Тестовете за пускане обикновено са една от стъпките в целия процес на внедряване. Пишете кода и след това проверявате как се държи в промеждуваща среда и след това, накрая, внедрявате новия код в продукцията. Базите данни са вътрешни за всеки вид приложение и следователно е важно да се провери как промените, свързани с базата данни, променят приложението. Възможно е да го проверите по няколко начина; един от тях би бил да се използва специална реплика. Нека да разгледаме как може да се направи.
Очевидно е, че не искате този процес да бъде ръчен - той трябва да бъде част от процесите на CI/CD на вашата компания. В зависимост от точното приложение, среда и процеси, които имате, можете да използвате копия, създадени ad hoc или реплики, които винаги са част от средата на базата данни.
Начинът, по който Galera Cluster работи е, че обработва промените в схемата по специфичен начин. Възможно е да се изпълни промяна на схемата на един възел в клъстера, но това е трудно, тъй като не поддържа всички възможни промени в схемата и ще повлияе на производството, ако нещо се обърка. Такъв възел ще трябва да бъде напълно възстановен с помощта на SST, което означава, че един от останалите възли на Galera ще трябва да действа като донор и да прехвърля всичките си данни през мрежата.
Алтернатива ще бъде използването на реплика или дори цял допълнителен клъстер Galera, действащ като реплика. Очевидно процесът трябва да бъде автоматизиран, за да се включи в тръбопровода за разработка. Има много начини да направите това:скриптове или множество инструменти за оркестриране на инфраструктура като Ansible, Chef, Puppet или Salt stack. Няма да ги описваме подробно, но бихме искали да покажете стъпките, необходими за правилното функциониране на целия процес, и ще оставим внедряването в един от инструментите на вас.
Автоматизиране на тестовете за пускане
На първо място, искаме да можем лесно да разгръщаме нова база данни. Той трябва да бъде снабден с последните данни и това може да стане по много начини - можете да копирате данните от производствената база данни в тестовия сървър; това е най-простото нещо за правене. Като алтернатива можете да използвате най-новото архивиране - такъв подход има допълнителни предимства при тестване на възстановяването на архива. Проверката на архивиране е задължителна при всякакъв вид сериозно внедряване, а възстановяването на тестови настройки е чудесен начин да проверите отново работата на процеса на възстановяване. Той също така ви помага да насрочите процеса на възстановяване – като знаете колко време отнема възстановяването на архива ви, помага да оцените правилно ситуацията при сценарий за възстановяване при бедствие.
След като данните бъдат предоставени в базата данни, може да искате да настроите този възел като реплика на вашия основен клъстер. Има своите плюсове и минуси. Ако можете да изпълните отново целия си трафик към самостоятелния възел, това би било перфектно - в такъв случай няма нужда да настройвате репликацията. Някои от балансиращите устройства, като ProxySQL, ви позволяват да отразявате трафика и да изпращате копието му на друго място. От друга страна, репликацията е следващото най-добро нещо. Да, не можете да изпълнявате записи директно на този възел, което ви принуждава да планирате как ще изпълните повторно заявките, тъй като най-простият подход просто да отговаряте няма да работи. От друга страна, всички записи в крайна сметка ще бъдат изпълнени чрез SQL нишката, така че трябва само да планирате как да се справите със заявките SELECT.
В зависимост от точната промяна, може да искате да тествате процеса на промяна на схемата. Промените в схемата са доста често срещани и може да имат дори сериозно въздействие върху производителността на базата данни. Ето защо е важно да ги проверите, преди да ги приложите в производството. Искаме да разгледаме времето, необходимо за изпълнение на промяната и да проверим дали промяната може да се приложи на възли поотделно или се изисква да се извърши промяната върху цялата топология едновременно. Това ще ни каже какъв процес трябва да използваме за дадена промяна на схемата.
Използване на ClusterControl за подобряване на автоматизацията на тестовете за пускане
ClusterControl идва с набор от функции, които могат да се използват, за да ви помогнат да автоматизирате тестовете за освобождаване. Нека да разгледаме какво предлага. За да стане ясно, функциите, които ще покажем, са достъпни по няколко начина. Най-простият начин е да използвате потребителски интерфейс, но е излишно какво искате да правите, ако имате автоматизация наум. Има още два начина да го направите:интерфейс на командния ред към ClusterControl и RPC API. И в двата случая заданията могат да бъдат задействани от външни скриптове, което ви позволява да ги включите във вашите съществуващи CI/CD процеси. Освен това ще ви спести много време, тъй като разгръщането на клъстера може да бъде само въпрос на изпълнение на една команда, вместо да го настройвате ръчно.
Разгръщане на тестовия клъстер
Първо и най-важно, ClusterControl идва с опция за разгръщане на нов клъстер и предоставяне на данните от съществуващата база данни. Тази функция сама по себе си ви позволява лесно да внедрите обезпечаване на професионалния сървър.
