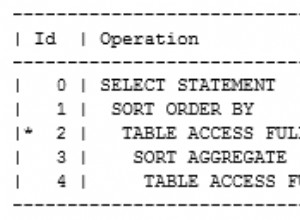
Реалистично ли е да има толкова много редове с една и съща price ? Реалистично ли е да се върнат 444K реда от заявка? Питам ги, защото оптимизацията на заявките се основава на „нормални“ данни.
Индекс (напр. INDEX(price)). ) е полезно, когато търсите price което се случва малък брой пъти. Всъщност оптимизаторът избягва индекса, ако види, че търсената стойност се среща повече от около 20% от времето. Вместо това просто ще игнорира индекса и ще направи това, което сте тествали първо – просто ще сканира цялата таблица, игнорирайки всички редове, които не съвпадат.
Трябва да можете да видите това, като направите
EXPLAIN select * from books where price = 10
със и без индекса. Като алтернатива можете да опитате:
EXPLAIN select * from books IGNORE INDEX(books_price_index) where price = 10
EXPLAIN select * from books FORCE INDEX(books_price_index) where price = 10
Но... Изглежда, че оптимизаторът не е пренебрегнал индекса. Виждам, че "кардиналността" на price е "1", което означава, че има само една отделна стойност в тази колона. Тази „статистика“ е или неправилна, или подвеждаща. Моля, стартирайте това и вижте какво се променя:
ANALYZE TABLE books;
Това ще преизчисли статистиката чрез няколко произволни проби и може променете това "1" на може би "2".
Общ съвет:Пазете се от сравнителни показатели, които работят с измислени данни.