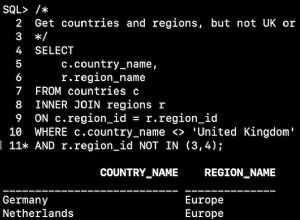
На първо място типът заявка, която извършвате, е изключително неефективна. Засега (Spark 1.5.0*), за да се извърши присъединяване по този начин, и двете таблици трябва да бъдат разбъркани / хеш-разделени всеки път, когато се изпълнява заявка. Не би трябвало да е проблем в случай на users таблица, където user_id = 123 предикатът най-вероятно е избутан надолу, но все пак изисква пълно разбъркване на user_address .
Освен това, ако таблиците са само регистрирани и не са кеширани, тогава всяко изпълнение на тази заявка ще извлече цял user_address таблица от MySQL към Spark.
Не е точно ясно защо искате да използвате Spark за приложение, но настройката на една машина, малките данни и типът заявки предполагат, че Spark не е подходящ тук.
Най-общо казано, ако логиката на приложението изисква достъп до един запис, тогава Spark SQL няма да работи добре. Той е предназначен за аналитични заявки, а не като заместител на OLTP база данни.
Ако една таблица/кадър от данни е много по-малък, можете да опитате да излъчвате.
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.functions.broadcast
val user: DataFrame = ???
val user_address: DataFrame = ???
val userFiltered = user.where(???)
user_addresses.join(
broadcast(userFiltered), $"address_id" === $"user_address_id")
* Това трябва да се промени в Spark 1.6.0 с SPARK-11410 което трябва да даде възможност за постоянно разделяне на таблицата.