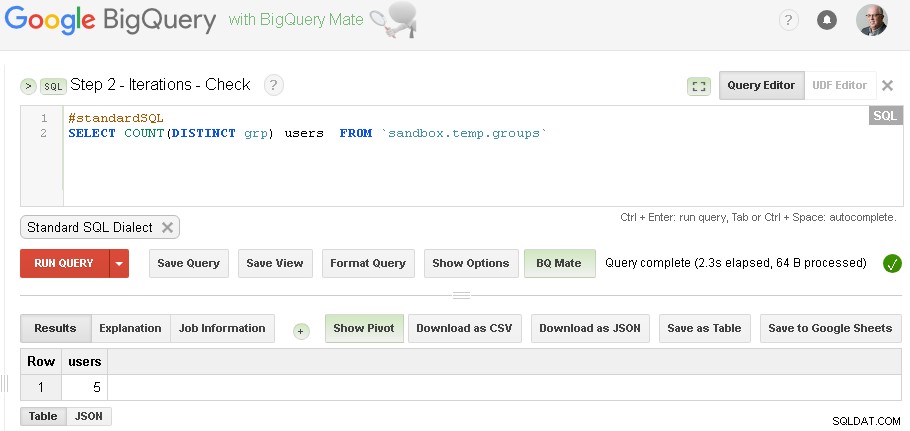
Забележка :можете просто да отворите два раздела на BigQuery Web UI (както е показано по-горе) и без да променяте кода, просто стартирайте Grouping и след това Проверете отново и отново, докато итерацията се сближи
(за конкретни данни, които използвах в раздела с предварителни изисквания - имах три итерации - първата итерация произведе 5 потребители, втората итерация произведе 3 потребители и третата итерация произведе отново 3 потребители - което показва, че сме свършили с итерациите.
Разбира се, в реалния живот - броят на повторенията може да бъде повече от три - така че имаме нужда от някаква автоматизация (вижте съответния раздел в долната част на отговора).
Стъпка 3 – Окончателно групиране
Когато групирането на id1 приключи - можем да добавим окончателно групиране за id2
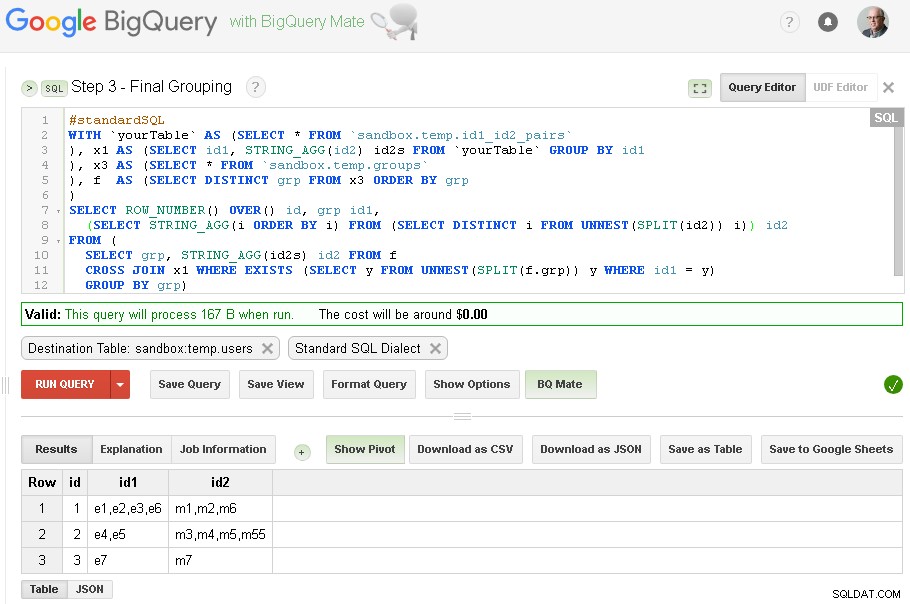
Крайният резултат сега е в sandbox.temp.users таблица
Използвани заявки (не забравяйте да зададете съответните таблици дестинации и да презапишете, когато е необходимо, съгласно описаната по-горе логика и екранни снимки):
Предварителни изисквания:
#standardSQL
SELECT 1 id, 'e1' id1, 'm1' id2 UNION ALL
SELECT 2, 'e1', 'm2' UNION ALL
SELECT 3, 'e2', 'm2' UNION ALL
SELECT 4, 'e3', 'm1' UNION ALL
SELECT 5, 'e4', 'm3' UNION ALL
SELECT 6, 'e5', 'm3' UNION ALL
SELECT 7, 'e5', 'm4' UNION ALL
SELECT 8, 'e4', 'm5' UNION ALL
SELECT 9, 'e6', 'm6' UNION ALL
SELECT 9, 'e7', 'm7' UNION ALL
SELECT 9, 'e2', 'm6' UNION ALL
SELECT 888, 'e4', 'm55'
Стъпка 1
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x2 AS (SELECT id2, STRING_AGG(id1) id1s FROM `yourTable` GROUP BY id2
), x3 AS (
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp
FROM (
SELECT x1.id1 id, STRING_AGG((id1s)) id1s FROM x1 CROSS JOIN x2
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(id1s)) y WHERE x1.id1 = y)
GROUP BY id1)
)
SELECT * FROM x3
Стъпка 2 - Групиране
#standardSQL
WITH x3 AS (select * from `sandbox.temp.groups`)
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grp
FROM (
SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id = y)
GROUP BY a.id )
Стъпка 2 - Проверете
#standardSQL
SELECT COUNT(DISTINCT grp) users FROM `sandbox.temp.groups`
Стъпка 3
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x3 as (select * from `sandbox.temp.groups`
), f AS (SELECT DISTINCT grp FROM x3 ORDER BY grp
)
SELECT ROW_NUMBER() OVER() id, grp id1,
(SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(id2)) i)) id2
FROM (
SELECT grp, STRING_AGG(id2s) id2 FROM f
CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 = y)
GROUP BY grp)
Автоматизация :
Разбира се, горният "процес" може да се изпълни ръчно, в случай че итерациите се сближават бързо - така че ще получите 10-20 стартирания. Но в по-реални случаи можете лесно да автоматизирате това с всеки клиент
по ваш избор



