Хибридната репликация, т.е. комбинирането на Galera и асинхронната MySQL репликация в една и съща настройка, стана много по-лесна, след като GTID беше въведен в MySQL 5.6. Въпреки че беше доста лесно да се репликира от самостоятелен MySQL сървър към Galera Cluster, да се направи обратното (Galera → самостоятелен MySQL) беше малко по-предизвикателно. Поне до пристигането на GTID.
Има няколко добри причини да прикачите асинхронен подчинен към клъстер Galera. От една страна, продължителните заявки от типа на отчитане/OLAP на възел на Galera могат да забавят цял клъстер, ако натоварването на отчетите е толкова интензивно, че възелът трябва да прекара значителни усилия, за да се справи с него. Така заявките за отчитане могат да се изпращат до самостоятелен сървър, като ефективно изолира Galera от натоварването на отчетите. При подхода с колани и тиранти, асинхронният подчинен може да служи и като отдалечено резервно копие на живо.
В тази публикация в блога ще ви покажем как да репликирате клъстер на Galera на MySQL сървър с GTID и как да преодолявате репликацията в случай, че главният възел не успее.
Хибридна репликация в MySQL 5.5
В MySQL 5.5, възобновяването на счупена репликация изисква от вас да определите последния двоичен регистрационен файл и позиция, които са различни на всички възли на Galera, ако двоичното регистриране е активирано. Можем да илюстрираме тази ситуация със следната фигура:
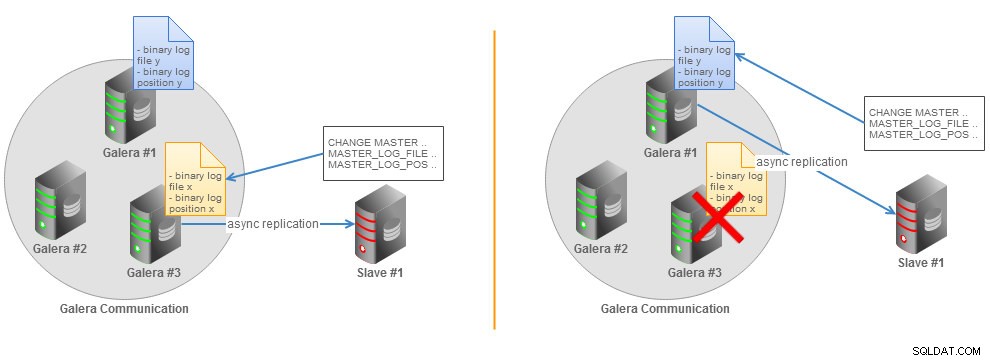 Асинхронна подчинена топология на клъстера на Galera без GTID
Асинхронна подчинена топология на клъстера на Galera без GTID Ако главният MySQL се провали, репликацията се прекъсва и подчиненият ще трябва да премине към друг главен. Ще трябва да изберете нов възел на Galera и ръчно да определите нов двоичен регистрационен файл и позицията на последната транзакция, изпълнена от подчинения. Друга възможност е да изхвърлите данните от новия главен възел, да ги възстановите на подчинен и да започнете репликация с новия главен възел. Разбира се, тези опции са изпълними, но не са много практични в производството.
Как GTID решава проблема
GTID (Global Transaction Identifier) осигурява по-добро картографиране на транзакциите между възли и се поддържа в MySQL 5.6. В Galera Cluster всички възли ще генерират различни binlog файлове. Събитията на binlog са едни и същи и в същия ред, но имената на binlog файловете и отместванията могат да варират. С GTID подчинените могат да видят уникална транзакция, идваща от няколко главни и това лесно може да бъде картографирано в списъка за подчинено изпълнение, ако трябва да рестартира или възобнови репликацията.
