В днешно време е доста често срещано явление да има база данни, репликирана в друг сървър/център за данни, а в някои случаи също е задължително. Има различни причини да репликирате вашите бази данни в напълно отделна среда.
- Мигрирайте към друг център за данни.
- Изисквания за надстройка (хардуер/софтуер).
- Поддържайте напълно синхронизирана операционна система в сайт за възстановяване след бедствие (DR), който може да поеме управлението по всяко време
- Пазете подчинена база данни като част от по-евтин план за DR.
- За изисквания за географско местоположение (данните трябва да са локално в конкретна държава).
- Имате среда за тестване.
- Цел за отстраняване на неизправности.
- База данни за отчети.
И има различни начини за изпълнение на тази задача за репликация:
- Архивиране/Възстановяване :Архивирането на производствена база данни и възстановяването й в нов сървър/среда е класическият начин да направите това, но също така е старомоден начин, тъй като няма да поддържате данните си актуални и трябва да изчакате за всеки процес на възстановяване, ако имате нужда от скорошни данни. Ако имате клъстер (главен-подчинен, мулти-главен) и ако искате да го пресъздадете, трябва да възстановите първоначалното архивиране и след това да създадете отново останалите възли, което може да отнеме време задача.
- Клониране на клъстер :Подобен е на предишния, но процесът на архивиране и възстановяване е за целия клъстер, а не само за един конкретен сървър на база данни. По този начин можете да клонирате целия клъстер в една и съща задача и не е необходимо да пресъздавате останалите възли ръчно. Този метод все още има проблем с поддържането на данните актуални между клонингите.
- Репликация :Този начин включва опцията за архивиране/възстановяване, но след първоначалното възстановяване процесът на репликация ще поддържа данните ви синхронизирани с главния възел. По този начин, ако имате клъстер от база данни, трябва да възстановите архива на един възел и да създадете отново всички възли ръчно.
В този блог ще видим нова функция ClusterControl 1.7.4, която ви позволява да използвате комбинация от метода, който споменахме по-рано, за да подобрите тази задача.
Какво е репликация от клъстер към клъстер?
Репликацията между два клъстера не е същото като разширяването на клъстер, за да работи в два центъра за данни. Когато настройваме репликация между два клъстера, всъщност имаме 2 отделни системи, които могат да работят автономно. Репликацията се използва за поддържането им в синхрон, така че подчинената система да има актуализирано състояние и да може да поеме управлението.
От ClusterControl 1.7.4 е възможно да се създаде нов клъстер чрез директно клониране на работещ изходен клъстер или чрез използване на скорошно архивиране на изходния клъстер.
След клонирането на клъстера ще имате подчинен клъстер (SC), който получава данни, и главен клъстер (MC), изпращащ промени към подчинения.
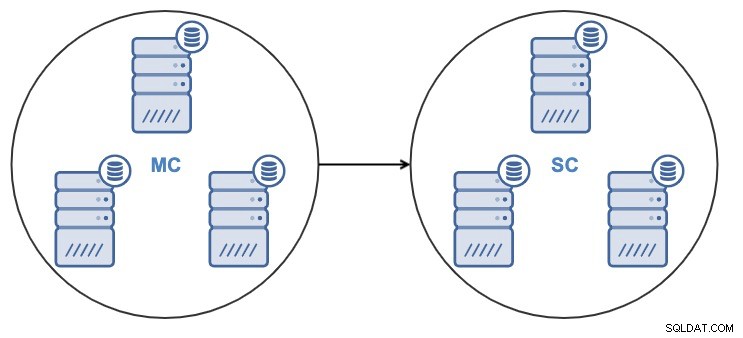
ClusterControl поддържа репликация от клъстер към клъстер за следните типове клъстери:
- Percona XtraDB Cluster версия 5.6.x и по-нова версия.
- MariaDB Galera Cluster версия 10.x и по-нова версия.
- PostgreSQL 9.6 и по-нови версии.
Репликация от клъстер към клъстер за Percona XtraDB / MariaDB Galera Cluster
За MySQL базирани двигатели се изисква GTID за използване на тази функция и ще се използва асинхронна репликация между главния и подчинения клъстер.
Има няколко действия, които трябва да изпълните, за да подготвите текущия клъстер за тази задача. Първо, поне един възел в текущия клъстер трябва да има активирани двоични регистрационни файлове. След това трябва да добавите потребителя за архивиране, конфигуриран в възела на базата данни в конфигурационния файл на ClusterControl, който ще се използва за задачи за управление. Всички тези действия могат да се извършват с помощта на ClusterControl UI или ClusterControl CLI.
Сега сте готови да създадете репликацията на Percona XtraDB/MariaDB Galera от клъстер към клъстер. Когато работата приключи, ще имате:
- Един възел в подчинения клъстер ще се репликира от един възел в главния клъстер.
- Репликацията ще бъде двупосочна между клъстерите.
