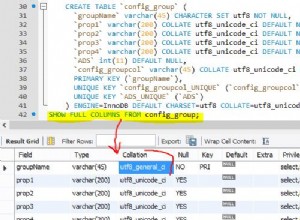
Колекция засяга само сортирането на текст, няма ефект върху действителния набор от символи на съхранените данни.
Бих препоръчал тази конфигурация:
-
Задайте набора от знаци за цялата БД само, така че не е нужно да го задавате за всяка таблица поотделно. Наборът от символи се наследява от DB към таблици към колони. Използвайте
utf8като набор от знаци. -
Задайте набора от знаци за DB връзката . Изпълнете тези заявки, след като се свържете с базата данни:
SET CHARACTER SET 'utf8' SET NAMES 'utf8' -
Задайте набора от знаци за страницата , използвайки HTTP заглавка и/или HTML мета маркер. Едно от тях е достатъчно. Използвайте
utf-8катоcharset.
Това трябва да е достатъчно.
Ако искате да имате правилно сортиране на испанските низове, задайте колекция за цялата база данни. utf8_spanish_ci трябва да работи (ci означава Регистър без значение ). Без подходящо съпоставяне испанските символи с ударение винаги ще бъдат сортирани последни.
Забележка :възможно е наборът от знаци от данни, които вече имате в таблица, да е повреден, тъй като конфигурацията на набора от знаци е била грешна преди това. Трябва първо да го проверите с някой DB клиент, за да изключите този случай. Ако е повреден, просто поставете отново данните си с правилната конфигурация на набора от знаци.
Как набор от знаци работа в база данни
-
обекти имат набор от знаци атрибут, който може да бъде зададен изрично или е наследен (сървър> база данни> таблица> колона), така че най-добрият вариант е да го зададете за цялата база данни
-
клиентска връзка има също набор от знаци атрибут и той казва на базата данни в кое кодиране изпращате данните
Ако наборите от символи на връзката на клиента и на целевия обект са различни, данните, които изпращате към базата данни, автоматично се преобразуват от набора от знаци на връзката в набора от символи на обекта.
Така че, ако имате например данните в utf8 , но клиентска връзка зададен на latin1 , базата данни ще разбие данните, защото ще се опита да преобразува utf8 все едно е latin1 .