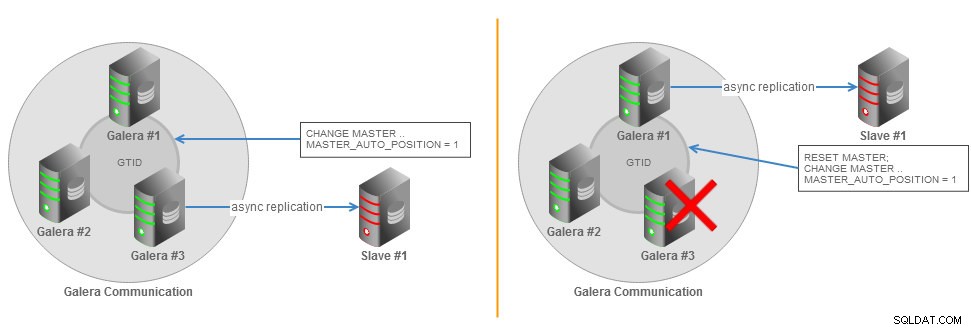 Асинхронна подчинена топология на клъстера на Galera с отказ от GTID
Асинхронна подчинена топология на клъстера на Galera с отказ от GTID Цялата необходима информация за синхронизиране с главната се получава директно от репликационния поток. Това означава, че когато използвате GTID за репликация, не е необходимо да включвате опции MASTER_LOG_FILE или MASTER_LOG_POS в оператора CHANGE MASTER TO. Вместо това е необходимо само да активирате опцията MASTER_AUTO_POSITION. Можете да намерите повече подробности за GTID в страницата за документация на MySQL.
Настройване на хибридна репликация на ръка
Уверете се, че възлите (главните) и подчинените(ите) на Galera работят на MySQL 5.6, преди да продължите с тази настройка. Имаме база данни, наречена sbtest в Galera, която ще репликираме на подчинения възел.
1. Активирайте необходимите опции за репликация, като посочите следните редове вътре в my.cnf на всеки DB възел (включително подчинения възел):
За главни (Galera) възли:
gtid_mode=ON
log_bin=binlog
log_slave_updates=1
enforce_gtid_consistency
expire_logs_days=7
server_id=1 # 1 for master1, 2 for master2, 3 for master3
binlog_format=ROWЗа подчинен възел:
gtid_mode=ON
log_bin=binlog
log_slave_updates=1
enforce_gtid_consistency
expire_logs_days=7
server_id=101 # 101 for slave
binlog_format=ROW
replicate_do_db=sbtest
slave_net_timeout=602. Извършете непрекъснато рестартиране на клъстера на Galera Cluster (от ClusterControl UI> Manage> Upgrade> Rolling Restart). Това ще презареди всеки възел с новите конфигурации и ще активира GTID. Рестартирайте и подчинения.
3. Създайте подчинен потребител за репликация и изпълнете следния оператор на един от възлите на Galera:
mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY 'slavepassword';4. Влезте в sbtest на подчинената и изхвърлящата база данни от един от възлите на Galera:
$ mysqldump -uroot -p -h192.168.0.201 --single-transaction --skip-add-locks --triggers --routines --events sbtest > sbtest.sql5. Възстановете дъмп файла на подчинения сървър:
$ mysql -uroot -p < sbtest.sql6. Стартирайте репликацията на подчинения възел:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.201', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;За да проверите дали репликацията работи правилно, проверете изхода на подчинен статус:
mysql> SHOW SLAVE STATUS\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...Настройване на хибридна репликация с помощта на ClusterControl
В предишния параграф описахме всички необходими стъпки за активиране на двоичните регистрационни файлове, рестартиране на клъстерния възел по възел, копиране на данните и след това настройка на репликация. Процедурата е досадна задача и лесно можете да направите грешки в една от тези стъпки. В ClusterControl сме автоматизирали всички необходими стъпки.
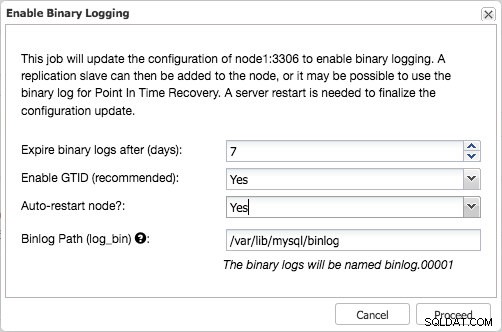
1. За потребители на ClusterControl, можете да отидете на възлите в страницата Nodes и да активирате двоично регистриране.