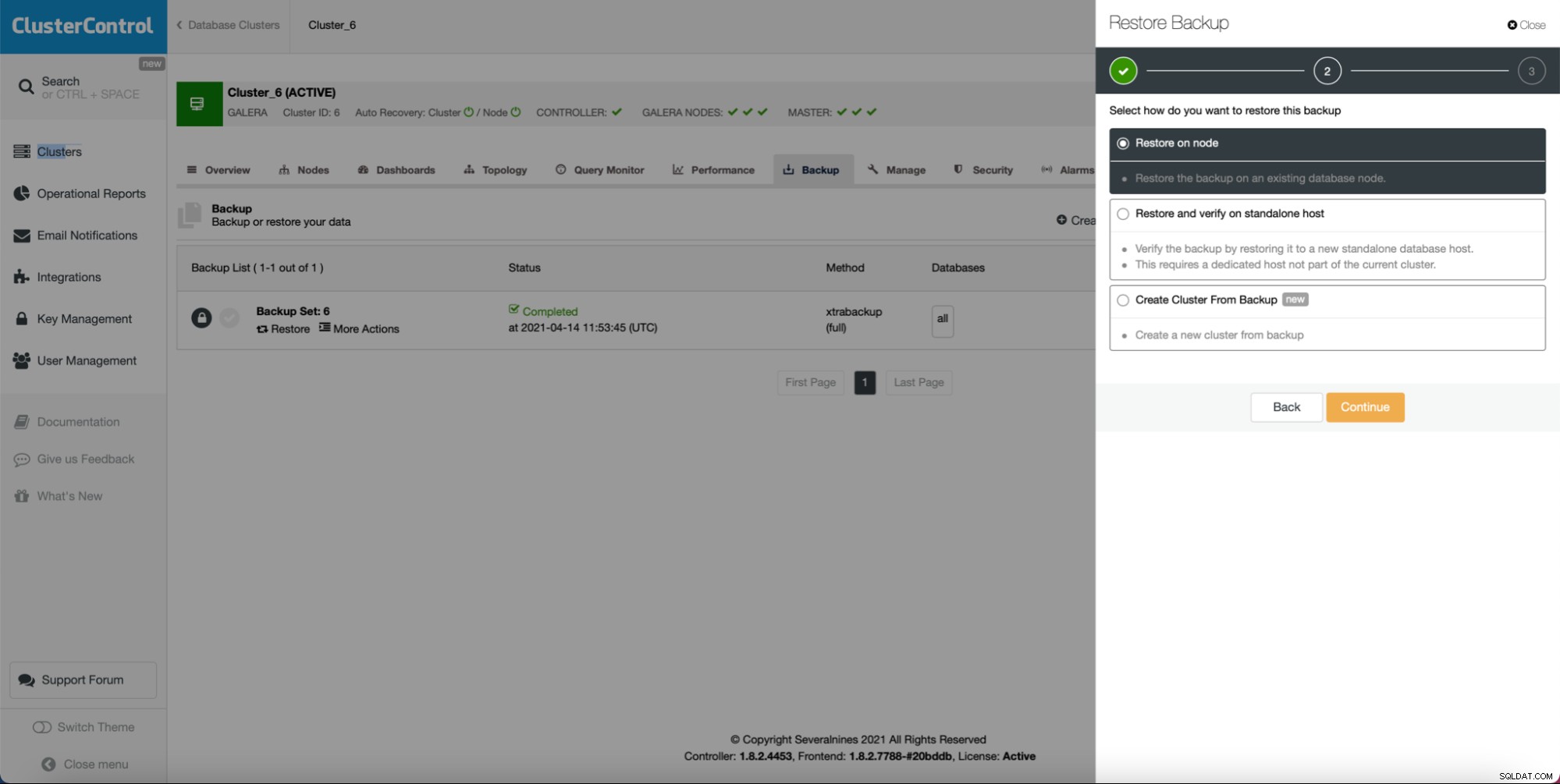
Както виждате, стига да имате създадено резервно копие, вие може да създаде нов клъстер и да го осигури, използвайки данните от архива:
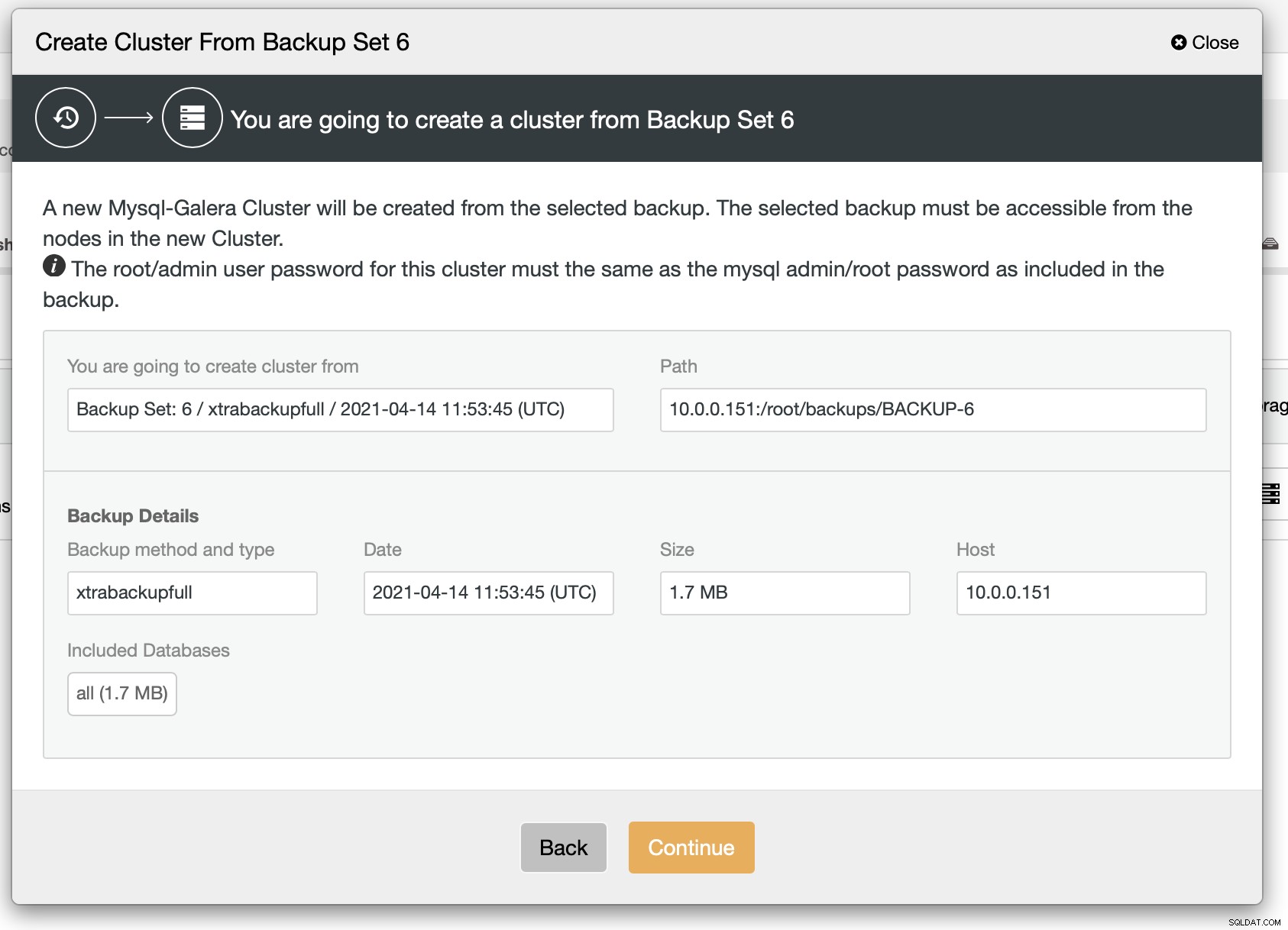
