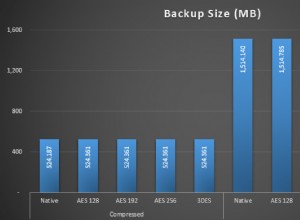
За да преброи броя на редовете с конкретна дата, MySQL трябва да намери тази стойност в индекса (което е доста бързо, в крайна сметка за това са създадени индексите) и след това да прочете следващите записи от индекса em> докато не намери следващата дата. В зависимост от типа данни на esi , това ще доведе до четене на някои MB данни, за да преброите вашите 700k реда. Четенето на някои MB не отнема много време (и тези данни може дори вече да са кеширани в буферния пул, в зависимост от това колко често използвате индекса).
За да изчисли средната стойност за колона, която не е включена в индекса, MySQL отново ще използва индекса, за да намери всички редове за тази дата (същите както преди). Но освен това, за всеки ред, който намира, той трябва да прочете действителните данни от таблицата за този ред, което означава да използва първичния ключ, за да намери реда, да прочете някои байтове и да повтори това 700k пъти. Този "произволен достъп"
е много по-бавно от последователното четене в първия случай. (Това се влошава от проблема, че "някои байтове" са innodb_page_size
(16KB по подразбиране), така че може да се наложи да прочетете до 700k * 16KB =11GB, в сравнение с "някои MB" за count(*); и в зависимост от конфигурацията на паметта ви, някои от тези данни може да не се кешират и трябва да бъдат прочетени от диск.)
Решение за това е да се включат всички използвани колони в индекса („покриващ индекс“), напр. създайте индекс на date, 01 . Тогава MySQL няма нужда от достъп до самата таблица и може да продължи, подобно на първия метод, като просто прочете индекса. Размерът на индекса ще се увеличи малко, така че MySQL ще трябва да прочете "още MB" (и да изпълни avg -операция), но все пак трябва да е въпрос на секунди.
В коментарите споменахте, че трябва да изчислите средната стойност за 24 колони. Ако искате да изчислите avg за няколко колони едновременно, ще ви трябва покриващ индекс за всички от тях, напр. date, 01, 02, ..., 24 за да предотвратите достъпа до масата. Имайте предвид, че индекс, който съдържа всички колони, изисква толкова място за съхранение, колкото самата таблица (и ще отнеме много време за създаване на такъв индекс), така че може да зависи от това колко важна е тази заявка дали си струва тези ресурси.
За да избегнете ограничение на MySQL от 16 колони на индекс
, можете да го разделите на два индекса (и две заявки). Създайте напр. индексите date, 01, .., 12 и date, 13, .., 24 , след което използвайте
select * from (select `date`, avg(`01`), ..., avg(`12`)
from mytable where `date` = ...) as part1
cross join (select avg(`13`), ..., avg(`24`)
from mytable where `date` = ...) as part2;
Уверете се, че сте документирали това добре, тъй като няма очевидна причина да напишете заявката по този начин, но може да си струва.
Ако някога правите усредняване само за една колона, можете да добавите 24 отделни индекса (на date, 01 , date, 02 , ...), въпреки че като цяло те ще изискват още повече място, но може да са малко по-бързи (тъй като са по-малки поотделно). Но буферният пул все пак може да благоприятства пълния индекс, в зависимост от фактори като модели на използване и конфигурация на паметта, така че може да се наложи да го тествате.
От date е част от вашия първичен ключ, можете също да помислите за промяна на първичния ключ на date, esi . Ако намерите датите по първичния ключ, няма да имате нужда от допълнителна стъпка за достъп до данните в таблицата (тъй като вече имате достъп до таблицата), така че поведението ще бъде подобно на покриващия индекс. Но това е значителна промяна във вашата таблица и може да засегне всички други заявки (които например използват esi за намиране на редове), така че трябва да се обмисли внимателно.
Както споменахте, друга опция би била да се създаде обобщена таблица, където съхранявате предварително изчислени стойности, особено ако не добавяте или променяте редове за минали дати (или можете да ги поддържате актуални с тригер).