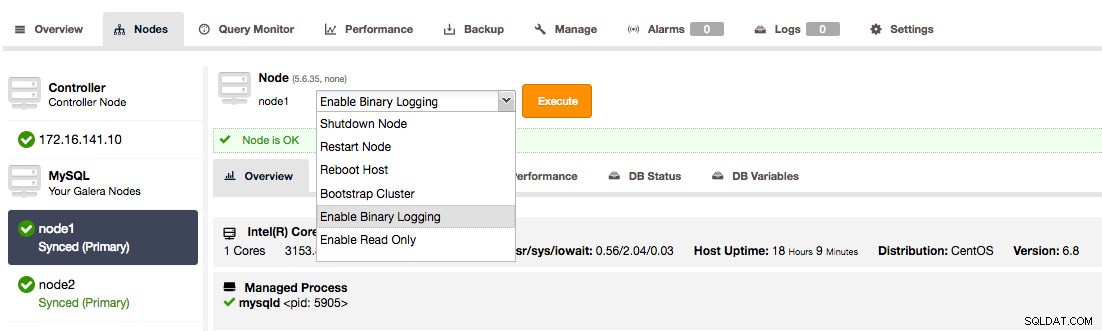 Активиране на двоично регистриране в клъстер Galera с помощта на ClusterControl
Активиране на двоично регистриране в клъстер Galera с помощта на ClusterControl Това ще отвори диалог, който ви позволява да зададете срока на валидност на двоичния дневник, да активирате GTID и автоматично рестартиране.
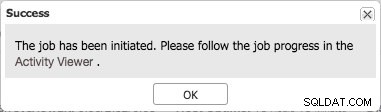
 Активиране на двоично регистриране с активиран GTID
Активиране на двоично регистриране с активиран GTID Това инициира задание, което безопасно ще запише тези промени в конфигурацията, ще създаде потребители за репликация с подходящите разрешения и ще рестартира възела безопасно.
 Описание на снимката
Описание на снимката Повторете този процес за всеки възел на Galera в клъстера, докато всички възли покажат, че са главни.
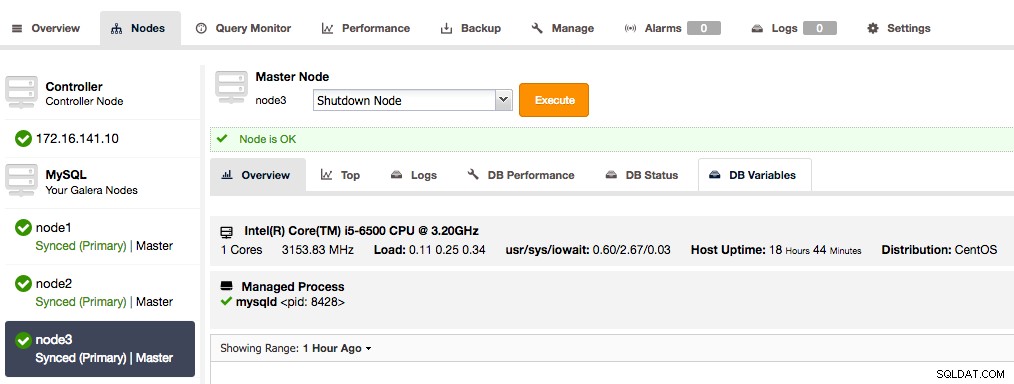 Всички възли на Galera Cluster вече са главни
Всички възли на Galera Cluster вече са главни 2. Добавете подчинения за асинхронна репликация към клъстера
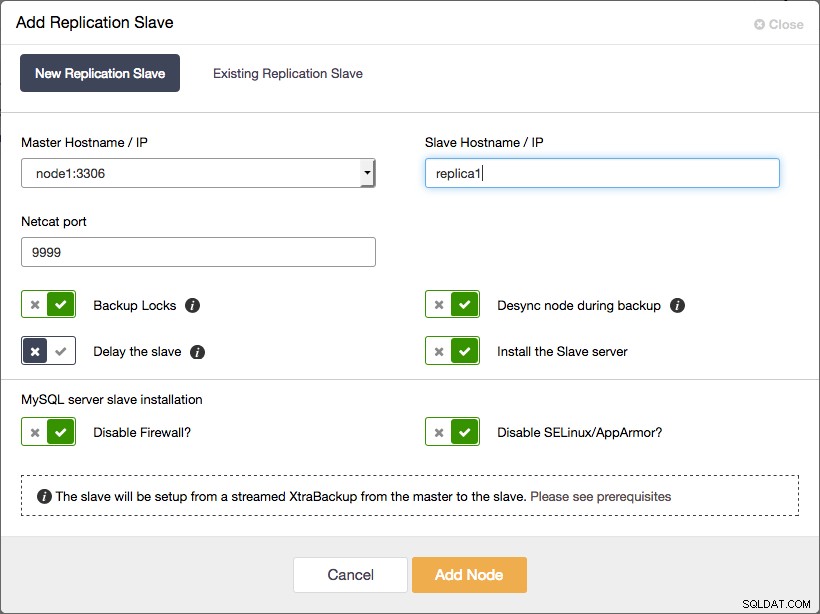 Добавяне на роб на асинхронна репликация към Galera Cluster с помощта на ClusterControl
Добавяне на роб на асинхронна репликация към Galera Cluster с помощта на ClusterControl И това е всичко, което трябва да направите. Целият процес, описан в предишния параграф, е автоматизиран от ClusterControl.
Промяна на главния
Ако определеният главен изпадне, подчиненият ще се опита да се свърже отново в стойност slave_net_timeout (нашата настройка е 60 секунди - по подразбиране е 1 час). Трябва да видите следната грешка при подчинен статус:
Last_IO_Errno: 2003
Last_IO_Error: error reconnecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 1Тъй като използваме Galera с активиран GTID, главният отказ се поддържа чрез ClusterControl, когато Автоматично възстановяване на клъстер и възел е активиран. Независимо дали главният възел ще се провали поради мрежова свързаност или друга причина, ClusterControl автоматично ще премине към най-подходящия друг главен възел в клъстера.