Както виждаме, има кратко обобщение на това, което ще се случи. Ако щракнете върху Продължи, ще продължите по-нататък.
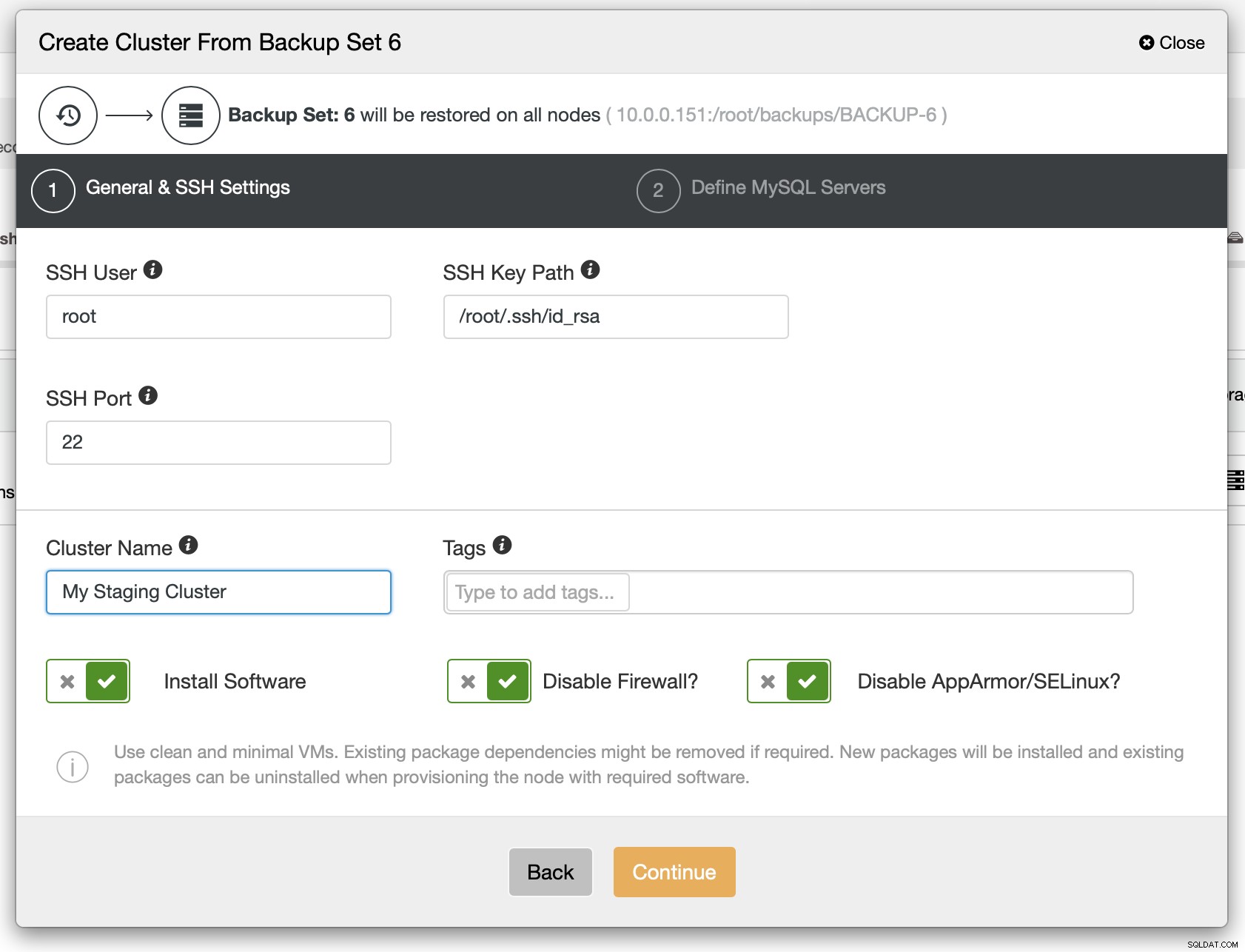
Като следваща стъпка трябва да дефинирате SSH свързаността – тя трябва да е на място, преди