Ако никога не сте имали канали в приложените полета, можете да го направите от контролния файл. Ако можете да имате както тръби, така и двойни кавички в едно поле, тогава мисля, че нямате друг избор, освен да обработите предварително файловете, за съжаление.
Вашето решение [1], за замяна на двойни кавички с SQL оператор , се случва твърде късно, за да бъде полезно; разделителите и загражденията вече са интерпретирани от SQL*Loader, преди да изпълни SQL стъпката. Вашето решение [2], за да игнорирате ограждането, ще работи в комбинация с [1] - докато едно от полетата не съдържаше черта. И решение [3] има същите проблеми като използването на [1] и/или [2] глобално.
Документацията за указване на разделители споменава, че:
С други думи, ако сте повторили двойните кавички вътре полетата, тогава те ще бъдат екранирани и ще се появят в данните на таблицата. Тъй като не можете да контролирате генерирането на данни, можете да обработите предварително получените файлове, за да замените всички двойни кавички с екранирани двойни кавички. Освен че не искате да замените всички от тях - тези, които всъщност са истински заграждения, не трябва да се избягват.
Можете да използвате регулярен израз, за да насочите съответните знаци, като пропуснете други. Не е силната ми област, но мисля, че можете да направите това с твърждения за поглед напред и назад .
Ако имате файл, наречен orig.txt съдържащ:
"1"|A|"B"|"C|D"
"2"|A|"B"|"C"D"
3|A|""B""|"C|D"
4|A|"B"|"C"D|E"F"G|H""
можете да направите:
perl -pe 's/(?<!^)(?<!\|)"(?!\|)(?!$)/""/g' orig.txt > new.txt
Това търси двойни кавички, които не са предшествани от начален ред или черта; и не е последвано от тръбна черта или анкер в края на линията; и замества само тези с екранирани (удвоени) двойни кавички. Което би направило new.txt съдържа:
"1"|A|"B"|"C|D"
"2"|A|"B"|"C""D"
3|A|"""B"""|"C|D"
4|A|"B"|"C""D|E""F""G|H"""
Двойните кавички в началото и края на полетата не се променят, но тези в средата вече са екранирани. Ако след това сте го заредили с контролен файл с двойни кавички:
load data
truncate
into table t42
fields terminated by '|' optionally enclosed by '"'
(
col1,
col2,
col3,
col4
)
Тогава ще завършите с:
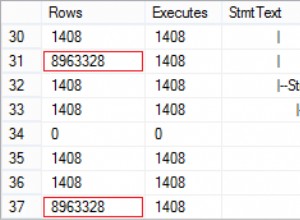
select * from t42 order by col1;
COL1 COL2 COL3 COL4
---------- ---------- ---------- --------------------
1 A B C|D
2 A B C"D
3 A "B" C|D
3 A B C"D|E"F"G|H"
което се надяваме да съвпадне с вашите оригинални данни. Възможно е да има крайни случаи, които не работят (като двоен кавичка, последван от тръба в поле), но има ограничение за това, което можете да направите, за да се опитате да интерпретирате нечии други данни... Разбира се, може да има (много) по-добри модели на регулярни изрази.
Можете също така да обмислите използването на външна таблица вместо SQL*Loader, ако файлът с данни е (или може да бъде) в директория на Oracle и имате правилните разрешения. Все още трябва да промените файла, но можете да го направите автоматично с preprocessor
директива, вместо да е необходимо да правите това изрично, преди да извикате SQL*Loader.