Въведение
Съвсем сега вашите условия за съвпадение може да са твърде широки. Можете обаче да използвате разстоянието на левещайн, за да проверите думите си. Може да не е твърде лесно да изпълните всички желани цели с него, като звукова прилика. Затова предлагам да разделите проблема си на някои други проблеми.
Например, можете да създадете някаква персонализирана проверка, която ще използва предаден извикващ вход, който отнема два низа и след това отговаря на въпрос дали са същите (за levenshtein това ще бъде разстояние по-малко от някаква стойност за similar_text - някакъв процент сходство и т.н. - от вас зависи да дефинирате правила).
Прилика, базирана на думи
Е, всички вградени функции ще се провалят, ако говорим за случай, когато търсите частично съвпадение - особено ако става въпрос за неподредено съвпадение. По този начин ще трябва да създадете по-сложен инструмент за сравнение. Имате:
- Низ от данни (който ще бъде в DB, например). Изглежда D =D0 Г1 D2 ... Dn
- Низ за търсене (който ще бъде въведен от потребителя). Изглежда като S =S0 S1 ... Sm
Тук символите за пространство означават само всеки интервал (предполагам, че символите за интервал няма да повлияят на сходството). Също така n > m . С тази дефиниция проблемът ви е за - да намерите набор от m думи в D което ще бъде подобно на S . От set Имам предвид всяка неподредена последователност. Следователно, ако открием някаква такава последователност в D , след това S е подобен на D .
Очевидно, ако n < m тогава входът съдържа повече думи, отколкото низ от данни. В този случай може или да си помислите, че не са подобни, или да действате както по-горе, но да превключите данни и вход (това обаче изглежда малко странно, но е приложимо в известен смисъл)
Внедряване
За да направите нещата, ще трябва да можете да създадете набор от низове, които са части от m думи от D . Въз основа на моя този въпрос
можете да направите това с:
protected function nextAssoc($assoc)
{
if(false !== ($pos = strrpos($assoc, '01')))
{
$assoc[$pos] = '1';
$assoc[$pos+1] = '0';
return substr($assoc, 0, $pos+2).
str_repeat('0', substr_count(substr($assoc, $pos+2), '0')).
str_repeat('1', substr_count(substr($assoc, $pos+2), '1'));
}
return false;
}
protected function getAssoc(array $data, $count=2)
{
if(count($data)<$count)
{
return null;
}
$assoc = str_repeat('0', count($data)-$count).str_repeat('1', $count);
$result = [];
do
{
$result[]=array_intersect_key($data, array_filter(str_split($assoc)));
}
while($assoc=$this->nextAssoc($assoc));
return $result;
}
-така за всеки масив, getAssoc() ще върне масив от неподредени селекции, състоящ се от m всеки елемент.
Следващата стъпка е за реда в произведената селекция. Трябва да търсим и двете Niels Andersen и Andersen Niels в нашия D низ. Следователно ще трябва да можете да създавате пермутации за масив. Това е много често срещан проблем, но ще сложа и моята версия тук:
protected function getPermutations(array $input)
{
if(count($input)==1)
{
return [$input];
}
$result = [];
foreach($input as $key=>$element)
{
foreach($this->getPermutations(array_diff_key($input, [$key=>0])) as $subarray)
{
$result[] = array_merge([$element], $subarray);
}
}
return $result;
}
След това ще можете да създавате селекции на m думи и след това, пермутирайки всяка от тях, получавате всички варианти за сравнение с низ за търсене S . Това сравнение всеки път ще се извършва чрез обратно извикване, като levenshtein . Ето извадка:
public function checkMatch($search, callable $checker=null, array $args=[], $return=false)
{
$data = preg_split('/\s+/', strtolower($this->data), -1, PREG_SPLIT_NO_EMPTY);
$search = trim(preg_replace('/\s+/', ' ', strtolower($search)));
foreach($this->getAssoc($data, substr_count($search, ' ')+1) as $assoc)
{
foreach($this->getPermutations($assoc) as $ordered)
{
$ordered = join(' ', $ordered);
$result = call_user_func_array($checker, array_merge([$ordered, $search], $args));
if($result<=$this->distance)
{
return $return?$ordered:true;
}
}
}
return $return?null:false;
}
Това ще провери сходството въз основа на обратното извикване на потребителя, което трябва да приеме поне два параметъра (т.е. сравнени низове). Също така може да пожелаете да върнете низ, който е задействал положително връщане на обратното извикване. Моля, имайте предвид, че този код няма да се различава от главни и малки букви - но може да не искате такова поведение (след това просто заменете strtolower() ).
Пример за пълен код е наличен в този списък (Не използвах пясъчна среда, тъй като не съм сигурен колко дълго списъкът с кодове ще бъде наличен там). С тази примерна употреба:
$data = 'Niels Faurskov Andersen';
$search = [
'Niels Andersen',
'Niels Faurskov',
'Niels Faurskov Andersen',
'Nils Faurskov Andersen',
'Nils Andersen',
'niels faurskov',
'niels Faurskov',
'niffddels Faurskovffre'//I've added this crap
];
$checker = new Similarity($data, 2);
echo(sprintf('Testing "%s"'.PHP_EOL.PHP_EOL, $data));
foreach($search as $name)
{
echo(sprintf(
'Name "%s" has %s'.PHP_EOL,
$name,
($result=$checker->checkMatch($name, 'levenshtein', [], 1))
?sprintf('matched with "%s"', $result)
:'mismatched'
)
);
}
ще получите резултат като:
Testing "Niels Faurskov Andersen" Name "Niels Andersen" has matched with "niels andersen" Name "Niels Faurskov" has matched with "niels faurskov" Name "Niels Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Andersen" has matched with "niels andersen" Name "niels faurskov" has matched with "niels faurskov" Name "niels Faurskov" has matched with "niels faurskov" Name "niffddels Faurskovffre" has mismatched
-тук е демонстрация за този код, за всеки случай.
Сложност
Тъй като ви е грижа не само за каквито и да е методи, но и за - колко е добър, може да забележите, че такъв код ще доведе до доста прекомерни операции. Имам предвид поне генерирането на струнни части. Сложността тук се състои от две части:
- Част за генериране на части от низове. Ако искате да генерирате всички части на низа - ще трябва да направите това, както описах по-горе. Възможна точка за подобряване - генериране на неподредени набори от низове (които идват преди пермутацията). Но все пак се съмнявам, че може да се направи, защото методът в предоставения код ще ги генерира не с "груба сила", а така, както са математически изчислени (с мощност на
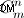 )
) - Част за проверка на сходството. Тук вашата сложност зависи от дадена проверка на сходството. Например,
similar_text()има O(N) сложност, така че при големи набори за сравнение ще бъде изключително бавен.
Но все пак можете да подобрите текущото решение с проверка в движение. Сега този код първо ще генерира всички низови подпоследователности и след това ще започне да ги проверява една по една. В общия случай не е необходимо да правите това, така че може да искате да замените това с поведение, когато след генериране на следващата последователност тя ще бъде проверена незабавно. Тогава ще увеличите производителността за низове, които имат положителен отговор (но не и за тези, които нямат съвпадение).