ClusterControl да може да разгърне възлите.
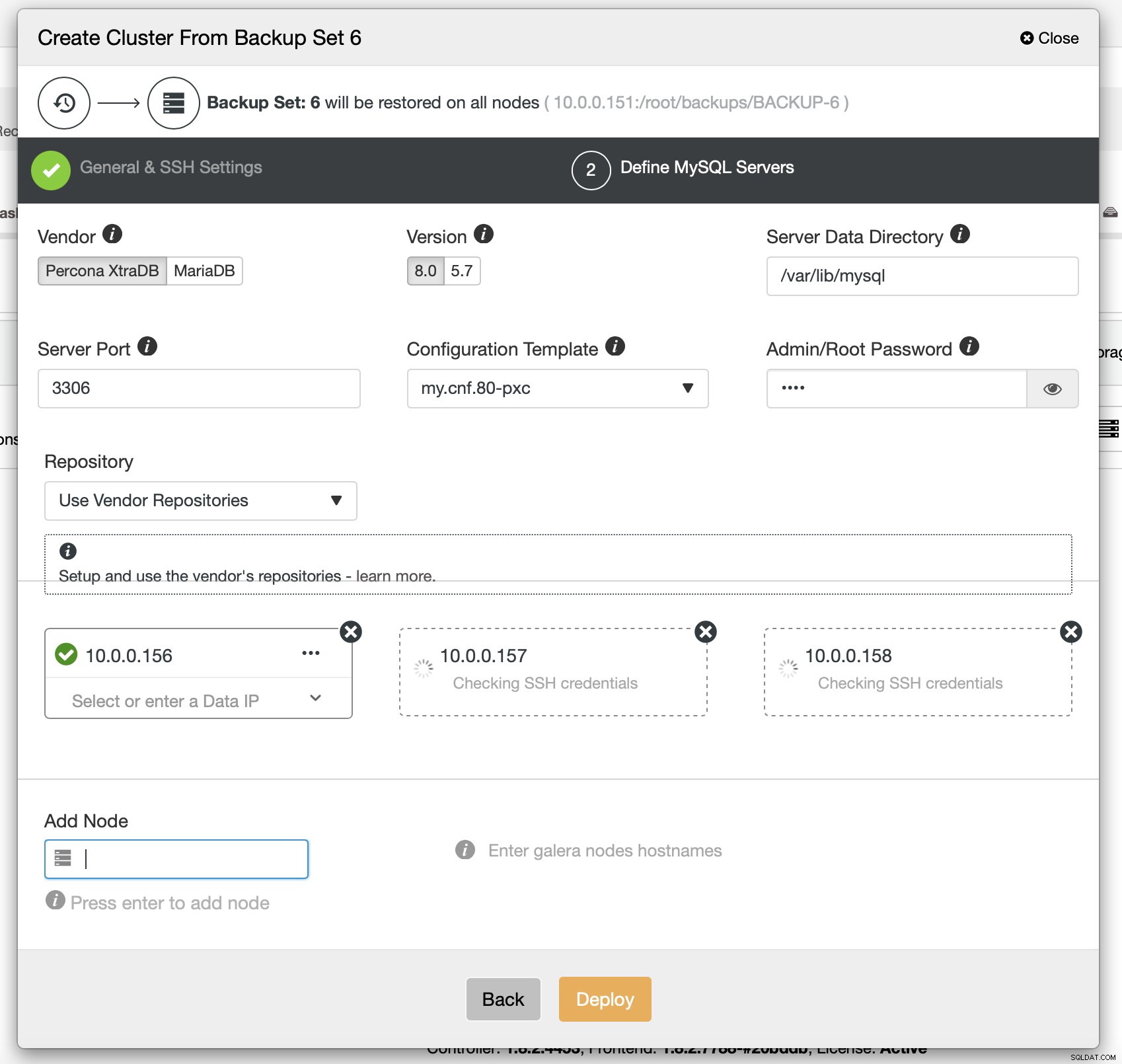
Накрая трябва да изберете (наред с другото) доставчика, версията и имената на хостовете на възлите, които искате да използвате в клъстера. Това е само.
