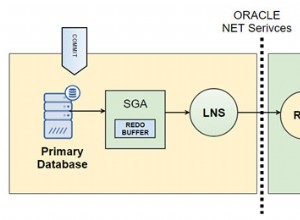
Хеш клъстерите могат да предоставят O(1) време за достъп, но не и O(1) време за налагане на ограничения. На практика обаче постоянното време за достъп на хеш клъстер е по-лошо от O(log N) времето за достъп на обикновен индекс на b-дърво. Освен това клъстерите са по-трудни за конфигуриране и не се мащабират добре за някои операции.
Създаване на хеш клъстер
drop table orders_cluster;
drop cluster cluster1;
create cluster cluster1
(
MerchantID number,
TransactionID varchar2(20)
)
single table hashkeys 10000; --This number is important, choose wisely!
create table orders_cluster
(
id number,
MerchantID number,
TransactionID varchar2(20)
) cluster cluster1(merchantid, transactionid);
--Add 1 million rows. 20 seconds.
begin
for i in 1 .. 10 loop
insert into orders_cluster
select rownum + i * 100000, mod(level, 100)+ i * 100000, level
from dual connect by level <= 100000;
commit;
end loop;
end;
/
create unique index orders_cluster_idx on orders_cluster(merchantid, transactionid);
begin
dbms_stats.gather_table_stats(user, 'ORDERS_CLUSTER');
end;
/
Създаване на обикновена таблица (за сравнение)
drop table orders_table;
create table orders_table
(
id number,
MerchantID number,
TransactionID varchar2(20)
) nologging;
--Add 1 million rows. 2 seconds.
begin
for i in 1 .. 10 loop
insert into orders_table
select rownum + i * 100000, mod(level, 100)+ i * 100000, level
from dual connect by level <= 100000;
commit;
end loop;
end;
/
create unique index orders_table_idx on orders_table(merchantid, transactionid);
begin
dbms_stats.gather_table_stats(user, 'ORDERS_TABLE');
end;
/
Пример за проследяване
SQL*Plus Autotrace е бърз начин за намиране на плана за обяснение и проследяване на I/O активността на израз. Броят на I/O заявките е означен като "последователно получава" и е приличен начин за измерване на количеството свършена работа. Този код демонстрира как са генерирани числата за други секции. Заявките често трябва да се изпълняват повече от веднъж, за да се затоплят нещата.
SQL> set autotrace on;
SQL> select * from orders_cluster where merchantid = 100001 and transactionid = '2';
no rows selected
Execution Plan
----------------------------------------------------------
Plan hash value: 621801084
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 16 | 1 (0)| 00:00:01 |
|* 1 | TABLE ACCESS HASH| ORDERS_CLUSTER | 1 | 16 | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("MERCHANTID"=100001 AND "TRANSACTIONID"='2')
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
31 consistent gets
0 physical reads
0 redo size
485 bytes sent via SQL*Net to client
540 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
SQL>
Намерете оптимални хеш ключове, компромиси
За оптимална производителност при четене всички хеш колизии трябва да се поберат в един блок (всички I/O на Oracle се извършват на блок, обикновено 8K). Получаването на правилното идеално хранилище е трудно и изисква познаване на хеш алгоритъма, размера на хранилището (не е същият като размера на блока) и броя на хеш ключовете (кофите). Oracle има алгоритъм и размер по подразбиране, така че е възможно да се фокусирате само върху един атрибут, броя на хеш ключовете.
Повече хеш ключове водят до по-малко сблъсъци. Това е добре за ефективността на TABLE ACCESS HASH, тъй като има само един блок за четене. По-долу е броят на последователните получавания за различни размери на хеш ключовете. За сравнение е включен и достъп до индекс. При достатъчно хеш ключове броят на блоковете намалява до оптималния брой, 1.
Method Consistent Gets (for transactionid = 1, 20, 300, 4000, and 50000)
Index 4, 3, 3, 3, 3
Hashkeys 100 1, 31, 31, 31, 31
Hashkeys 1000 1, 3, 4, 4, 4
Hashkeys 10000 1, 1, 1, 1, 1
Повече хеш ключове също водят до повече кофи, повече загубено пространство и по-бавна операция TABLE ACCESS FULL.
Table type Space in MB
HeapTable 24MB
Hashkeys 100 26MB
hashkeys 1000 30MB
hashkeys 10000 81MB
За да възпроизведа моите резултати, използвайте примерна заявка като select * from orders_cluster where merchantid = 100001 and transactionid = '1'; и променете последната стойност на 1, 20, 300, 4000 и 50000.
Сравнение на производителността
Постоянните резултати са предвидими и лесни за измерване, но в края на деня само времето на стенния часовник има значение. Изненадващо, достъпът до индекс с 4 пъти по-последователни получавания е все още по-бърз от оптималния сценарий на хеш клъстера.
--3.5 seconds for b-tree access.
declare
v_count number;
begin
for i in 1 .. 100000 loop
select count(*)
into v_count
from orders_table
where merchantid = 100000 and transactionid = '1';
end loop;
end;
/
--3.8 seconds for hash cluster access.
declare
v_count number;
begin
for i in 1 .. 100000 loop
select count(*)
into v_count
from orders_cluster
where merchantid = 100000 and transactionid = '1';
end loop;
end;
/
Опитах и теста с променливи предикати, но резултатите бяха подобни.
Мащабира ли се?
Не, хеш клъстерите не се мащабират. Въпреки времевата сложност O(1) на TABLE ACCESS HASH и O(log n) времевата сложност на INDEX UNIQUE SCAN, хеш клъстерите никога не изглежда да превъзхождат индексите на b-дърво.
Опитах горния примерен код с 10 милиона реда. Хеш клъстерът беше болезнено бавен за зареждане и все още не представяше индекса при производителност на SELECT. Опитах се да го мащабирам до 100 милиона реда, но вмъкването щеше да отнеме 11 дни.
Добрата новина е, че б*дърветата се мащабират добре. Добавянето на 100 милиона реда към горния пример изисква само 3 нива в индекса. Разгледах всички DBA_INDEXES за среда с голяма база данни (стотици бази данни и петабайт данни) - най-лошият индекс имаше само 7 нива. И това беше патологичен индекс на VARCHAR2(4000) колони. В повечето случаи индексите на вашето b-дърво ще останат плитки, независимо от размера на таблицата.
В този случай O(log n) бие O(1).
Но ЗАЩО?
Лошата производителност на хеш клъстера може би е жертва на опита на Oracle да опрости нещата и да скрие необходимите детайли, за да може хеш клъстерът да работи добре. Клъстерите са трудни за настройка и използване правилно и рядко биха осигурили значителна полза така или иначе. През последните няколко десетилетия Oracle не е положил много усилия в тях.
Коментаторите са прави, че прост индекс на b-дърво е най-добрият. Но не е очевидно защо това трябва да е вярно и е добре да помислим за алгоритмите, използвани в базата данни.