CREATE DEFINER = 'root'@'localhost'
PROCEDURE test.GetHierarchyUsers(IN StartKey INT)
BEGIN
-- prepare a hierarchy level variable
SET @hierlevel := 00000;
-- prepare a variable for total rows so we know when no more rows found
SET @lastRowCount := 0;
-- pre-drop temp table
DROP TABLE IF EXISTS MyHierarchy;
-- now, create it as the first level you want...
-- ie: a specific top level of all "no parent" entries
-- or parameterize the function and ask for a specific "ID".
-- add extra column as flag for next set of ID's to load into this.
CREATE TABLE MyHierarchy AS
SELECT U.ID
, U.Parent
, U.`name`
, 00 AS IDHierLevel
, 00 AS AlreadyProcessed
FROM
Users U
WHERE
U.ID = StartKey;
-- how many rows are we starting with at this tier level
-- START the cycle, only IF we found rows...
SET @lastRowCount := FOUND_ROWS();
-- we need to have a "key" for updates to be applied against,
-- otherwise our UPDATE statement will nag about an unsafe update command
CREATE INDEX MyHier_Idx1 ON MyHierarchy (IDHierLevel);
-- NOW, keep cycling through until we get no more records
WHILE @lastRowCount > 0
DO
UPDATE MyHierarchy
SET
AlreadyProcessed = 1
WHERE
IDHierLevel = @hierLevel;
-- NOW, load in all entries found from full-set NOT already processed
INSERT INTO MyHierarchy
SELECT DISTINCT U.ID
, U.Parent
, U.`name`
, @hierLevel + 1 AS IDHierLevel
, 0 AS AlreadyProcessed
FROM
MyHierarchy mh
JOIN Users U
ON mh.Parent = U.ID
WHERE
mh.IDHierLevel = @hierLevel;
-- preserve latest count of records accounted for from above query
-- now, how many acrual rows DID we insert from the select query
SET @lastRowCount := ROW_COUNT();
-- only mark the LOWER level we just joined against as processed,
-- and NOT the new records we just inserted
UPDATE MyHierarchy
SET
AlreadyProcessed = 1
WHERE
IDHierLevel = @hierLevel;
-- now, update the hierarchy level
SET @hierLevel := @hierLevel + 1;
END WHILE;
-- return the final set now
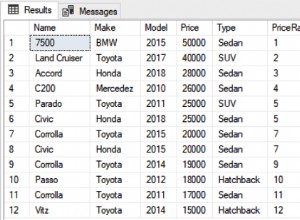
SELECT *
FROM
MyHierarchy;
-- and we can clean-up after the query of data has been selected / returned.
-- drop table if exists MyHierarchy;
END
Може да изглежда тромаво, но за да използвате това, направете го
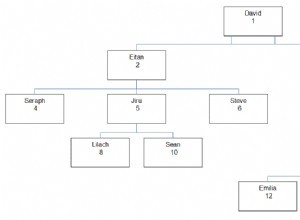
call GetHierarchyUsers( 5 );
(или какъвто и да е ключов ID, за който искате да намерите НАГОРЕ в йерархичното дърво).
Предпоставката е да започнете с единия КЛЮЧ, с който работите. След това използвайте това като основа, за да се присъедините към таблицата с потребители ОТНОВО, но въз основа на PARENT ID на първия запис. След като бъде намерена, актуализирайте временната таблица, за да не се опитвате да се присъедините отново към този ключ на следващия цикъл. След това продължете, докато не бъдат намерени повече „родителски“ идентификационни ключове.
Това ще върне цялата йерархия от записи до родителя, независимо колко дълбоко е вложението. Въпреки това, ако искате само FINAL родител, можете да използвате променливата @hierlevel, за да върнете само последната във добавения файл или ORDER BY и LIMIT 1