Командата на CLI, която би постигнала същото нещо, изглежда така:
s9s cluster --create --cluster-type=galera --nodes="10.0.0.156;10.0.0.157;10.0.0.158" --vendor=percona --cluster-name=PXC --provider-version=8.0 --os-user=root --os-key-file=/root/.ssh/id_rsa --backup-id=6Конфигуриране на ProxySQL за отразяване на трафика
Ако имаме разгърнат клъстер, може да искаме да изпратим производствения трафик към него, за да проверим как новата схема се справя със съществуващия трафик. Един от начините да направите това е като използвате ProxySQL.
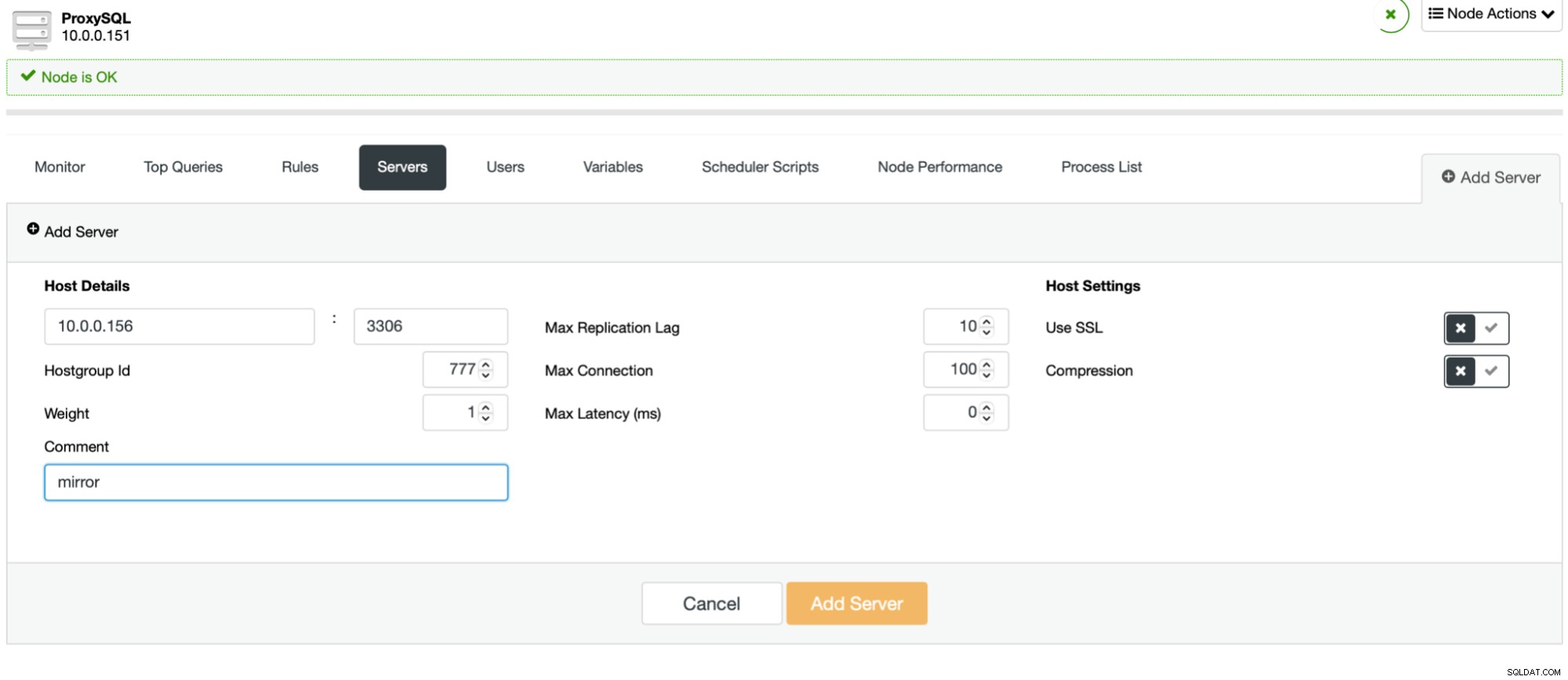
Процесът е лесен. Първо, трябва да добавите възлите към ProxySQL. Те трябва да принадлежат към отделна хостгрупа, която все още не се използва. Уверете се, че потребителят на монитора на ProxySQL ще има достъп до тях.