- Всички възли в подчинения клъстер ще бъдат само за четене по подразбиране. Възможно е да деактивирате флага само за четене на възлите един по един.
- Клъстерирането активен-активен се препоръчва само ако приложенията докосват само несвързани набори от данни в който и да е клъстер, тъй като машината не предлага никакво откриване или разрешаване на конфликти.
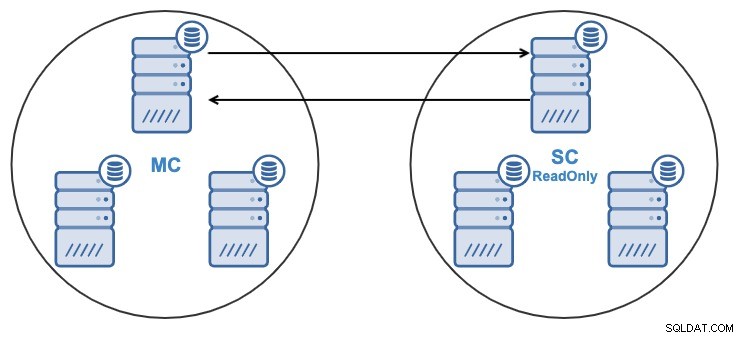
И от ClusterControl UI, и от ClusterControl CLI ще можете да:
- Създайте този клъстер за репликация.
- Активирайте конфигурацията Active-Active.
- Променете топологията на клъстера.
- Повторно изграждане на клъстер за репликация.
- Спиране/стартиране на подчинен репликация.
- Нулиране на подчинено устройство за репликация (реализирано само с помощта на ClusterControl CLI atm).
Съображения
- Резервният потребител трябва да бъде добавен ръчно в конфигурационния файл на ClusterControl.
- Резервните потребителски идентификационни данни трябва да са еднакви както в текущия, така и в новия клъстер.
- Паролата за root на MySQL, посочена при създаване на подчинен клъстер, трябва да е същата като паролата за root, използвана в главния клъстер.
Известни ограничения
- Автоматичното превключване при отказ все още не се поддържа. Ако главният кадър се повреди, тогава отговорността на администратора е да премине при отказ към друг главен.
- Възможно е само да се „НУЛИРА“ подчинен за репликация от CLI ClusterControl, тъй като все още не е внедрен в потребителския интерфейс на ClusterControl.
- Възможно е само да се изгради отново клъстер, който е в режим само за четене. Всички възли в клъстер трябва да са само за четене, за да се броят като клъстер само за четене.
Репликация от клъстер към клъстер за PostgreSQL
Репликацията на ClusterControl от клъстер към клъстер се поддържа в PostgreSQL, използвайки поточно репликация.
Като изискване трябва да има PostgreSQL сървър с ролята на ClusterControl „главен“ и когато настройвате подчинения клъстер, идентификационните данни на администратора трябва да са идентични с главния клъстер.
Сега сте готови да създадете PostgreSQL репликация от клъстер към клъстер. Когато работата приключи, ще имате:
- Един възел в подчинения клъстер ще се репликира от един възел в главния клъстер.
- Репликацията ще бъде еднопосочна между клъстерите.
- Възелът в подчинения клъстер ще бъде само за четене.
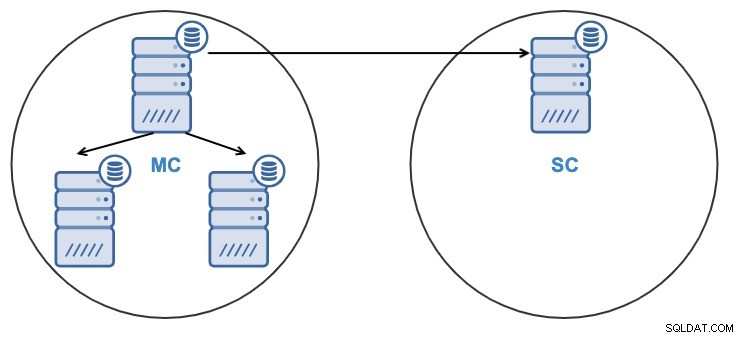
И от ClusterControl UI, и от ClusterControl CLI ще можете да:
- Създайте този клъстер за репликация.
- Повторно изграждане на клъстер за репликация.
- Спиране/стартиране на подчинен репликация.
Разглеждане
- Идентификационните данни на администратора трябва да са идентични в главния и подчинен клъстер.
Известни ограничения
- Максималният размер на подчинения клъстер е един възел.
- Подчинения клъстер не може да бъде монтиран от резервно копие.
- Промените в топологията не се поддържат.
- Поддържа се само еднопосочна репликация.
Заключение
Използвайки тази нова функция ClusterControl, не е необходимо да правите всяка стъпка, за да създадете репликация на клъстер отделно или ръчно, и в резултат на използването й ще спестите време и усилия. Опитайте!



