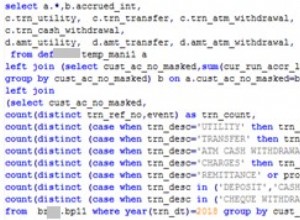
Нека имаме някои интересни данни с верижни дубликати на различни атрибути:
CREATE TABLE data ( ID, A, B, C ) AS
SELECT 1, 1, 1, 1 FROM DUAL UNION ALL -- Related to #2 on column A
SELECT 2, 1, 2, 2 FROM DUAL UNION ALL -- Related to #1 on column A, #3 on B & C, #5 on C
SELECT 3, 2, 2, 2 FROM DUAL UNION ALL -- Related to #2 on columns B & C, #5 on C
SELECT 4, 3, 3, 3 FROM DUAL UNION ALL -- Related to #5 on column A
SELECT 5, 3, 4, 2 FROM DUAL UNION ALL -- Related to #2 and #3 on column C, #4 on A
SELECT 6, 5, 5, 5 FROM DUAL; -- Unrelated
Сега можем да получим някои релации с помощта на аналитични функции (без никакви обединения):
SELECT d.*,
LEAST(
FIRST_VALUE( id ) OVER ( PARTITION BY a ORDER BY id ),
FIRST_VALUE( id ) OVER ( PARTITION BY b ORDER BY id ),
FIRST_VALUE( id ) OVER ( PARTITION BY c ORDER BY id )
) AS duplicate_of
FROM data d;
Което дава:
ID A B C DUPLICATE_OF
-- - - - ------------
1 1 1 1 1
2 1 2 2 1
3 2 2 2 2
4 3 3 3 4
5 3 4 2 2
6 5 5 5 6
Но това не разбира, че #4 е свързано с #5, което е свързано с #2 и след това с #1...
Това може да се намери с йерархична заявка:
SELECT id, a, b, c,
CONNECT_BY_ROOT( id ) AS duplicate_of
FROM data
CONNECT BY NOCYCLE ( PRIOR a = a OR PRIOR b = b OR PRIOR c = c );
Но това ще даде много, много дублиращи се редове (тъй като не знае откъде да започне йерархията, така че ще избере всеки ред на свой ред като корен) - вместо това можете да използвате първата заявка, за да дадете на йерархичната заявка начална точка, когато ID и DUPLICATE_OF стойностите са еднакви:
SELECT id, a, b, c,
CONNECT_BY_ROOT( id ) AS duplicate_of
FROM (
SELECT d.*,
LEAST(
FIRST_VALUE( id ) OVER ( PARTITION BY a ORDER BY id ),
FIRST_VALUE( id ) OVER ( PARTITION BY b ORDER BY id ),
FIRST_VALUE( id ) OVER ( PARTITION BY c ORDER BY id )
) AS duplicate_of
FROM data d
)
START WITH id = duplicate_of
CONNECT BY NOCYCLE ( PRIOR a = a OR PRIOR b = b OR PRIOR c = c );
Което дава:
ID A B C DUPLICATE_OF
-- - - - ------------
1 1 1 1 1
2 1 2 2 1
3 2 2 2 1
4 3 3 3 1
5 3 4 2 1
1 1 1 1 4
2 1 2 2 4
3 2 2 2 4
4 3 3 3 4
5 3 4 2 4
6 5 5 5 6
Все още има някои редове, които се дублират поради локалните минимуми в търсенето, което се появява #4 ... което може да бъде премахнато с просто GROUP BY :
SELECT id, a, b, c,
MIN( duplicate_of ) AS duplicate_of
FROM (
SELECT id, a, b, c,
CONNECT_BY_ROOT( id ) AS duplicate_of
FROM (
SELECT d.*,
LEAST(
FIRST_VALUE( id ) OVER ( PARTITION BY a ORDER BY id ),
FIRST_VALUE( id ) OVER ( PARTITION BY b ORDER BY id ),
FIRST_VALUE( id ) OVER ( PARTITION BY c ORDER BY id )
) AS duplicate_of
FROM data d
)
START WITH id = duplicate_of
CONNECT BY NOCYCLE ( PRIOR a = a OR PRIOR b = b OR PRIOR c = c )
)
GROUP BY id, a, b, c;
Което дава резултата:
ID A B C DUPLICATE_OF
-- - - - ------------
1 1 1 1 1
2 1 2 2 1
3 2 2 2 1
4 3 3 3 1
5 3 4 2 1
6 5 5 5 6