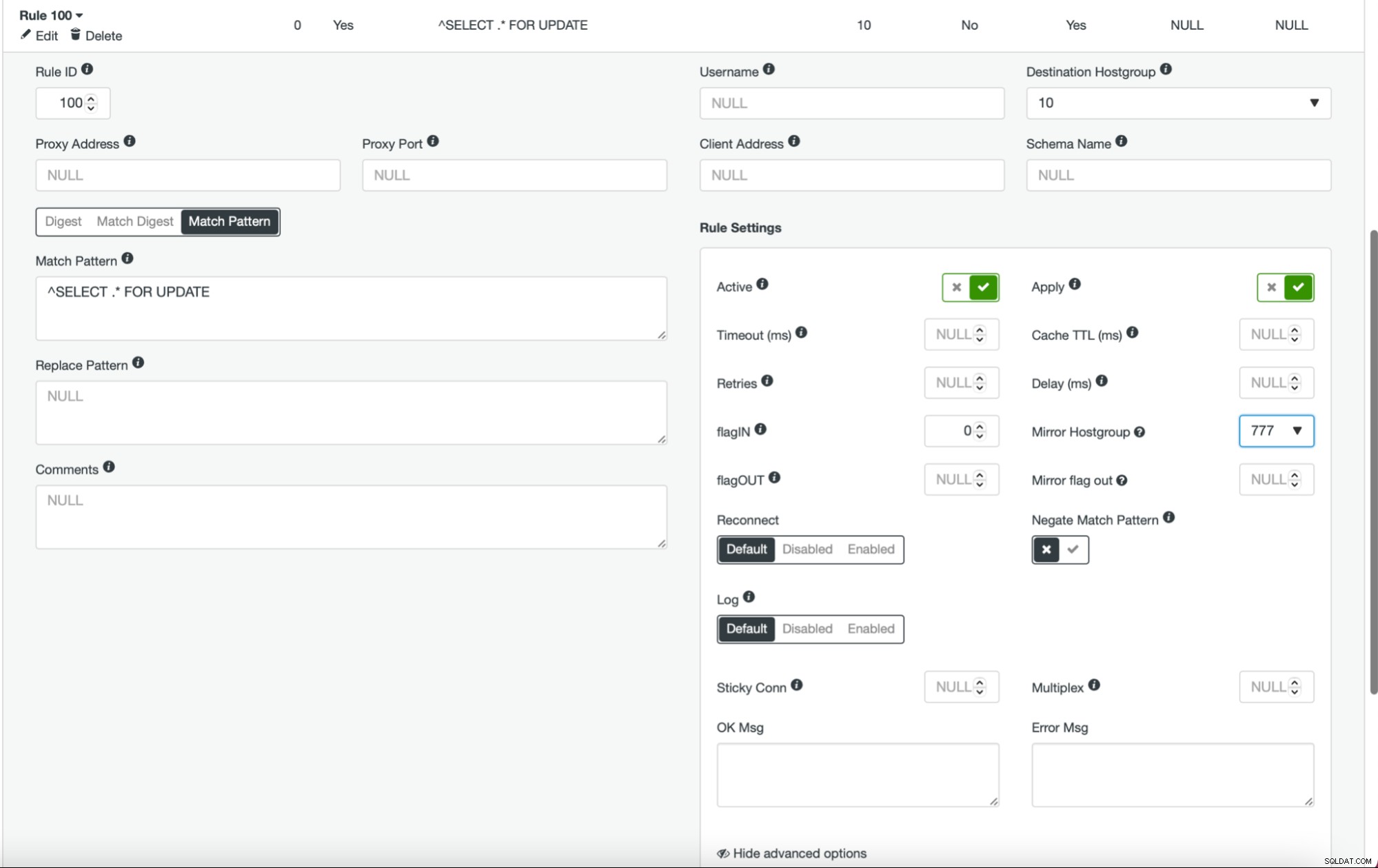
След като това е направено и всички (или някои) от вашите възли са конфигурирани в хост групата, можете да редактирате правилата на заявката и да дефинирате огледалната хостгрупа (тя е налична в разширените опции). Ако искате да го направите за целия трафик, вероятно искате да редактирате всичките си правила за заявка по този начин. Ако искате да отразявате само SELECT заявки, трябва да редактирате съответните правила за заявка. След като това бъде направено, вашият етапен клъстер трябва да започне да получава производствен трафик.
Разгръщане на клъстер като подчинен
Както обсъдихме по-рано, алтернативно решение би било да се създаде нов клъстер, който да действа като реплика на съществуващата настройка. С такъв подход можем да тестваме всички записи автоматично, като използваме репликацията. SELECT могат да бъдат тествани с помощта на подхода, който описахме по-горе - огледално отразяване чрез ProxySQL.
Разгръщането на подчинен клъстер е доста лесно.
