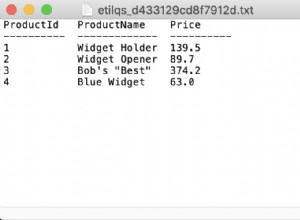
С MySQL можете да използвате FIND_IN_SET() :
SELECT * FROM mytable WHERE FIND_IN_SET('ios ', tags) > 0;
https://dev.mysql .com/doc/refman/5.0/en/string-functions.html#function_find-in-set
Обърнете внимание, че FIND_IN_SET очаква низовете да бъдат запетая разделени, а не запетая и интервал разделени. Така че може да имате проблеми с последния етикет. Наистина най-добрият начин би бил да нормализирате таблицата; в противен случай може да изтриете интервали от tags колона; накрая можете да заобиколите проблема, като добавите интервал към tags колона:
SELECT * FROM mytable WHERE FIND_IN_SET('ios ', CONCAT(tags,' ')) > 0;
Ако броят на етикетите е ограничен, може да помислите за преобразуване на колоната в SET . Това значително ще подобри ефективността.
АКТУАЛИЗИРАНЕ
С изключение на това, че сгреших . Те са преди низовете, а не след това.
И така:
SELECT * FROM mytable WHERE FIND_IN_SET(' ios', CONCAT(' ', tags)) > 0;
Но отново, отървете се от тези пространства - те не са нищо друго освен проблеми :-)
АКТУАЛИЗИРАНЕ 2
Горното работи, добре. Но това е почти всичко, което можете да кажете в моя полза. Не само, че решението е доста *не*ефективно, но също така прави системата почти неподдържаема (бях там, направих това, получих тениската и сдъвканото дупе отдолу). Така че сега ще изразя малко в полза на нормализирането, т.е. да има поне още тези две таблици:
CREATE TABLE tags ( id INTEGER NOT NULL PRIMARY KEY AUTO_INCREMENT,
tagName varchar(32) // I'm a bit of a cheapskate
);
CREATE TABLE has_tag ( tableid INTEGER, tagid INTEGER );
Колко е по-добре това? Нека преброя начините.
- можете лесно да добавяте по-гъвкави заявки („има всички тагове в iOS, C++, ...“ или „има поне три маркера между тези:( iOS, Python, SQL, .NET, Haskell)“. Да, можете да направите това с
FIND_IN_SET, но повярвайте ми, няма да ви хареса . - имате контролиран речник на тагове, което ви дава възможност да проверите дали някой маркер е известен (както и лесно да генерирате списъци като падащи комбинирани полета или -- някой казал ли е 'jQuery Autocomplete'?).
- спестява някои дискови имоти (таговете се записват веднъж)
- търсенията са бързи . Ако вече знаете маркерите, които търсите, и ги компилирате предварително в идентификатори на маркери, те ще оставят SQL гумени отпечатъци върху настилката, когато се изпълняват (индексирано търсене за цяло число стойност!). И тагове, които няма да се компилират, няма да ги има , и ще разберете това още преди да започне търсенето.
- прави много по-лесно преименуването на тагове
- може да съдържа всяко число от тагове (рискувате някой маркер да бъде съкратен до „iOS Developm“ рано или късно...)
Вярвам, че "CSV полето" е преценено (или) оценено сред SQL Antipatterns ( https://pragprog.com/book/bksqla/sql-antipatterns ), и с добра причина.