Ако искате да извършите ръчно преодоляване на отказ, просто променете главния възел, както следва:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.202', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;В някои случаи може да срещнете грешка „Дублиране на запис .. за ключ“ след промяна на главния възел:
Last_Errno: 1062
Last_Error: Could not execute Write_rows event on table sbtest.sbtest; Duplicate entry '1089775' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log mysqld-bin.000009, end_log_pos 85789000В по-старите версии на MySQL можете просто да използвате SET GLOBAL SQL_SLAVE_SKIP_COUNTER =n за да пропуснете изрази, но не работи с GTID. Мигел от Percona написа страхотна публикация в блога за това как да поправите това чрез инжектиране на празни транзакции.
Друг подход, за по-малки бази данни, може също да бъде просто да получите нов дъмп от всеки от наличните възли на Galera, да го възстановите и да използвате RESET MASTER оператор:
mysql> STOP SLAVE;
mysql> RESET MASTER;
mysql> DROP SCHEMA sbtest; CREATE SCHEMA sbtest; USE sbtest;
mysql> SOURCE /root/sbtest_from_galera2.sql; -- repeat step #4 above to get this dump
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.202', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Можете също да използвате pt-table-checksum, за да проверите целостта на репликацията, повече информация в тази публикация в блога.
Забележка:Тъй като в MySQL репликацията подчиненият аппликатор по подразбиране е все още еднонишков, не очаквайте производителността на асинхронната репликация да бъде същата като паралелната репликация на Galera. За MySQL 5.6 и 5.7 има опции асинхронната репликация да се изпълнява паралелно на подчинените възли, но по принцип тази репликация все още зависи от правилния ред на транзакциите в същата схема. Ако натоварването на репликацията е интензивно и непрекъснато, забавянето на подчинените ще продължи да нараства. Виждали сме случаи, когато робът никога не може да настигне господаря.