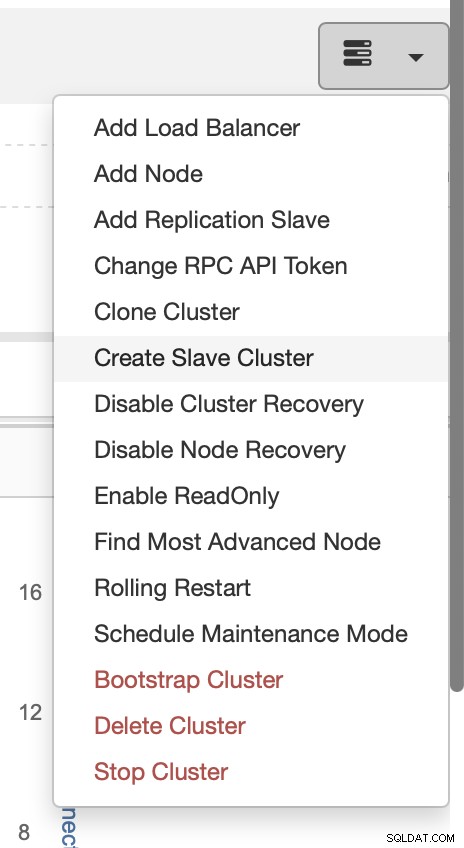
Изберете заданието Създаване на подчинен клъстер.
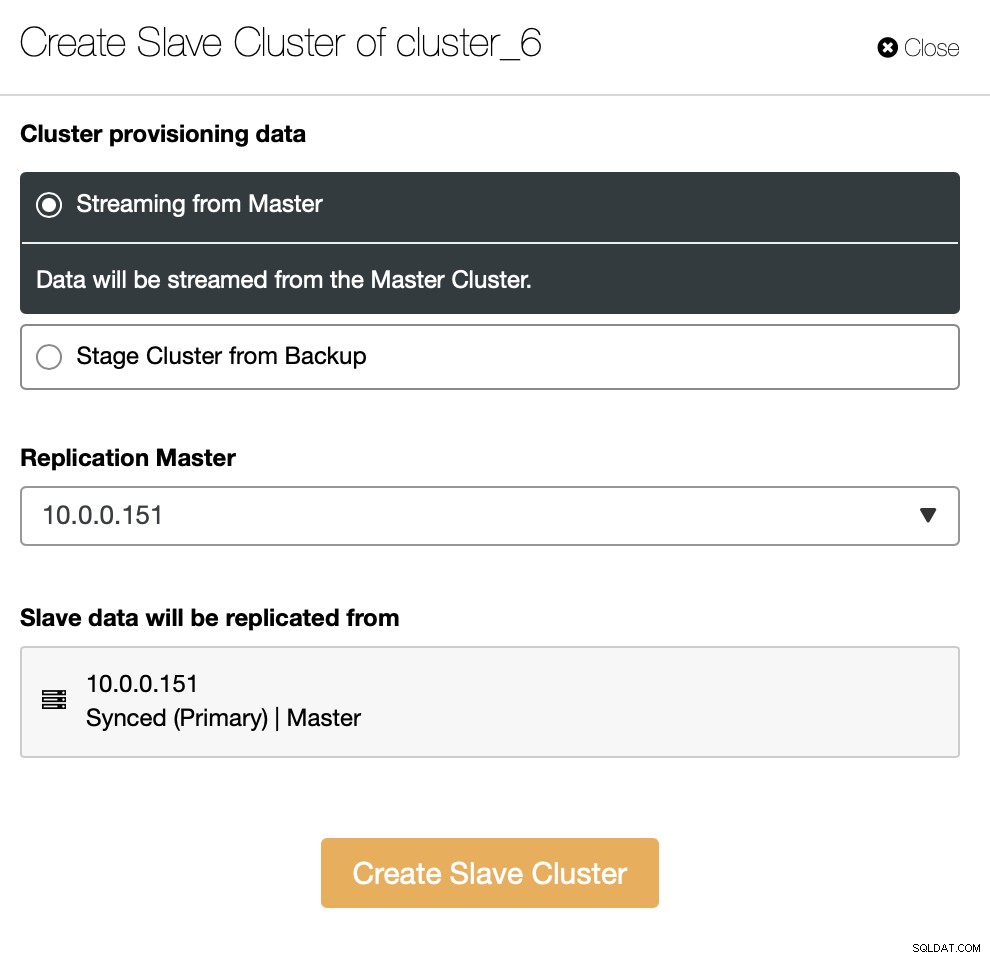
Трябва да решите как искате да настроите репликацията. Можете да прехвърлите всички данни от главния към новите възли.
