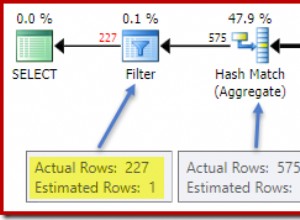
За целите на оптимизация, добро правило е да се присъедините по-малко, а не повече. Всъщност трябва да се опитате да присъедините възможно най-малко редове с възможно най-малко редове. С всяко допълнително присъединяване ще умножите разходите, вместо да добавяте цена. Защото mysql по същество просто ще генерира голяма умножена матрица. Много от това обаче се оптимизира от индекси и други неща.
Но за да отговоря на въпроса ви:всъщност е възможно да се брои само с едно голямо присъединяване, като приемем, че масите имат уникални ключове и idalb е уникален ключ за албум. След това и само тогава можете да го направите подобно на вашия код:
select alb.titreAlb as "Titre",
count(distinct payalb.idAlb, payalb.PrimaryKeyFields) "Pays",
count(distinct peralb.idAlb, peralb.PrimaryKeyFields) "Personnages",
count(distinct juralb.idAlb, juralb.PrimaryKeyFields) "Jurons"
from album alb
left join pays_album payalb using ( idAlb )
left join pers_album peralb using ( idAlb )
left join juron_album juralb using ( idAlb )
where alb.titreAlb = "LES CIGARES DU PHARAON"
group by alb.titreAlb
където PrimaryKeyFields означава полетата с първичен ключ на обединените таблици (трябва да ги потърсите).
Distinct ще премахне ефекта, който другите присъединявания имат върху броя. Но за съжаление, като цяло, distinct няма да премахне ефекта, който обединяванията имат върху цената.
Въпреки че, ако имате индекси, които покриват всички (idAlb + PrimaryKeyFields) полета на вашите таблици, това може да е също толкова бързо, колкото оригиналното решение (защото може да оптимизира distinct за да не правите сортиране) и ще се доближите до това, за което сте мислили (просто да преминете през всяка таблица/индекс веднъж). Но в нормален или най-лош случай сценарий, той трябва да работи по-лошо от разумно решение (като това на SlimGhost) - защото е съмнително, че ще намери оптималната стратегия. Но си поиграйте с него и проверете обясненията (и публикувайте констатациите), може би mysql ще направи нещо лудо.