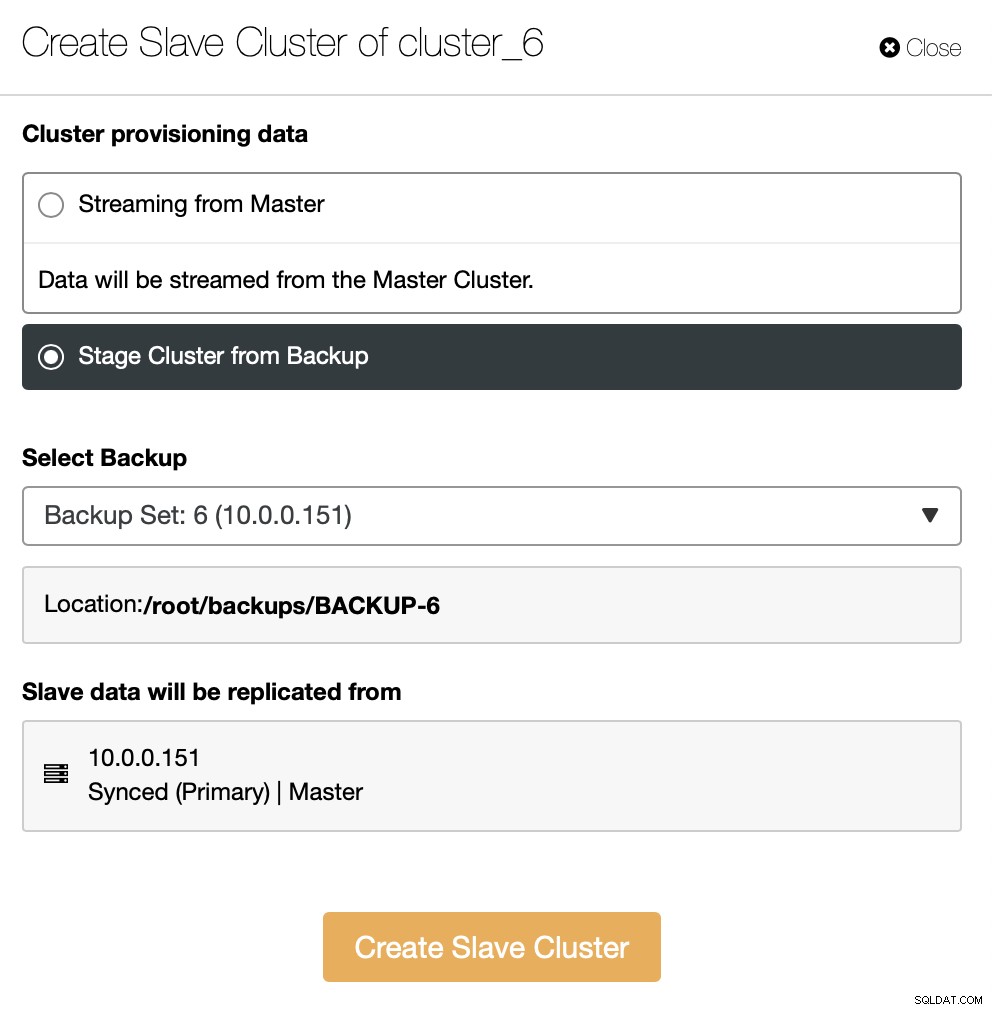
Като алтернатива можете да използвате съществуващо архивно копие, за да осигурите новия клъстер. Това ще помогне да се намали натоварването на главния възел – вместо да се прехвърлят всички данни, ще трябва да се прехвърлят само транзакции, които са били изпълнени между времето, когато е създадено архивирането и момента на настройка на репликацията.
Останалото е да следвате стандартния съветник за внедряване, дефиниране на SSH свързаност, версия, доставчик, хостове и т.н. След като бъде разгърнат, ще видите клъстера в списъка.
Алтернативно решение за потребителския интерфейс е да се постигне това чрез RPC.
{
"command": "create_cluster",
"job_data": {
"cluster_name": "",
"cluster_type": "galera",
"company_id": null,
"config_template": "my.cnf.80-pxc",
"data_center": 0,
"datadir": "/var/lib/mysql",
"db_password": "pass",
"db_user": "root",
"disable_firewall": true,
"disable_selinux": true,
"enable_mysql_uninstall": true,
"generate_token": true,
"install_software": true,
"port": "3306",
"remote_cluster_id": 6,
"software_package": "",
"ssh_keyfile": "/root/.ssh/id_rsa",
"ssh_port": "22",
"ssh_user": "root",
"sudo_password": "",
"type": "mysql",
"user_id": 5,
"vendor": "percona",
"version": "8.0",
"nodes": [
{
"hostname": "10.0.0.155",
"hostname_data": "10.0.0.155",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.159",
"hostname_data": "10.0.0.159",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.160",
"hostname_data": "10.0.0.160",
"hostname_internal": "",
"port": "3306"
}
],
"with_tags": []
}
}Преместване напред
Ако се интересувате да научите повече за начините, по които можете да интегрирате вашите процеси с ClusterControl, бихме искали да ви насочим към документацията, където имаме цял раздел за разработване на решения, където ClusterControl играе роля важна роля:
https://docs.severalnines.com/docs/clustercontrol/developer-guide/cmon-rpc/
https://docs.severalnines.com/docs/clustercontrol/user-guide-cli/
Надяваме се, че сте намерили този кратък блог информативен и полезен. Ако имате въпроси, свързани с интегрирането на ClusterControl във вашата среда, моля, свържете се с нас и ние ще направим всичко възможно, за да ви помогнем.